Explorer les exaptations dans les pratiques d'ingénierie au sein d'une application basée sur RAG
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
Contexte
Dans cet article, j’explorerai le concept de RAG, mais pas de manière conventionnelle. Mon objectif est essentiellement de créer un RAG depuis le début pour le considérer comme un problème purement d’ingénierie.
Partir de zéro me permettra de :
- potentiellement découvrir une forme d’exaptation qui peut informer mes décisions en tant qu’ingénieur et me guider dans une direction spécifique.
- clarifier les points de confusion que je pourrais avoir dans la compréhension du système.
Remarque : L’approche à partir de zéro est difficile car la génération de l’embedding est liée au modèle et à la tokenisation, mais considérons-la comme à partir de zéro pour la partie Ingénierie, ce qui sera suffisant pour moi.
Comme point de départ, j’ai utilisé les informations de cet article car il est clair et écrit en Go, et je maîtrise ce langage. Je n’ai pas d’informations supplémentaires à offrir au-delà de l’article original sur la partie technique (l’auteur a fait un excellent travail).
Par conséquent, il ne s’agit pas d’un article sur Go, mais vraiment d’un article sur l’ingénierie informatique.
Dans cet article, je décrirai la méthode étape par étape que j’ai utilisée pour écrire un RAG simple (et ni efficace ni effectif), mais je noterai également les découvertes qui pourraient être utiles pour mon travail de consultant et d’ingénieur.
Organisation de l’article et du code
- La première section traite de l’acquisition des données, en soulignant l’importance de préparer les données pour qu’elles soient facilement utilisables par un modèle de langage (LLM).
- La section suivante implique la transformation des données en une représentation mathématique qui facilite la recherche. Les résultats sont stockés dans une base de données qui sera utilisée par l’application.
- La dernière section concerne l’application elle-même : elle interprétera une question, identifiera le segment de données pertinent dans la base de données et interrogera le LLM.
- Le document se termine par un résumé et des suggestions sur la façon de convertir cette preuve de concept (POC) en une solution sur mesure.
La séquence du programme est à peu près la suivante :

Le cas d’utilisation
Dans la section d’introduction, j’ai esquissé le résultat attendu que je vise. Ce résultat tourne autour de la découverte des réponses partielles à la question : “Quel est le rôle de l’ingénierie dans la mise en place d’une application alimentée par l’IA”. Pour orienter efficacement mes actions vers cet objectif, j’ai besoin d’un cas d’utilisation. Ce cas d’utilisation doit avoir une sortie clairement définie qui signifie la conclusion de cette expérience.
Voici la description détaillée du cas d’utilisation :
Je fouille fréquemment dans des livres que je considère comme des documents de “référence”, tels que “team topologies”, “DDD” et autres. Une telle référence dans laquelle je suis actuellement plongé est “the value flywheel effect”.
Ce livre perspicace non seulement discute de stratégie, mais offre également des conseils sur la façon d’appliquer la théorie de Simon Wardley. Il décrit une large gamme de cas d’utilisation, comme comment utiliser les cartes dans une conversation avec un PDG, ou comment cartographier une solution technologique.
Dans le domaine des missions de conseil, la cartographie s’avère être un outil inestimable. Ce livre est une mine d’informations cruciales pour maximiser l’efficacité de ces outils.
À titre d’illustration, j’ai compilé une liste de questions qui peuvent fonctionner comme un cadre d’entretien lors d’une mission de conseil.
Mon objectif actuel est d’interagir dans une “conversation” avec mon assistant virtuel, en posant des questions particulières et en obtenant des réponses fondées sur le livre.
Pour y parvenir, j’utiliserai une stratégie RAG : Récupérer le contenu correspondant à ma requête, Augmenter l’invite avec les informations récupérées, puis permettre au LLM de Générer la réponse.
Première étape : Acquisition des données
La première étape dans la création d’un RAG consiste à rassembler les données nécessaires et à effectuer un nettoyage approfondi.
Collecte de données
Pour expérimenter avec le RAG, j’ai besoin de données, ou dans ce cas, d’un livre. Pour The Value Flywheel Effect, j’ai acheté le livre.
Cependant, il y a un premier obstacle à surmonter : la nécessité d’obtenir les droits d’utilisation des données. Le simple fait de posséder le livre ne me donne pas la liberté de manipuler son contenu. Cela est dû aux restrictions de licence du livre qui interdisent de telles actions. Pour l’instant, pour vérifier la viabilité du projet, j’utiliserai un livre différent.
Ce livre alternatif est sous une licence creative commons, déjà formaté, et c’est une œuvre que je connais bien. De plus, il est pertinent pour le sujet : c’est le livre de Simon Wardley.
Première leçon (évidente) : Avoir accès aux données est un avantage significatif. J’en ai toujours été conscient, mais cette expérience souligne vraiment son importance.
Nettoyage des données
Le livre de Simon Wardley a été converti dans de nombreux formats. Ce dépôt fournit une version en asciidoc.
Le texte sera introduit dans le LLM, qui est un modèle de Langage. Par conséquent, il est crucial d’aider le LLM à identifier le composant principal du texte - le contenu, et d’éliminer toutes les distractions conçues pour aider le lecteur humain, comme le centrage ou la taille de la police. Cependant, nous ne souhaitons pas supprimer la structure et la segmentation du texte, qui servent d’indicateurs importants et de diviseurs du contenu.
Dans ce scénario, Markdown s’avère exceptionnellement utile. La syntaxe est suffisamment simple et consomme peu de tokens, évitant ainsi de créer du bruit pour le système.
Un peu d’“asciidoc” et de “pandoc”, et voilà : quelques fichiers de contenu markdown.
Deuxième leçon : J’ai eu de la chance car quelqu’un avait déjà fait le travail de conversion dans un format “numériquement exploitable”. Cette étape peut être longue et relève de l’ingénierie des données.
Deuxième étape : création de l’embedding
C’est une partie qui relève également de l’ingénierie. Cette partie visera à convertir des morceaux de texte en représentation numérique (un tableau de nombres, un vecteur). Ce processus est appelé embedding (ou word embedding).
Un algorithme est utilisé pour convertir un ensemble de tokens (approximativement des morceaux de mots) en vecteurs. Comme vu précédemment, cet algorithme est lié au modèle que nous utiliserons. En termes simples, le programme appellera une API OpenAI pour chaque morceau qui retournera le vecteur correspondant. Ce vecteur est ensuite stocké dans la base de données.
Mais comment découper le texte ? Devons-nous le découper en parties de taille fixe ? Devons-nous le découper par chapitres ? Paragraphes ? Cela dépend ! Il n’y a pas d’approche universelle. Pour clarifier, faisons un pas en arrière et esquissons les concepts de base.
Le flux de travail que je vais utiliser est basé sur une question que je poserai à mon moteur. La première étape consiste à comprendre la question et, en fonction de son contexte, à identifier une section du document qui pourrait contenir la réponse.
Le processus d’embedding traduit le texte en un “vecteur”. Nous utilisons ensuite des outils mathématiques pour identifier des vecteurs similaires. Ces vecteurs similaires traitent probablement du même contexte. Par conséquent, il est essentiel de segmenter précisément le texte en sections pour créer des vecteurs pertinents et significatifs.
Prenons cette phrase comme exemple :
“En été, nos jardins débordent de menthe parfumée, parfaite pour rehausser notre sauce maison”.
Disons que j’ai un vecteur représentant la “cuisine” qui est vertical, et un autre vecteur représentant le “jardinage”. La phrase entière penchera davantage vers la cuisine que vers le jardinage. Cependant, si je divise la phrase en deux parties à peu près égales, j’aurai un segment étroitement lié au jardinage, et un segment non essentiel, étroitement lié à la cuisine.
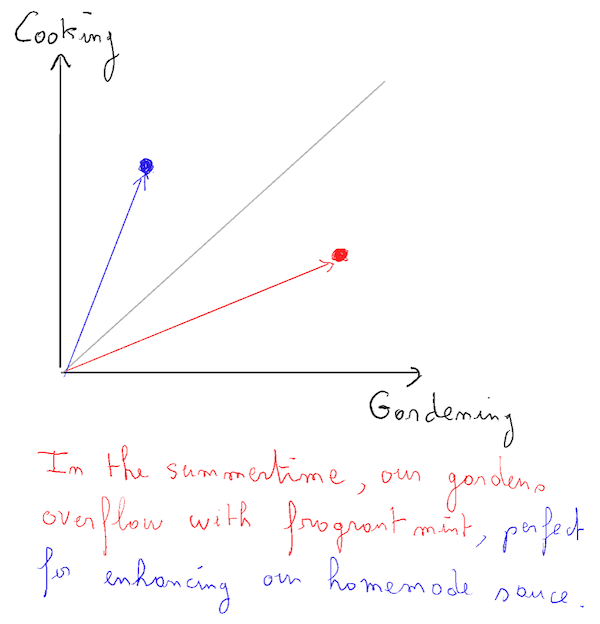
Troisième leçon (évidente) : Une expertise “métier” peut être nécessaire pour analyser les données et atteindre une efficacité maximale dans l’application.
Pour les besoins de ce test, je diviserai les données en segments égaux de x mots. Cela pourrait être suffisant pour la validation de ma preuve de concept.
J’exécute le code exactement comme décrit dans l’article de blog original. Ce processus segmentera le texte, invoquera l’API d’embedding OpenAI pour chaque segment, et stockera ensuite le résultat dans une base de données relationnelle SQLite.
Exaptation possible : J’obtiens finalement une base de données SQLite qui encapsule le livre de Wardley dans un modèle mathématique compatible avec OpenAI. Si je possède plusieurs livres, j’ai l’option soit d’étendre cette base de données, soit d’établir des bases de données séparées pour chaque livre. L’aspect intrigant est que la base de données SQLite sert de base de connaissances autonome qui peut être utilisée avec l’API OpenAI. Cela ouvre la possibilité d’écrire n’importe quel code supplémentaire qui exploite cette base de données dans n’importe quel langage, séparant le “processus de construction” du “processus d’exécution”.
Dernière étape : inférence
L’inférence forme le cœur de mon application. Le processus commence lorsque je saisis une question. L’application fouille alors ma base de données pour trouver le morceau qui s’aligne avec le contexte de la question. Ces informations sont ensuite transmises à OpenAI, qui génère une réponse.

Dans ce scénario, il n’y a pas de base vectorielle, et le processus de recherche est simple :
- D’abord, nous calculons l’embedding de la question. Cela se fait par un appel API, similaire à la façon dont nous calculons l’embedding des morceaux.
- Ensuite, nous effectuons un calcul de similarité cosinus pour chaque élément de la base de données.
- Nous sélectionnons ensuite le meilleur résultat, celui qui est le plus pertinent pour la question.
- Enfin, nous envoyons ce résultat au moteur LLM via API en mode invite, ainsi que la question originale.
Calcul de similarité : identifier le segment pertinent
Si l’ensemble de données d’entrée s’élargit (par exemple, si j’utilise la même base de données pour plusieurs livres), une approche plus efficace pour calculer la similarité deviendra nécessaire. C’est là que la puissance d’une base de données vectorielle brille.
Actuellement, le calcul de similarité est exécuté manuellement dans une grande boucle en utilisant un algorithme de calcul de similarité basique. Cependant, si le volume de données devient trop important (par exemple, si je vise à indexer une bibliothèque entière), cette méthode s’avérera inefficace. À ce stade, nous passerons à une approche vectorielle.
Ce système vectoriel identifiera le “voisin” le plus approprié. Reste à voir quels algorithmes ils emploient. Toutes les bases vectorielles donnent-elles le même résultat ? C’est un aspect fascinant que je crois mérite une exploration plus approfondie dans mon rôle de consultant.
Quatrième leçon : Évitez la sur-ingénierie ou la complication de votre pile technologique, surtout dans la phase de genèse/POC. Concentrez-vous plutôt sur la résolution de votre problème spécifique. Recherchez l’expertise de spécialistes lorsque c’est nécessaire pour l’évolutivité (lors de l’entrée dans l’étape II de l’évolution : l’artisanat).
Créons le prompt
L’étape finale consiste à construire une invite en utilisant les informations extraites, qui sera ensuite envoyée au LLM. Dans mon scénario spécifique, cela implique de faire un appel à l’API OpenAI.
Ci-dessous se trouve la structure de base de l’invite qui est codée en dur dans le programme.
Le placeholder %v sera remplacé par le segment de texte approprié et la question correspondante :
Use the below information to answer the subsequent question.
Information:
%v
Question: %vQuatrième apprentissage : Nous entrons dans l’ingénierie de prompt, je peux remplacer ma question codée en dur par quelque chose comme :
Use the below information to answer the subsequent question and add the origin.
Origin:
chapter %v
Information:
%v
Question: %vPour ce faire, je dois ensuite compléter ma base de données initiale en ajoutant pour chaque morceau sa source (chapitre). Cela nécessite une petite réflexion sur son cas d’utilisation en amont.
Couplage base de données et prompt
En réalité, la base de données comprend deux tables :
chunksembeddings
La table chunks a actuellement 4 colonnes :
idpath- le chemin du fichier source (dans mon caschapter[1-9].md)nchunk- le numéro du morceau dans la segmentation (principalement pour le débogage)content- le contenu du morceau
La table embedding contient :
idembeddingau format “blob”
Les informations du prompt doivent être cohérentes avec les informations de la base de données (spécialement dans la table “chunks”). Dans l’espace exploratoire en mode POC, ce n’est pas un problème, mais entrer dans la phase II nécessitera un peu de pensée produit et de conception en amont du code.
Résultats, découvertes et partie amusante
En compilant le programme, je peux interroger ma base de connaissances :
❯ ./rag -db=../../data/db/wardley.db -answer "give me examples of inertia" 2>/dev/null
1. Resistance to change in business due to past success and uncertainty in co-evolving practices.
2. Consumer concerns about disruption to past norms, transition to the new, and the agency of the new when adopting cloud computing.
3. Suppliers' inertia to change due to past financial success, internal resistance, and external market expectations.
4. Financial markets' inertia towards stability and past results.
5. Cultural inertia caused by past success in fulfilling a business model.
6. Resistance to change caused by cutting costs in response to declining revenue in a changing industry.
7. Inertia in reacting to disruptive changes in the market, such as the shift from products to utility services in computing.
8. Inertia in transitioning from custom-built solutions to product offerings.
9. Resistance to change in response to disruptive changes in various industries, leading to companies' demise.
10. Failure to adapt to predictable disruptions, such as the shift from products to utility services, leading to companies' downfall.Comme le moteur est le GPT-x language, je peux même lui demander en français, il gérera :
❯ ./rag -db=../../data/db/wardley.db -answer "donne moi tous les exemples d'inertie" 2>/dev/null
Les exemples d'inertie mentionnés dans le texte sont :
- "Perte de capital social" : résistance au changement due à des relations commerciales existantes avec des fournisseurs.
- "Peur, incertitude et doute" : tentative des fournisseurs de convaincre les équipes internes de ne pas adopter les nouveaux changements.
- "Perte de capital politique" : résistance au changement due à un manque de confiance envers la direction.
- "Barrières à l'entrée" : peur que le changement permette l'entrée de nouveaux concurrents.
- "Coût de l'acquisition de nouvelles compétences" : coût croissant de l'acquisition de nouvelles compétences en raison d'une demande accrue.
- "Adaptabilité" : préoccupations quant à la préparation du marché ou des clients au changement.Cinquième apprentissage : on observe ici que les résultats sont moins complets. C’est une aide, mais pas un moteur de recherche. L’idempotence s’arrête au moment de récupérer des informations de la base d’embedding. Ensuite, c’est YOLO :D
Conclusion et ouverture sur le couplage et l’architecture logicielle
J’ai créé avec succès deux actifs indépendants :
- Un binaire basé sur Go qui ne nécessite pas d’installation. Il est conçu pour interroger n’importe quelle base de connaissances dans son format spécifique.
- La base de connaissances elle-même :
wardley.db
À l’avenir, je peux travailler sur un livre différent, générer un embedding et le partager. Plus je le décompose en parties, plus la base deviendra précieuse, quel que soit le moteur d’inférence utilisé.
Enseignement clé : Le versionnage du programme n’est que faiblement lié à mes données. Cela me permet de nettoyer et d’alimenter les données indépendamment de l’ingénierie informatique. Je pourrais même être en mesure d’automatiser ce processus via un pipeline.
Cependant, il y a un risque à considérer : modifier la base de données pourrait potentiellement casser les requêtes SQL, et la même chose s’applique si je change le prompt.
Pour atténuer cela, j’ai deux options :
- Je pourrais versionner ma base de données en même temps que le code. Cela signifie que la version 1 du code ne serait compatible qu’avec la version 1 de la base de données.
- Alternativement, je pourrais extraire le modèle pour créer une abstraction. Cela entraînerait un fort couplage entre le modèle et la base de données, mais un couplage plus faible entre le code et la base de données. (Et bien sûr, si je change la base de données, j’aurai un autre problème à gérer, mais nous pouvons le gérer avec des adaptateurs).
Une approche intelligente pour gérer ce couplage est de traiter le prompt comme un actif séparé. Cela créerait une sorte d’architecture ports-et-adaptateurs où la communication est menée par le langage naturel. Amusant !