The Future of Data Management: An Enabler of AI Development? A Basic Illustration with RAG, Open Standards, and Data Contracts
Context
In a recent meetup I organized in my hometown of Lille, I had the pleasure of hosting Jean-Georges Perrin, who provided a comprehensive introduction to data contracts. As a geek, I felt compelled to test this concept to fully grasp its practical implications.
The goal of this article is to demonstrate how data contracts can be applied to and add value within a small ecosystem facing cross-domain challenges.
To illustrate, I will use my personal experience in the fields I work in, which can be categorized into two separate domains:
- Strategy
- Engineering
The use case can be summarized as: how establishing a data contract around the content of a book can serve as a catalyst for an AI product in a different domain.
Throughout this article, I will provide concrete examples and technological solutions that you, as a reader, can test and implement. The structure of this article is divided into three parts. The first part covers definitions and the tools that will be used throughout the article. The remaining parts each represent a distinct domain:
- The first part is a source-aligned domain: a book club that generates data according to its specific needs.
- The second part is a consumer-aligned domain: a GenAI lab that consumes this data and provides a semantic representation suitable for use by a data product.
While this overview is intriguing (otherwise, I guess you wouldn’t be reading this message because you would have already closed the page), I understand that it might seem unclear. Let’s dive in and see if we can clarify it with an example!
Disclaimer: This article is a bit lengthy and could probably have been divided into two or three separate articles. Additionally, it contains code excerpts. Feel free to skip any sections as needed.
Definitions and tooling
Introduction to Data Contracts
In the world of data management, a data contract is a formal representation of a data ins a standard, machine-readable format. It allows both humans and computers to understand the capabilities of a dataset without accessing its structure, documentation, or through its database inspection.
Key Features of a data contract:
- Standardization: It provides a standardized way to describe the structure of the data-set.
- Machine-readable Documentation: Tools can use the data contract definition to generate interactive data-documentation documentation, client SDKs in various programming languages, or queries from compatibles database tools.
- Provides Self-Documentation: The contract itself serves as a source of truth for its capabilities, which can enhance developer experience by providing integrated and always up-to-date documentation.
Data contracts serve as a safeguard, ensuring that data meets specific criteria before being consumed, thereby increasing the reliability and trustworthiness of data-driven processes.
Open Standards and Introduction to Bitol
Open standards are crucial for the interoperability and scalability of heterogeneous systems. They ensure that data can be seamlessly shared and utilized across different platforms and organizations.
In the data ecosystem, Bitol offers a framework for creating and maintaining data contracts. I will be using their schema version 2.2.2, which is the latest version at the time of writing.
The standard proposes a schema (expressed in JSONSchema), and the contract can be written in YAML.
Many folks believe that both formats are suitable for humans and machines. I don’t. Therefore, I will use a tool-in-the-middle to write and validate the contracts I will work with: CUE.
My tooling for playing
Validating Data Contracts with CUE (Cuelang)
CUE (Configuration, Unification, and Execution) is a language designed for defining, generating, and validating data. It excels in creating data contracts because it can enforce schema and validation rules effectively. By using CUE, you can specify data contracts clearly and concisely, and ensure compliance with these contracts automatically.
CUE integrates seamlessly with YAML and JSONSchema, making its usage straightforward and transparent.
The first step is to import the schema of the contract and translate it in CUE:
❯ curl -O -s https://raw.githubusercontent.com/bitol-io/open-data-contract-standard/main/schema/odcs-json-schema-v2.2.2.json
❯ cue import odcs-json-schema-v2.2.2.jsonThis generates a file odcs-json-schema-v2.2.2.cue that looks like this:
// Open Data Contract Standard (OCDS)
//
// An open data contract specification to establish agreement
// between data producers and consumers.
@jsonschema(schema="https://json-schema.org/draft/2019-09/schema")
// Current version of the data contract.
version: string
// The kind of file this is. Valid value is `DataContract`.
kind: "DataContract" | *"DataContract"
// Version of the standard used to build data contract. Default
// value is v2.2.2.
apiVersion?: =~"^v[0-9]+\\.[0-9]+\\.[0-9]+" | *"v2.2.2"
...I can then simply validate a file. Let’s validate the example in the Bitol repository:
❯ curl -O -s https://raw.githubusercontent.com/bitol-io/open-data-contract-standard/main/docs/examples/all/full-example.yaml
❯ cue vet full-example.yaml odcs-json-schema-v2.2.2.cue && echo ok || echo ko
okTo validate that it works, let’s remove a mandatory field (datasetName) from the example:
❯ grep -v datasetName full-example.yaml > incomplete-example.yaml
❯ cue vet incomplete-example.yaml odcs-json-schema-v2.2.2.cue
datasetName: incomplete value string:
./odcs-json-schema-v2.2.2.cue:113:14Let’s move into the proper use-case.
First part: the source aligned data domain
The use case: we are a book club in the knowledge domain
In this section, we will explore the “knowledge” domain, specifically focusing on the management of technical literature. Imagine a book club dedicated to discussing various books, where one of their main activities is to break down these books into smaller, manageable sections. These sections are designed to be concise enough to facilitate in-depth discussions during their meetings. Once these sections are prepared, they are exported into a reader-friendly format, such as HTML.
For the sake of simplicity and to make this tangible, we will use Simon Wardley’s book as our example.
Slicing the book
Let’s consider that each section within each chapter of the book is self-contained. Our task will be to extract these sections and convert them into markdown format, which will act as our pivot format. We will then store the data in a parquet file on an HTTP server.
Note: In a corporate scenario, you would likely consider implementing a platform for data storage. This platform would offer advanced search and extraction capabilities to cater to the needs of various stakeholders.
I am using a parquet file to emulate a proper database. I guess that we could use a raw object storage, but, by now, the data contract specication imposes a table based dataset.
Side note about the #Dataset definition in bitol
Not everything fits neatly into rows and columns, but today, the data contract standard relies heavily on tables and columns for its descriptions. This is one of the reasons why I chose to encapsulate the data in a Parquet file for this exercise. It can likely evolve later to handle object storage directly.
In the meantime, in large businesses, this may not be an issue, as a platform can easily provide the capability to expose any data through a table abstraction.
Here is a representation of what we are building:
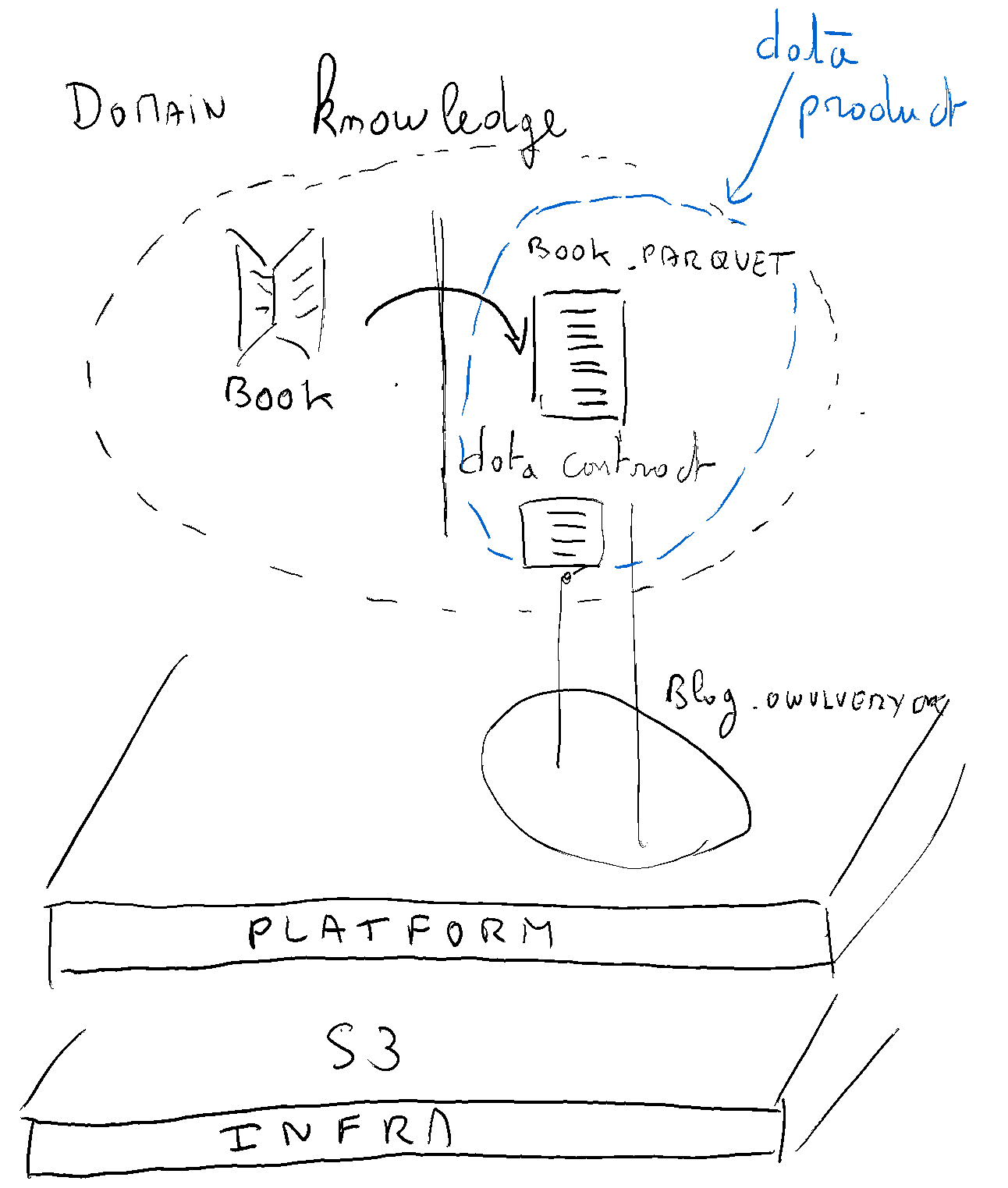
Implementing the contract
Now let’s dive into the definition of the contract:
// What's this data contract about?
datasetDomain: "knowledge" // Domain
quantumName: "Wardley Book" // Data product name
userConsumptionMode: "operational"
version: "1.0.0" // Version (follows semantic versioning)
status: "test"
uuid: "53581432-6c55-4ba2-a65f-72344a91553a"
// Lots of information
description: {
purpose: "Provide chunks of the book of Simon Wardley"
limitations: "Those chunks have references of the images which are not embedded with this dataset"
}
// Getting support
productDl: "wardley-map@myorg.com"
sourcePlatform: "owulveryck's blog"
project: "The ultimate strategy book club"
datasetName: "wardley_book"
kind: "DataContract"
apiVersion: "v2.2.2" // Standard version (follows semantic versioning, previously known as templateVersion)
type: "objects"
// Physical access
driver: "httpfs:parquet"
driverVersion: "1.0.0"
database: "https://blog.owulveryck.info/assets/sampledata" // Bucket name
// Dataset, schema and quality
dataset: [{
table: "wardleyBook.parquet" // the object name
description: "The book from simon wardley, chunked by sections"
authoritativeDefinitions: [{
url: "https://blog.owulveryck.info/2024/06/12/the-future-of-data-management-an-enabler-to-ai-devlopment-a-basic-illustration-with-rag-open-standards-and-data-contracts.html"
type: "explanation"
}]
dataGranularity: "Chunking according to sections"
columns: [{
column: "chapter_number"
logicalType: "int"
physicalType: "INT32"
}, {
column: "section_number"
logicalType: "int"
physicalType: "INT32"
isNullable: false
}, {
column: "chapter_title"
logicalType: "string"
physicalType: "BYTE_ARRAY"
}, {
column: "section_title"
logicalType: "string"
physicalType: "BYTE_ARRAY"
}, {
column: "content"
businessName: "The content of the section"
logicalType: "string"
physicalType: "BYTE_ARRAY"
description: "The content of the section in Markdown"
}]
}]The contract has been created manually. However, since I have a code that generates the Parquet file, I can envision an automation process that would generate the dataset description. I will discuss the automation process in more detail later in this post. Sure, here’s the enhanced version of your text:
We can validate the contract and convert it to YAML (to meet the standard requirements):
cue vet wardleyBook.cue ~/open-data-contract-standard/schema/odcs-json-schema-v2.2.2.cue
cue export --out yaml wardleyBook.cue > wardleyBook.yamlWhich gives:
datasetDomain: knowledge
quantumName: Wardley Book
userConsumptionMode: operational
version: 1.0.0
status: test
uuid: 53581432-6c55-4ba2-a65f-72344a91553a
description:
purpose: Provide chunks of the book of Simon Wardley
limitations: Those chunks have references of the images which are not embedded with this dataset
productDl: wardley-map@myorg.com
sourcePlatform: owulveryck's blog
project: The ultimate strategy book club
datasetName: wardley_book
kind: DataContract
apiVersion: v2.2.2
type: objects
driver: httpfs:parquet
driverVersion: 1.0.0
database: https://blog.owulveryck.info/assets/sampledata
dataset:
- table: wardleyBook.parquet
description: The book from simon wardley, chunked by sections
authoritativeDefinitions:
- url: https://blog.owulveryck.info/2024/06/12/the-future-of-data-management-an-enabler-to-ai-devlopment-a-basic-illustration-with-rag-open-standards-and-data-contracts.html
type: explanation
dataGranularity: Chunking according to sections
columns:
- column: chapter_number
logicalType: int
physicalType: INT32
- column: section_number
logicalType: int
physicalType: INT32
isNullable: false
- column: chapter_title
logicalType: string
physicalType: BYTE_ARRAY
- column: section_title
logicalType: string
physicalType: BYTE_ARRAY
- column: content
businessName: The content of the section
logicalType: string
physicalType: BYTE_ARRAY
description: The content of the section in MarkdownUsing the contract
Let’s see if the definition of the contract is sufficient to properly access the data.
- I know that the driver is
httpfs:parquet - I have the database address:
https://blog.owulveryck.info/assets/sampledata - I have the “table name” (my parquet file):
wardleyBook.parquet
I can now try to access the data with duckDB for example (which can read parquet files and access httpfs storage):
> duckdb
v0.9.2 3c695d7ba9
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D INSTALL httpfs;
D LOAD httpfs;
D SELECT * FROM "https://blog.owulveryck.info/assets/sampledata/wardley_book/wardleyBook.parquet" LIMIT 2;
┌────────────────┬────────────────┬───────────────┬──────────────────────┬─────────────────────────────────────────────────────────────────────────────┐
│ chapter_number │ section_number │ chapter_title │ section_title │ content │
│ int32 │ int32 │ blob │ blob │ blob │
├────────────────┼────────────────┼───────────────┼──────────────────────┼─────────────────────────────────────────────────────────────────────────────┤
│ 1 │ 1 │ On being lost │ Serendipity │ By chance, I had picked up a copy of the \x22Art of War\x22 by Sun Tzu. T… │
│ 1 │ 2 │ On being lost │ The importance of … │ It was about this time that I read the story of Ball\x27s Bluff. It is no… │
└────────────────┴────────────────┴───────────────┴──────────────────────┴─────────────────────────────────────────────────────────────────────────────┘It is beyond the scope of this article to write a script to extract the content and turn it into an html file, but you get the drill.
Second part: the consumer aligned data domain
Now, let’s leave the knowledge domain to enter the GenAI domain.
The use case: RAG-Time
In this section, we’ll dive into the “GenAI” domain, where the focus is on creating a Retrieval-Augmented Generation (RAG) tool that allows us to query a book effectively. As mentioned in my previous article1, a RAG tool leverages both retrieval mechanisms and generative AI to provide contextual and accurate answers from a given textual source.
Creating a Semantic Representation
To build this RAG tool, we need to create a semantic representation of the book. This involves computing embeddings for each section of the book. These embeddings are numerical representations that capture the semantic meaning of the text, enabling efficient search and retrieval in response to queries.
We will use the data-product exposed from the “knowledge” domain, which contains the book’s data in a structured format. Our aim is to create a new data-product with three columns: an ID, the content in markdown format, and the corresponding embedding.
Data Contract for Embeddings
It’s crucial to note that the computation of embeddings is algorithm-dependent. Therefore, our data contract should specify the algorithm used for generating these embeddings. This ensures that different algorithms can be accommodated, and multiple data products can be provided as per the embedding algorithms used.
Here is the data contract:
// What's this data contract about?
datasetDomain: "GenAI" // Domain
quantumName: "Wardley Book" // Data product name
userConsumptionMode: "operational"
version: "1.0.0" // Version (follows semantic versioning)
status: "test"
uuid: "63581432-6c55-4ba2-a65f-72344a91553b"
// Lots of information
description: {
purpose: "Views built on top of the seller tables."
limitations: "Data based on seller perspective, no buyer information"
usage: "Predict sales over time"
}
// Getting support
productDl: "genai@myorg.com"
sourcePlatform: "owulveryck's blog"
project: "Engineering in the ear of GenAI"
datasetName: "wardley_book"
kind: "DataContract"
apiVersion: "v2.2.2" // Standard version (follows semantic versioning, previously known as templateVersion)
type: "objects"
// Physical access
driver: "httpfs:zip"
driverVersion: "1.0.0"
database: "https://blog.owulveryck.info/assets/sampledata/chroma.zip"
// Dataset, schema and quality
dataset: [{
table: "wardley_content_embeddings" // the collection
description: "The book from simon wardley, chunked by sections with a semantic representation computed with mxbai-embed-large"
authoritativeDefinitions: [{
url: "https://blog.owulveryck.info/2024/06/12/the-future-of-data-management-an-enabler-to-ai-devlopment-a-basic-illustration-with-rag-open-standards-and-data-contracts.html"
type: "explanation"
},{
url: "https://gist.github.com/owulveryck/dcf3de4e0ad82ab99bf116828112eacd#file-chromageneration-py"
type: "code"
}]
dataGranularity: "Each embedding is computing according to sections or the original dataset at https://blog.owulveryck.info/assets/sampledata/wardleyBook.cue"
columns: [{
column: "id"
logicalType: "string"
physicalType: "string"
},{
column: "embeddings"
businessName: "The embedding value"
logicalType: "string"
physicalType: "string"
description: "The embedding computed with mxbai-embed-large"
},{
column: "documents"
businessName: "The value of the document"
logicalType: "string"
physicalType: "string"
description: "The embedding computed with mxbai-embed-large"
}]
}]As documented in the data-contract you can find the code used to generate the chromadb in this Gist.
Play along with the data
Assuming you have an instance of Ollama installed locally, you can now experiment with a RAG (Retrieval-Augmented Generation). I created a small Python script that queries Ollama by asking:
what are the sources of inertia?
And here is the answer:
> python query2.py
According to the text, the sources of inertia mentioned are:
1. **Loss aversion bias**: The value of losing an object exceeds the value of acquiring it, often leading to a reluctance to change or abandon an existing asset.
2. **Disposition bias**: A desire not to lose value, which can lead to resisting selling assets that have declined in value, hoping they will recover.
3. **Instrumentation bias**: A reliance on known tools or approaches to the exclusion of other methods, making it difficult to consider alternative solutions.
These biases and tendencies contribute to inertia by:
* Fostering a fear of loss or change
* Encouraging the preservation of existing assets or investments
* Limiting consideration of alternative approaches or solutions
By recognizing these sources of inertia, individuals can better understand why they may be resistant to change and make more informed decisions about their actions.And all of this can be done without investigating in the structure of any of the documents thanks to the data contracts.
Toward datamesh
Here is a doodle of what we’ve built:
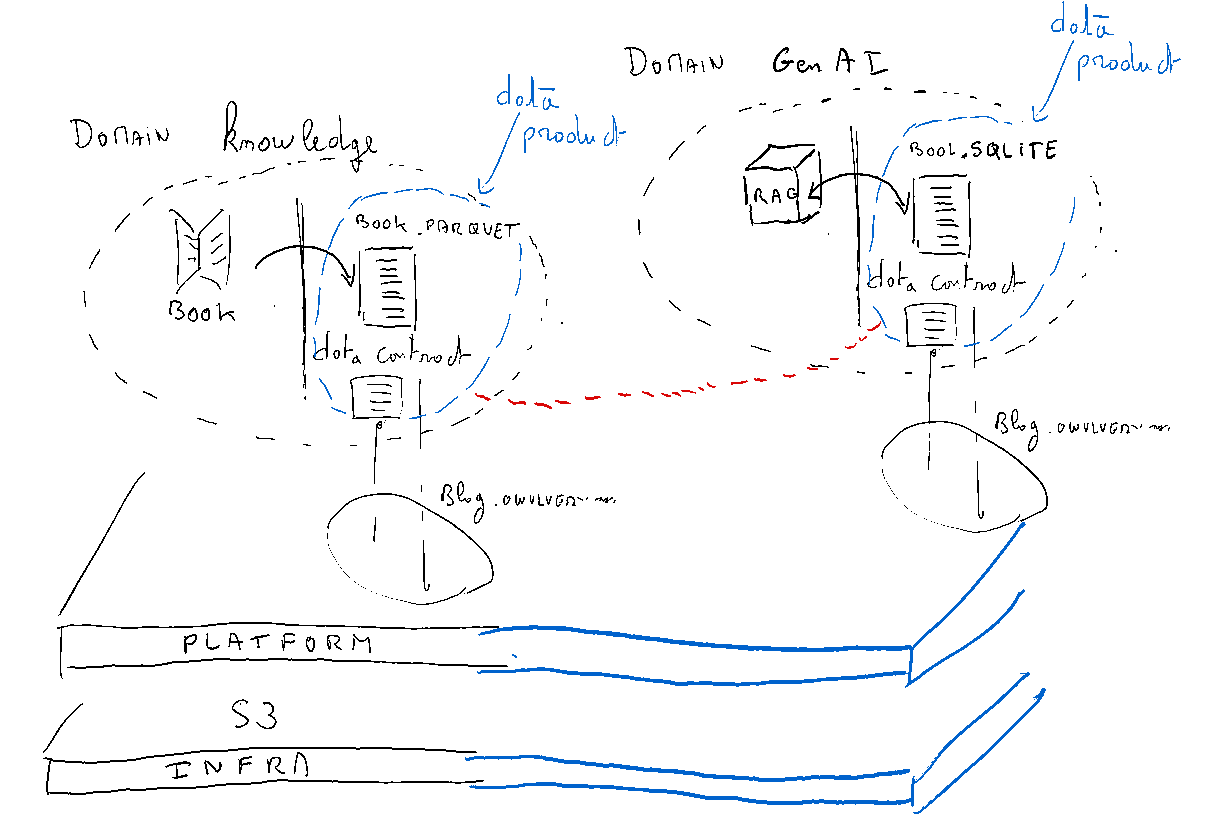
It appears that the premises of a data mesh are being established (at the company scale, we could create more and more interconnected links).
All of this is based on the idea that every domain will publish a data contract for their data. Let’s conclude this article by exploring a few considerations on how to facilitate the implementation of the data contract.
Enforcment or enablement: the role of the governance
We’ve seen that the data contract is a strong facilitator to support data-based use-casesSure, here’s the enhanced version of the text:
But how can we ensure that all data is exposed as a product with its corresponding contracts?
Draconian constaints ?
I made a LinkedIn post entitled What would the Jeff Bezos API Mandate look like if applied to data?
Here is a copy of the post:
In 2002, Amazon’s founder Jeff Bezos issued a memo to his staff to enforce the usage of APIs. This memo included a set of bullet points imposing constraints on digital exchanges between digital services.
I genuinely think that this email played a major role in the digital revolution of the 2010s. Actually, the evolution of the number of services was increasing the entropy and the complexity of the systems. As Dave Snowden explained, setting draconian constraints is a way to address chaos. (In this example, it avoids the complexity from turning into chaos). I recently post something about this.
The current data landscape takes a lot of inspiration from the methods and processes that made the digital revolution successful.
The data contract is probably one of those emerging assets that will not only be an enabler to reach the full potential of the data, but also a guideline to address the complexity of the data landscape within and outside of the company.
For fun, let’s imagine what the Bezos API Mandate could look like applied to data:
- All teams will henceforth expose their data through contracts.
- Teams must exchange data with each other according to these contracts.
- There will be no other form of data exchange allowed: no direct reads of another team’s data store, no shared-memory model, no specific ETL, ELT whatsoever. The only exchange allowed is via the desscription of the contract over the data platform.
- It doesn’t matter what technology they use. Object Storage, Time series, Relational, custom protocols — doesn’t matter.
- All data contracts, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the data to consumers in the outside world. No exceptions.
- Anyone who doesn’t do this will be fired.
- Thank you; have a nice day!
Setting those constraints will establish data as an asset usable in a competitive market space. Everyone will be able to consume the data (subject to specific access management policies). Additionally, everyone will be able to expose similar data, increasing the supply. The data with the best service level will attract more demand and be more widely used.
By implementing these constraints, organizations can foster a more efficient and competitive data marketplace, where high-quality data is accessible and valuable to all stakeholders. This approach not only promotes data transparency and usability but also drives innovation and improvement in data services.
The idea behind this is to impose strict constraints to ensure that all data is accessible via data contracts. This approach has proven effective for APIs in the digital world, but it is a radical solution that may not be suitable in all contexts.
Feel free to check the comments on the LinkedIn post to form your own opinion.
Computational Governance as an enabler
We’ve discussed this tiny data-mesh a bit, but we’ve barely touched on governance.
If we replace data governance with data enablement, we can envision its role as facilitating the setup of data exchange.
The data-mesh introduces the concept of computational governance. In our context, governance rules could mandate the exposure of a data contract. However, in the spirit of computation, governance could also provide tools to automatically generate and maintain these data contracts. At the beginning of the article, we mentioned that data contracts should be manageable by both humans and machines.
Providing tools to automate the generation of data contracts would incentivize data producers, as it would offer a unified view of their data, shared both within and outside the domain.
Thus, governance would truly become an enabler.
Conclusion
Throughout this article, we have explored the basic usage of a data contract. However, several aspects were not covered, such as sections on the Service Level Agreement (SLA) and other important details.
Additionally, we did not address data security, which should be managed by governance rules and enforced through the capabilities of a platform.
So, how do you start? Consider implementing a data contract on data that is valuable to both your domain and others. Next, assess the requirements for security and hosting, and begin outlining potential governance rules.
Thank you for reading up to this point ;)