L'avenir de la gestion des données : Un facilitateur du développement de l'IA ? Une illustration basique avec RAG, des standards ouverts et des contrats de données
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
Contexte
Lors d’un meetup récent que j’ai organisé dans ma ville natale de Lille, j’ai eu le plaisir d’accueillir Jean-Georges Perrin, qui a fourni une introduction complète aux contrats de données. En tant que geek, je me suis senti obligé de tester ce concept pour en saisir pleinement les implications pratiques.
L’objectif de cet article est de démontrer comment les contrats de données peuvent être appliqués et apporter de la valeur au sein d’un petit écosystème confronté à des défis inter-domaines.
Pour illustrer, j’utiliserai mon expérience personnelle dans les domaines dans lesquels je travaille, qui peuvent être catégorisés en deux domaines distincts :
- Stratégie
- Ingénierie
Le cas d’utilisation peut être résumé ainsi : comment l’établissement d’un contrat de données autour du contenu d’un livre peut servir de catalyseur pour un produit d’IA dans un domaine différent.
Tout au long de cet article, je fournirai des exemples concrets et des solutions technologiques que vous, en tant que lecteur, pourrez tester et mettre en œuvre. La structure de cet article est divisée en trois parties. La première partie couvre les définitions et les outils qui seront utilisés tout au long de l’article. Les parties restantes représentent chacune un domaine distinct :
- La première partie est un domaine aligné sur la source : un club de lecture qui génère des données selon ses besoins spécifiques.
- La seconde partie est un domaine aligné sur le consommateur : un laboratoire GenAI qui consomme ces données et fournit une représentation sémantique adaptée à l’utilisation par un produit de données.
Bien que cet aperçu soit intrigant (sinon, je suppose que vous ne liriez pas ce message car vous auriez déjà fermé la page), je comprends qu’il puisse sembler peu clair. Plongeons-nous dedans et voyons si nous pouvons le clarifier avec un exemple !
Avertissement : Cet article est un peu long et aurait probablement pu être divisé en deux ou trois articles distincts. De plus, il contient des extraits de code. N’hésitez pas à sauter des sections si nécessaire.
Définitions et outillage
Introduction aux contrats de données
Dans le monde de la gestion des données, un contrat de données est une représentation formelle des données dans un format standard, lisible par machine. Il permet aux humains et aux ordinateurs de comprendre les capacités d’un ensemble de données sans accéder à sa structure, sa documentation ou par l’inspection de sa base de données.
Caractéristiques clés d’un contrat de données :
- Standardisation : Il fournit une manière standardisée de décrire la structure de l’ensemble de données.
- Documentation lisible par machine : Les outils peuvent utiliser la définition du contrat de données pour générer une documentation interactive des données, des SDK clients dans divers langages de programmation, ou des requêtes à partir d’outils de base de données compatibles.
- Fournit une auto-documentation : Le contrat lui-même sert de source de vérité pour ses capacités, ce qui peut améliorer l’expérience du développeur en fournissant une documentation intégrée et toujours à jour.
Les contrats de données servent de garantie, assurant que les données répondent à des critères spécifiques avant d’être consommées, augmentant ainsi la fiabilité et la confiance dans les processus axés sur les données.
Standards ouverts et introduction à Bitol
Les standards ouverts sont cruciaux pour l’interopérabilité et l’évolutivité des systèmes hétérogènes. Ils garantissent que les données peuvent être partagées et utilisées de manière transparente entre différentes plateformes et organisations.
Dans l’écosystème des données, Bitol offre un cadre pour créer et maintenir des contrats de données. J’utiliserai leur schéma version 2.2.2, qui est la dernière version au moment de la rédaction.
Le standard propose un schéma (exprimé en JSONSchema), et le contrat peut être écrit en YAML.
Beaucoup de gens croient que les deux formats sont adaptés aux humains et aux machines. Je ne pense pas. Par conséquent, j’utiliserai un outil intermédiaire pour écrire et valider les contrats avec lesquels je travaillerai : CUE.
Mes outils pour jouer
Validation des contrats de données avec CUE (Cuelang)
CUE (Configuration, Unification, and Execution) est un langage conçu pour définir, générer et valider des données. Il excelle dans la création de contrats de données car il peut appliquer efficacement des schémas et des règles de validation. En utilisant CUE, vous pouvez spécifier des contrats de données clairement et de manière concise, et assurer automatiquement la conformité à ces contrats.
CUE s’intègre parfaitement avec YAML et JSONSchema, rendant son utilisation simple et transparente.
La première étape consiste à importer le schéma du contrat et à le traduire en CUE :
❯ curl -O -s https://raw.githubusercontent.com/bitol-io/open-data-contract-standard/main/schema/odcs-json-schema-v2.2.2.json
❯ cue import odcs-json-schema-v2.2.2.jsonCela génère un fichier odcs-json-schema-v2.2.2.cue qui ressemble à ceci :
// Open Data Contract Standard (OCDS)
//
// An open data contract specification to establish agreement
// between data producers and consumers.
@jsonschema(schema="https://json-schema.org/draft/2019-09/schema")
// Current version of the data contract.
version: string
// The kind of file this is. Valid value is `DataContract`.
kind: "DataContract" | *"DataContract"
// Version of the standard used to build data contract. Default
// value is v2.2.2.
apiVersion?: =~"^v[0-9]+\\.[0-9]+\\.[0-9]+" | *"v2.2.2"
...Je peux alors simplement valider un fichier. Validons l’exemple dans le dépôt Bitol :
❯ curl -O -s https://raw.githubusercontent.com/bitol-io/open-data-contract-standard/main/docs/examples/all/full-example.yaml
❯ cue vet full-example.yaml odcs-json-schema-v2.2.2.cue && echo ok || echo ko
okPour vérifier que cela fonctionne, supprimons un champ obligatoire (datasetName) de l’exemple :
❯ grep -v datasetName full-example.yaml > incomplete-example.yaml
❯ cue vet incomplete-example.yaml odcs-json-schema-v2.2.2.cue
datasetName: incomplete value string:
./odcs-json-schema-v2.2.2.cue:113:14Passons au cas d’utilisation proprement dit.
Première partie : le domaine de données aligné sur la source
Le cas d’utilisation : nous sommes un club de lecture dans le domaine de la connaissance
Dans cette section, nous explorerons le domaine de la “connaissance”, en nous concentrant spécifiquement sur la gestion de la littérature technique. Imaginez un club de lecture dédié à la discussion de divers livres, où l’une de leurs principales activités est de décomposer ces livres en sections plus petites et plus gérables. Ces sections sont conçues pour être suffisamment concises pour faciliter des discussions approfondies lors de leurs réunions. Une fois ces sections préparées, elles sont exportées dans un format convivial pour le lecteur, comme HTML.
Pour des raisons de simplicité et pour rendre cela tangible, nous utiliserons le livre de Simon Wardley comme exemple.
Découper le livre
Considérons que chaque section de chaque chapitre du livre est autonome. Notre tâche sera d’extraire ces sections et de les convertir au format markdown, qui servira de format pivot. Nous stockerons ensuite les données dans un fichier parquet sur un serveur HTTP.
Remarque : Dans un scénario d’entreprise, vous envisageriez probablement de mettre en œuvre une plateforme pour le stockage des données. Cette plateforme offrirait des capacités de recherche et d’extraction avancées pour répondre aux besoins de diverses parties prenantes.
J’utilise un fichier parquet pour émuler une base de données appropriée. Je suppose que nous pourrions utiliser un stockage d’objets brut, mais, pour l’instant, la spécification du contrat de données impose un ensemble de données basé sur des tables.
Note à propos de la définition #Dataset dans bitol
Tout ne se range pas facilement en lignes et colonnes, mais aujourd’hui, la norme de contrat de données repose fortement sur les tables et les colonnes pour ses descriptions. C’est l’une des raisons pour lesquelles j’ai choisi d’encapsuler les données dans un fichier Parquet pour cet exercice. Il pourra probablement évoluer plus tard pour gérer directement le stockage d’objets.
En attendant, dans les grandes entreprises, cela peut ne pas être un problème, car une plateforme peut facilement fournir la capacité d’exposer n’importe quelles données à travers une abstraction de table.
Voici une représentation de ce que nous construisons :
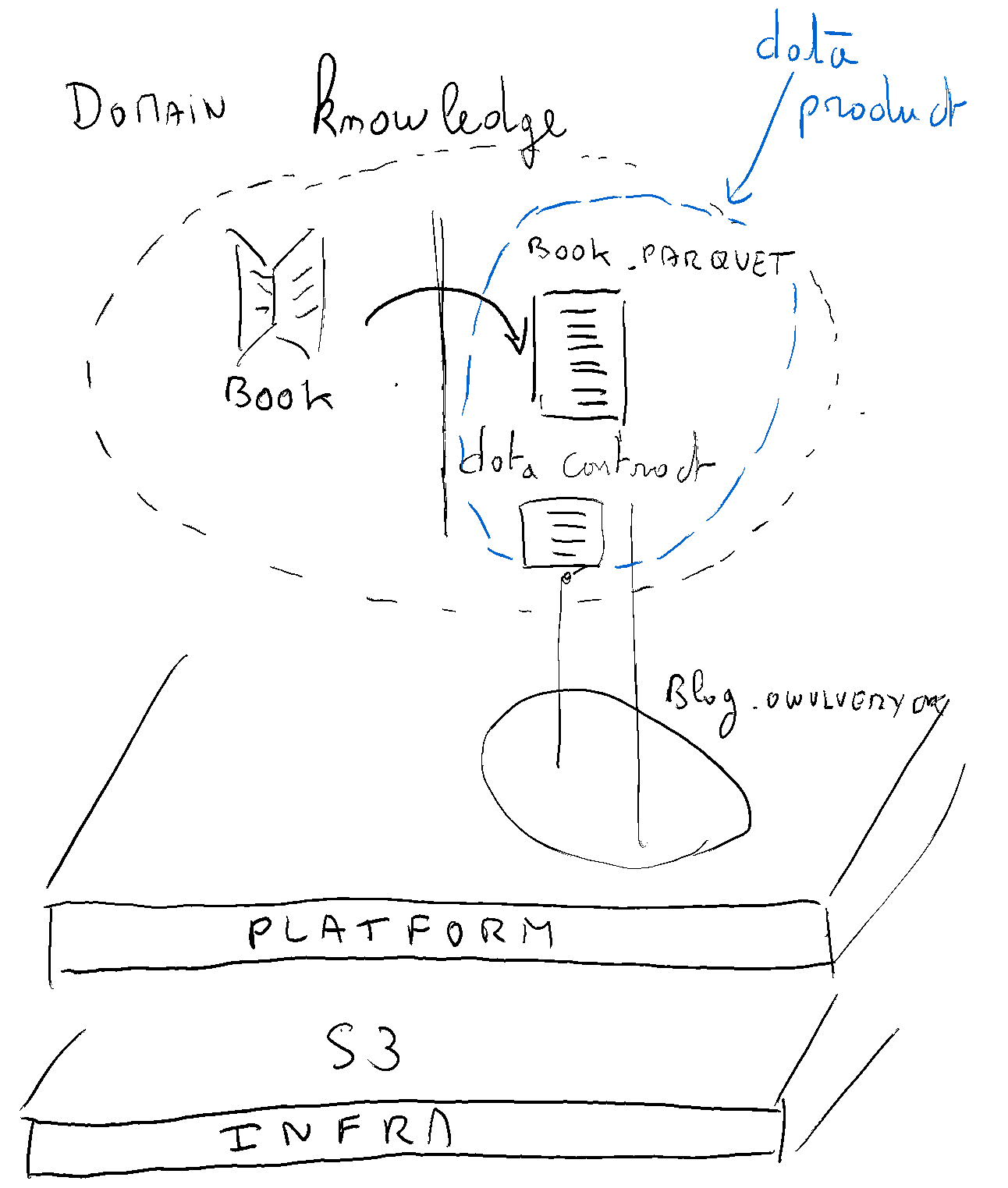
Mise en œuvre du contrat
Plongeons maintenant dans la définition du contrat :
// What's this data contract about?
datasetDomain: "knowledge" // Domain
quantumName: "Wardley Book" // Data product name
userConsumptionMode: "operational"
version: "1.0.0" // Version (follows semantic versioning)
status: "test"
uuid: "53581432-6c55-4ba2-a65f-72344a91553a"
// Lots of information
description: {
purpose: "Provide chunks of the book of Simon Wardley"
limitations: "Those chunks have references of the images which are not embedded with this dataset"
}
// Getting support
productDl: "wardley-map@myorg.com"
sourcePlatform: "owulveryck's blog"
project: "The ultimate strategy book club"
datasetName: "wardley_book"
kind: "DataContract"
apiVersion: "v2.2.2" // Standard version (follows semantic versioning, previously known as templateVersion)
type: "objects"
// Physical access
driver: "httpfs:parquet"
driverVersion: "1.0.0"
database: "https://blog.owulveryck.info/assets/sampledata" // Bucket name
// Dataset, schema and quality
dataset: [{
table: "wardleyBook.parquet" // the object name
description: "The book from simon wardley, chunked by sections"
authoritativeDefinitions: [{
url: "https://blog.owulveryck.info/2024/06/12/the-future-of-data-management-an-enabler-to-ai-devlopment-a-basic-illustration-with-rag-open-standards-and-data-contracts.html"
type: "explanation"
}]
dataGranularity: "Chunking according to sections"
columns: [{
column: "chapter_number"
logicalType: "int"
physicalType: "INT32"
}, {
column: "section_number"
logicalType: "int"
physicalType: "INT32"
isNullable: false
}, {
column: "chapter_title"
logicalType: "string"
physicalType: "BYTE_ARRAY"
}, {
column: "section_title"
logicalType: "string"
physicalType: "BYTE_ARRAY"
}, {
column: "content"
businessName: "The content of the section"
logicalType: "string"
physicalType: "BYTE_ARRAY"
description: "The content of the section in Markdown"
}]
}]Le contrat a été créé manuellement. Cependant, comme j’ai un code qui génère le fichier Parquet, je peux envisager un processus d’automatisation qui générerait la description du jeu de données. Je discuterai du processus d’automatisation plus en détail plus tard dans cet article.
Nous pouvons valider le contrat et le convertir en YAML (pour répondre aux exigences standard) :
cue vet wardleyBook.cue ~/open-data-contract-standard/schema/odcs-json-schema-v2.2.2.cue
cue export --out yaml wardleyBook.cue > wardleyBook.yamlCe qui donne :
datasetDomain: knowledge
quantumName: Wardley Book
userConsumptionMode: operational
version: 1.0.0
status: test
uuid: 53581432-6c55-4ba2-a65f-72344a91553a
description:
purpose: Provide chunks of the book of Simon Wardley
limitations: Those chunks have references of the images which are not embedded with this dataset
productDl: wardley-map@myorg.com
sourcePlatform: owulveryck's blog
project: The ultimate strategy book club
datasetName: wardley_book
kind: DataContract
apiVersion: v2.2.2
type: objects
driver: httpfs:parquet
driverVersion: 1.0.0
database: https://blog.owulveryck.info/assets/sampledata
dataset:
- table: wardleyBook.parquet
description: The book from simon wardley, chunked by sections
authoritativeDefinitions:
- url: https://blog.owulveryck.info/2024/06/12/the-future-of-data-management-an-enabler-to-ai-devlopment-a-basic-illustration-with-rag-open-standards-and-data-contracts.html
type: explanation
dataGranularity: Chunking according to sections
columns:
- column: chapter_number
logicalType: int
physicalType: INT32
- column: section_number
logicalType: int
physicalType: INT32
isNullable: false
- column: chapter_title
logicalType: string
physicalType: BYTE_ARRAY
- column: section_title
logicalType: string
physicalType: BYTE_ARRAY
- column: content
businessName: The content of the section
logicalType: string
physicalType: BYTE_ARRAY
description: The content of the section in MarkdownUtilisation du contrat
Voyons si la définition du contrat est suffisante pour accéder correctement aux données.
- Je sais que le pilote est
httpfs:parquet - J’ai l’adresse de la base de données :
https://blog.owulveryck.info/assets/sampledata - J’ai le “nom de la table” (mon fichier parquet) :
wardleyBook.parquet
Je peux maintenant essayer d’accéder aux données avec duckDB par exemple (qui peut lire les fichiers parquet et accéder au stockage httpfs) :
> duckdb
v0.9.2 3c695d7ba9
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D INSTALL httpfs;
D LOAD httpfs;
D SELECT * FROM "https://blog.owulveryck.info/assets/sampledata/wardley_book/wardleyBook.parquet" LIMIT 2;
┌────────────────┬────────────────┬───────────────┬──────────────────────┬─────────────────────────────────────────────────────────────────────────────┐
│ chapter_number │ section_number │ chapter_title │ section_title │ content │
│ int32 │ int32 │ blob │ blob │ blob │
├────────────────┼────────────────┼───────────────┼──────────────────────┼─────────────────────────────────────────────────────────────────────────────┤
│ 1 │ 1 │ On being lost │ Serendipity │ By chance, I had picked up a copy of the \x22Art of War\x22 by Sun Tzu. T… │
│ 1 │ 2 │ On being lost │ The importance of … │ It was about this time that I read the story of Ball\x27s Bluff. It is no… │
└────────────────┴────────────────┴───────────────┴──────────────────────┴─────────────────────────────────────────────────────────────────────────────┘Il est hors de portée de cet article d’écrire un script pour extraire le contenu et le transformer en fichier html, mais vous comprenez le principe.
Deuxième partie : le domaine de données aligné sur le consommateur
Maintenant, quittons le domaine de la connaissance pour entrer dans le domaine GenAI.
Le cas d’utilisation : RAG-Time
Dans cette section, nous plongerons dans le domaine “GenAI”, où l’accent est mis sur la création d’un outil de Génération Augmentée par Récupération (RAG) qui nous permet d’interroger efficacement un livre. Comme mentionné dans mon précédent article1, un outil RAG exploite à la fois des mécanismes de récupération et l’IA générative pour fournir des réponses contextuelles et précises à partir d’une source textuelle donnée.
Création d’une représentation sémantique
Pour construire cet outil RAG, nous devons créer une représentation sémantique du livre. Cela implique de calculer des embeddings pour chaque section du livre. Ces embeddings sont des représentations numériques qui capturent le sens sémantique du texte, permettant une recherche et une récupération efficaces en réponse aux requêtes.
Nous utiliserons le produit de données exposé depuis le domaine “connaissance”, qui contient les données du livre dans un format structuré. Notre objectif est de créer un nouveau produit de données avec trois colonnes : un ID, le contenu au format markdown et l’embedding correspondant.
Contrat de données pour les embeddings
Il est crucial de noter que le calcul des embeddings dépend de l’algorithme. Par conséquent, notre contrat de données devrait spécifier l’algorithme utilisé pour générer ces embeddings. Cela garantit que différents algorithmes peuvent être pris en compte, et que plusieurs produits de données peuvent être fournis selon les algorithmes d’embedding utilisés.
Voici le contrat de données :
// What's this data contract about?
datasetDomain: "GenAI" // Domain
quantumName: "Wardley Book" // Data product name
userConsumptionMode: "operational"
version: "1.0.0" // Version (follows semantic versioning)
status: "test"
uuid: "63581432-6c55-4ba2-a65f-72344a91553b"
// Lots of information
description: {
purpose: "Views built on top of the seller tables."
limitations: "Data based on seller perspective, no buyer information"
usage: "Predict sales over time"
}
// Getting support
productDl: "genai@myorg.com"
sourcePlatform: "owulveryck's blog"
project: "Engineering in the ear of GenAI"
datasetName: "wardley_book"
kind: "DataContract"
apiVersion: "v2.2.2" // Standard version (follows semantic versioning, previously known as templateVersion)
type: "objects"
// Physical access
driver: "httpfs:zip"
driverVersion: "1.0.0"
database: "https://blog.owulveryck.info/assets/sampledata/chroma.zip"
// Dataset, schema and quality
dataset: [{
table: "wardley_content_embeddings" // the collection
description: "The book from simon wardley, chunked by sections with a semantic representation computed with mxbai-embed-large"
authoritativeDefinitions: [{
url: "https://blog.owulveryck.info/2024/06/12/the-future-of-data-management-an-enabler-to-ai-devlopment-a-basic-illustration-with-rag-open-standards-and-data-contracts.html"
type: "explanation"
},{
url: "https://gist.github.com/owulveryck/dcf3de4e0ad82ab99bf116828112eacd#file-chromageneration-py"
type: "code"
}]
dataGranularity: "Each embedding is computing according to sections or the original dataset at https://blog.owulveryck.info/assets/sampledata/wardleyBook.cue"
columns: [{
column: "id"
logicalType: "string"
physicalType: "string"
},{
column: "embeddings"
businessName: "The embedding value"
logicalType: "string"
physicalType: "string"
description: "The embedding computed with mxbai-embed-large"
},{
column: "documents"
businessName: "The value of the document"
logicalType: "string"
physicalType: "string"
description: "The embedding computed with mxbai-embed-large"
}]
}]Comme documenté dans le contrat de données, vous pouvez trouver le code utilisé pour générer la chromadb dans ce Gist.
Jouer avec les données
En supposant que vous avez une instance d’Ollama installée localement, vous pouvez maintenant expérimenter avec un RAG (Génération Augmentée par Récupération). J’ai créé un petit script Python qui interroge Ollama en demandant :
quelles sont les sources d’inertie ?
Et voici la réponse :
> python query2.py
According to the text, the sources of inertia mentioned are:
1. **Loss aversion bias**: The value of losing an object exceeds the value of acquiring it, often leading to a reluctance to change or abandon an existing asset.
2. **Disposition bias**: A desire not to lose value, which can lead to resisting selling assets that have declined in value, hoping they will recover.
3. **Instrumentation bias**: A reliance on known tools or approaches to the exclusion of other methods, making it difficult to consider alternative solutions.
These biases and tendencies contribute to inertia by:
* Fostering a fear of loss or change
* Encouraging the preservation of existing assets or investments
* Limiting consideration of alternative approaches or solutions
By recognizing these sources of inertia, individuals can better understand why they may be resistant to change and make more informed decisions about their actions.Et tout cela peut être fait sans enquêter sur la structure d’aucun des documents grâce aux contrats de données.
Vers le datamesh
Voici un croquis de ce que nous avons construit :
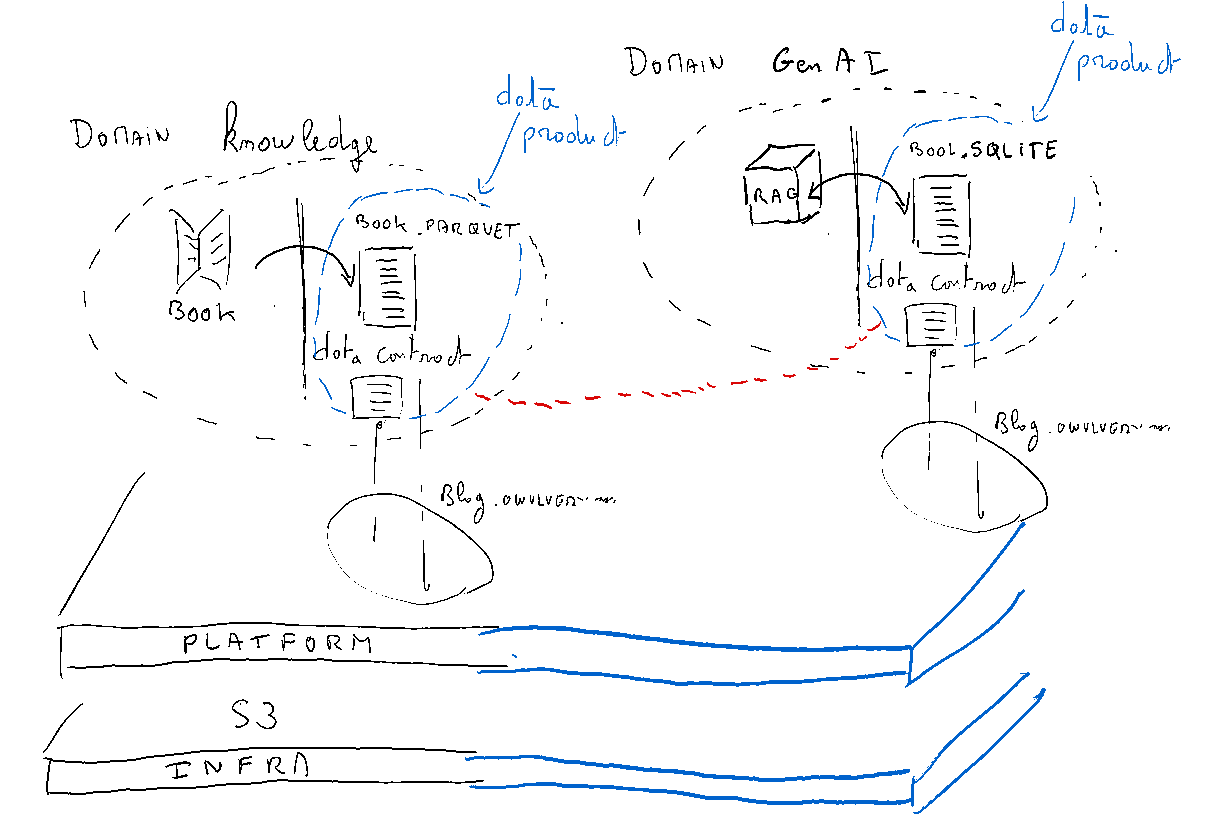
Il semble que les prémisses d’un data mesh soient en train de s’établir (à l’échelle de l’entreprise, nous pourrions créer de plus en plus de liens interconnectés).
Tout cela est basé sur l’idée que chaque domaine publiera un contrat de données pour ses données. Concluons cet article en explorant quelques considérations sur la façon de faciliter la mise en œuvre du contrat de données.
Application ou facilitation : le rôle de la gouvernance
Nous avons vu que le contrat de données est un facilitateur puissant pour soutenir les cas d’utilisation basés sur les données.
Mais comment pouvons-nous garantir que toutes les données sont exposées en tant que produit avec leurs contrats correspondants ?
Des contraintes draconiennes ?
J’ai fait un post LinkedIn intitulé À quoi ressemblerait le mandat API de Jeff Bezos s’il était appliqué aux données ?
Voici une copie du post :
En 2002, le fondateur d’Amazon, Jeff Bezos, a envoyé une note à son personnel pour imposer l’utilisation des API. Cette note comprenait une série de points imposant des contraintes sur les échanges numériques entre les services numériques.
Je pense sincèrement que cet e-mail a joué un rôle majeur dans la révolution numérique des années 2010. En fait, l’évolution du nombre de services augmentait l’entropie et la complexité des systèmes. Comme l’a expliqué Dave Snowden, imposer des contraintes draconiennes est un moyen de faire face au chaos. (Dans cet exemple, cela évite que la complexité ne se transforme en chaos). J’ai récemment posté quelque chose à ce sujet.
Le paysage actuel des données s’inspire beaucoup des méthodes et des processus qui ont fait le succès de la révolution numérique.
Le contrat de données est probablement l’un de ces actifs émergents qui sera non seulement un facilitateur pour atteindre le plein potentiel des données, mais aussi une ligne directrice pour aborder la complexité du paysage des données au sein et en dehors de l’entreprise.
Pour s’amuser, imaginons à quoi pourrait ressembler le mandat API de Bezos appliqué aux données :
- Toutes les équipes exposeront désormais leurs données par le biais de contrats.
- Les équipes doivent échanger des données entre elles selon ces contrats.
- Aucune autre forme d’échange de données ne sera autorisée : pas de lectures directes du stockage de données d’une autre équipe, pas de modèle de mémoire partagée, pas d’ETL ou d’ELT spécifique. Le seul échange autorisé se fait via la description du contrat sur la plateforme de données.
- Peu importe la technologie qu’ils utilisent. Stockage d’objets, séries temporelles, relationnel, protocoles personnalisés — peu importe.
- Tous les contrats de données, sans exception, doivent être conçus dès le départ pour être externalisables. C’est-à-dire que l’équipe doit planifier et concevoir pour pouvoir exposer les données aux consommateurs dans le monde extérieur. Pas d’exceptions.
- Quiconque ne le fait pas sera licencié.
- Merci ; passez une bonne journée !
Établir ces contraintes établira les données comme un actif utilisable dans un espace de marché concurrentiel. Tout le monde pourra consommer les données (sous réserve de politiques spécifiques de gestion des accès). De plus, tout le monde pourra exposer des données similaires, augmentant l’offre. Les données avec le meilleur niveau de service attireront plus de demande et seront plus largement utilisées.
En mettant en œuvre ces contraintes, les organisations peuvent favoriser un marché de données plus efficace et compétitif, où des données de haute qualité sont accessibles et précieuses pour toutes les parties prenantes. Cette approche favorise non seulement la transparence et l’utilisabilité des données, mais stimule également l’innovation et l’amélioration des services de données.
L’idée derrière cela est d’imposer des contraintes strictes pour garantir que toutes les données sont accessibles via des contrats de données. Cette approche s’est avérée efficace pour les API dans le monde numérique, mais c’est une solution radicale qui peut ne pas convenir dans tous les contextes.
N’hésitez pas à consulter les commentaires sur le post LinkedIn pour vous faire votre propre opinion.
La gouvernance computationnelle comme facilitateur
Nous avons discuté un peu de ce petit data-mesh, mais nous avons à peine abordé la gouvernance.
Si nous remplaçons gouvernance des données par facilitation des données, nous pouvons envisager son rôle comme facilitant la mise en place d’échanges de données.
Le data-mesh introduit le concept de gouvernance computationnelle. Dans notre contexte, les règles de gouvernance pourraient exiger l’exposition d’un contrat de données. Cependant, dans l’esprit du calcul, la gouvernance pourrait également fournir des outils pour générer et maintenir automatiquement ces contrats de données. Au début de l’article, nous avons mentionné que les contrats de données devraient être gérables à la fois par les humains et les machines.
Fournir des outils pour automatiser la génération de contrats de données inciterait les producteurs de données, car cela offrirait une vue unifiée de leurs données, partagée à la fois au sein et en dehors du domaine.
Ainsi, la gouvernance deviendrait véritablement un facilitateur.
Conclusion
Tout au long de cet article, nous avons exploré l’utilisation de base d’un contrat de données. Cependant, plusieurs aspects n’ont pas été couverts, comme les sections sur l’accord de niveau de service (SLA) et d’autres détails importants.
De plus, nous n’avons pas abordé la sécurité des données, qui devrait être gérée par des règles de gouvernance et appliquée par les capacités d’une plateforme.
Alors, comment commencer ? Envisagez de mettre en œuvre un contrat de données sur des données qui sont précieuses à la fois pour votre domaine et pour les autres. Ensuite, évaluez les exigences en matière de sécurité et d’hébergement, et commencez à définir les règles de gouvernance potentielles.
Merci d’avoir lu jusqu’ici ;)