Ontologie, graphes et turtles - Partie II
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
Dans un article précédent, j’ai introduit la notion d’ontologie et de graphe de connaissances.
Approfondissons le concept et appliquons de la technologie pour créer une véritable structure de graphe et éventuellement jouer avec.
À la fin de cet article, nous aurons analysé un triplestore au format turtle et créé une structure de graphe en Go (basée sur l’interface de gonum)
Le triplestore
Comme expliqué dans le dernier article, notre base de données de connaissances est un triplestore. À titre d’exemple, je m’appuierai sur l’ontologie exposée par schema.org.
Schema.org est une activité collaborative communautaire avec pour mission de créer, maintenir et promouvoir des schémas pour les données structurées sur Internet, sur les pages web, dans les messages électroniques et au-delà. Fondé par Google, Microsoft, Yahoo et Yandex, les vocabulaires Schema.org sont développés par un processus communautaire ouvert […]. Vous pouvez obtenir l’ontologie complète avec cette commande :
La définition complète est disponible au format turtle et peut être téléchargée facilement :
curl -O -s https://schema.org/version/latest/schemaorg-current-http.ttlAnalyse du store
Explication de base de l’analyseur
Pour analyser le store, j’utilise le package gon3 d’Andrei Sambra. Bien qu’il n’y ait pas de licence attachée, Andrei m’a autorisé à l’utiliser et à le modifier pour du code non lucratif.
J’ai forké le dépôt pour faire quelques ajustements mineurs dont j’avais besoin pour mes expériences.
Le point d’entrée du package est une structure Parser. Son but est de lire un flux d’octets (io.Reader) et de le transformer en une structure fonctionnelle appelée Graph. La structure Graph dans le package ne représente pas tous les bords. Mais elle consiste en un tableau de Triples (aka graphe rdf) :
// An RDF graph is a set of RDF triples
type Graph struct {
triples []*Triple
uri *IRI
}Un Triple est une structure contenant trois Term. L’un est le sujet, l’un est un prédicat, et le dernier est l’objet.
// see http://www.w3.org/TR/rdf11-concepts/#dfn-rdf-triple
type Triple struct {
Subject, Predicate, Object Term
}Dans l’article précédent, nous avons vu qu’un terme en RDF peut être exprimé dans différents types. À ce jour, la façon de représenter des types génériques en Go est d’utiliser des interfaces. Par conséquent, un Term a une définition basée sur une interface :
type Term interface {
String() string
Equals(Term) bool
RawValue() string
}Deux objets importants implémentent l’interface Term :
- IRI
- Literal
Générer le graphe RDF
Si nous assemblons tous les concepts, nous avons la possibilité de créer une structure de base :
import "github.com/owulveryck/gon3" // Other imports omited for brevity
func main() {
baseURI := "https://example.org/foo"
parser := gon3.NewParser(baseURI)
gr, _ := parser.Parse(os.Stdin) // Error handling is omited for brevity
fmt.Printf("graph contains %v triples", len(gr.Triples()))
}Ensuite, nous pouvons tester la plomberie avec le fichier que nous avons précédemment téléchargé depuis schema.org :
> cat schemaorg-current-http.ttl| go run main.go
graph contains 15323 triplesNous pouvons vérifier grossièrement que le nombre de triplets correspond à ce qui est attendu en comptant les séparateurs rdf du fichier :
> cat schemaorg-current-http.ttl | egrep -v '^@|^$' | egrep -c ' \.$| \;$|\,$'
15329Les nombres ne sont pas identiques mais similaires (la commande grep n’évalue pas le littéral et certaines ponctuations peuvent être mal comptées)
Génération d’un graphe
Comprendre la structure du graphe
Nous avons un graphe “RDF” en mémoire ; malheureusement, cette structure n’est pas un graphe orienté. Je veux dire qu’il n’est pas de facto possible de naviguer de nœuds en nœuds ou d’identifier les arêtes.
Pour créer un graphe, la meilleure option en Go est de s’appuyer sur l’abstraction créée par gonum
Dans Gonum, un graphe est une interface qui gère deux objets remplissant les interfaces Node et Edge tels que :
type Graph interface {
Node(id int64) Node
Nodes() Nodes
From(id int64) Nodes
HasEdgeBetween(xid, yid int64) bool
Edge(uid, vid int64) Edge
}type Node interface {
ID() int64
}type Edge interface {
From() Node
To() Node
ReversedEdge() Edge
}Note : tous les commentaires ont été supprimés pour être concis. La définition complète est disponible dans la documentation de gonum
Une fois que les objets du graphe remplissent ces interfaces, il devient possible d’utiliser tous les algorithmes de graphe qui ont été implémentés par l’équipe gonum. Veuillez aller à ce lien si vous souhaitez en savoir plus sur les capacités : pkg.go.dev/gonum.org/v1/gonum/graph#section-directories
Notre structure de graphe
Nous allons créer une structure de haut niveau qui agira comme récepteur pour notre graphe. Pour le graphe lui-même, nous nous appuyons sur l’implémentation simple.DirectedGraph fournie par le projet gonum.
Nous avons donc :
type Graph struct {
*simple.DirectedGraph
}Ensuite, nous allons créer une fonction pour créer et remplir notre graphe à partir de notre rdfGraph.
func NewGraph(rdfGraph *gon3.Graph) *Graph {
g := simple.NewDirectedGraph()
// ... fill the graph
return &Graph{
DirectedGraph: g,
}
}Structure du graphe
Rappelez-vous que le graphe rdf contient un tableau de triplets. Chaque triplet est un terme.
L’objet d’un prédicat est le sujet d’un autre triplet. Par exemple :
schema:subject1 schema:predicate schema:object1 .
schema:object1 schema:otherPredicate schema:object2 .Cela conduirait au graphe suivant :

Cela indique un choix que j’ai fait : je veux produire un graphe où son nœud correspond à un sujet déclaré à l’intérieur du triplestore. Par conséquent, dans l’exemple, object2 n’est pas un nœud car il n’est pas défini comme sujet d’une phrase. Il est relativement facile de changer ce comportement et de référencer d’autres nœuds, mais laissons cela de côté.
Déclaration du nœud
La déclaration de l’objet nœud est assez simple. Un nœud est une structure contenant :
- un id
- un sujet comme vu précédemment
- et une carte de prédicats et d’objets associés au prédicat.
type MyNode struct {
id int64
Subject rdf.Term
PredicateObject map[rdf.Term][]rdf.Term
}L’ajout d’une méthode ID() qui renvoie un int64 la rend compatible avec l’interface Node de gonum.
Il est donc possible de l’ajouter à un graphe simple. Jusqu’à présent, ce code compile (mais est inutile) :
g := &Graph{
DirectedGraph: simple.NewDirectedGraph(),
}
g.DirectedGraph.AddNode(&MyNode{})Déclaration de l’arête
En utilisant le même principe, nous créons une structure Edge qui contient deux nœuds From et To ainsi qu’un terme qui définit l’arête.
type Edge struct {
F, T graph.Node
Term rdf.Term
}Par conséquent, ce code compile (mais est inutile) :
g := &Graph{
DirectedGraph: simple.NewDirectedGraph(),
}
n0:=&MyNode{id:0}
n1:=&MyNode{id:1}
g.DirectedGraph.AddNode(n0)
g.DirectedGraph.AddNode(n1)
e := Edge{F: n0, T: n1}
g.SetEdge(e)Nous avons créé un graphe avec deux nœuds et une arête entre eux.
Analyse du graphe rdf pour générer notre graphe orienté
La première chose que nous ferons est de créer un arbre de termes. Nous le faisons grâce à une table de hachage. La clé est un sujet, et la valeur est une autre carte. La clé de valeur de la carte est un prédicat et la valeur est un tableau d’objets (rappelez-vous qu’un prédicat peut pointer vers plusieurs objets)
tree := make(map[gon3.Term]map[gon3.Term][]gon3.Term)Mais avant d’analyser le graphe rdf pour remplir l’arbre, nous devons aborder un petit problème. un Term est une interface. C’est donc un pointeur. Par conséquent, dans le graphe rdf, si nous considérons deux Terms t1 et t2 tels que :
t1 := gon3.NewLiteral("bla")
t2 := gon3.NewLiteral("bla")t1 est différent de t2 (même si leurs valeurs sont les mêmes)
Pour résoudre ce problème, nous allons suivre un dictionnaire de termes indexés par leur RawValue().
type Dict map[string]rdf.Term
func (d Dict) getOrInsert(t rdf.Term) rdf.Term {
//...
}Ensuite, nous itérons sur les triplets de notre graphe rdf pour remplir l’arbre et le dictionnaire.
for s := range rdfGraph.IterTriples() {
// ... fill dict and tree
}Note : pour plus de commodité, nous définirons également le dictionnaire comme attribut à notre graphe pour plus tard. La structure devient :
type Graph struct {
*simple.DirectedGraph
Dict map[string]rdf.Term}Nous pouvons maintenant parcourir l’arbre et créer tous les nœuds du graphe pour chaque sujet :
for s, po := range tree {
n := &Node{
id: g.NewNode().ID(),
Subject: s,
PredicateObject: po,
}
g.AddNode(n)
reference[s] = n
}Note : encore une fois, pour plus de commodité, nous suivons les nœuds dans une table de hachage. Cette carte de référence a le sujet comme clé et le nœud comme valeur (son type est map[rdf.Term]*Node).
Enfin, nous parcourons une nouvelle fois l’arbre pour créer les arêtes :
for s, po := range tree {
me := reference[s]
for predicate, objects := range po {
for _, object := range objects {
if me == to { // self edge
continue
}
to := reference[object]
e := Edge{ F: me, T: to, Term: predicate, }
g.SetEdge(e)
}
}
}Note : le traitement des erreurs est omis pour être concis
Tout assembler
Maintenant que nous avons le constructeur de graphe ok, nous pouvons le tester avec les données de schema.org que nous avons téléchargées précédemment.
Écrivons un programme simple qui crée le graphe et fait une requête simple. Par exemple, nous pourrions vouloir obtenir tous les nœuds directement liés à PostalAddress dans schema.org.
baseURI := "https://example.org/foo"
parser := rdf.NewParser(baseURI)
gr, err := parser.Parse(os.Stdin)
if err != nil {
log.Fatal(err)
}
g := graph.NewGraph(gr)
postalAddress := g.Dict["http://schema.org/PostalAddress"]
node := g.Reference[postalAddress]
it := g.To(node.ID())
for it.Next() {
n := it.Node().(*graph.Node) // need inference here because gonum's simple graph returns a type graph.Node which is an interface
fmt.Printf("%v -> %v\n", node.Subject, n.Subject)
}Cela imprime la sortie suivante :
❯ cat schemaorg-current-http.ttl| go run main.go
<http://schema.org/PostalAddress> -> <http://schema.org/deliveryAddress>
<http://schema.org/PostalAddress> -> <http://schema.org/postalCode>
<http://schema.org/PostalAddress> -> <http://schema.org/servicePostalAddress>
<http://schema.org/PostalAddress> -> <http://schema.org/originAddress>
<http://schema.org/PostalAddress> -> <http://schema.org/addressCountry>
<http://schema.org/PostalAddress> -> <http://schema.org/location>
<http://schema.org/PostalAddress> -> <http://schema.org/billingAddress>
<http://schema.org/PostalAddress> -> <http://schema.org/addressLocality>
<http://schema.org/PostalAddress> -> <http://schema.org/postOfficeBoxNumber>
<http://schema.org/PostalAddress> -> <http://schema.org/streetAddress>
<http://schema.org/PostalAddress> -> <http://schema.org/address>
<http://schema.org/PostalAddress> -> <http://schema.org/addressRegion>
<http://schema.org/PostalAddress> -> <http://schema.org/gameLocation>
<http://schema.org/PostalAddress> -> <http://schema.org/itemLocation>Si nous vérifions sur le site web de schema.org (https://schema.org/PostalAddress), nous trouvons ces éléments mais dans deux tableaux différents :
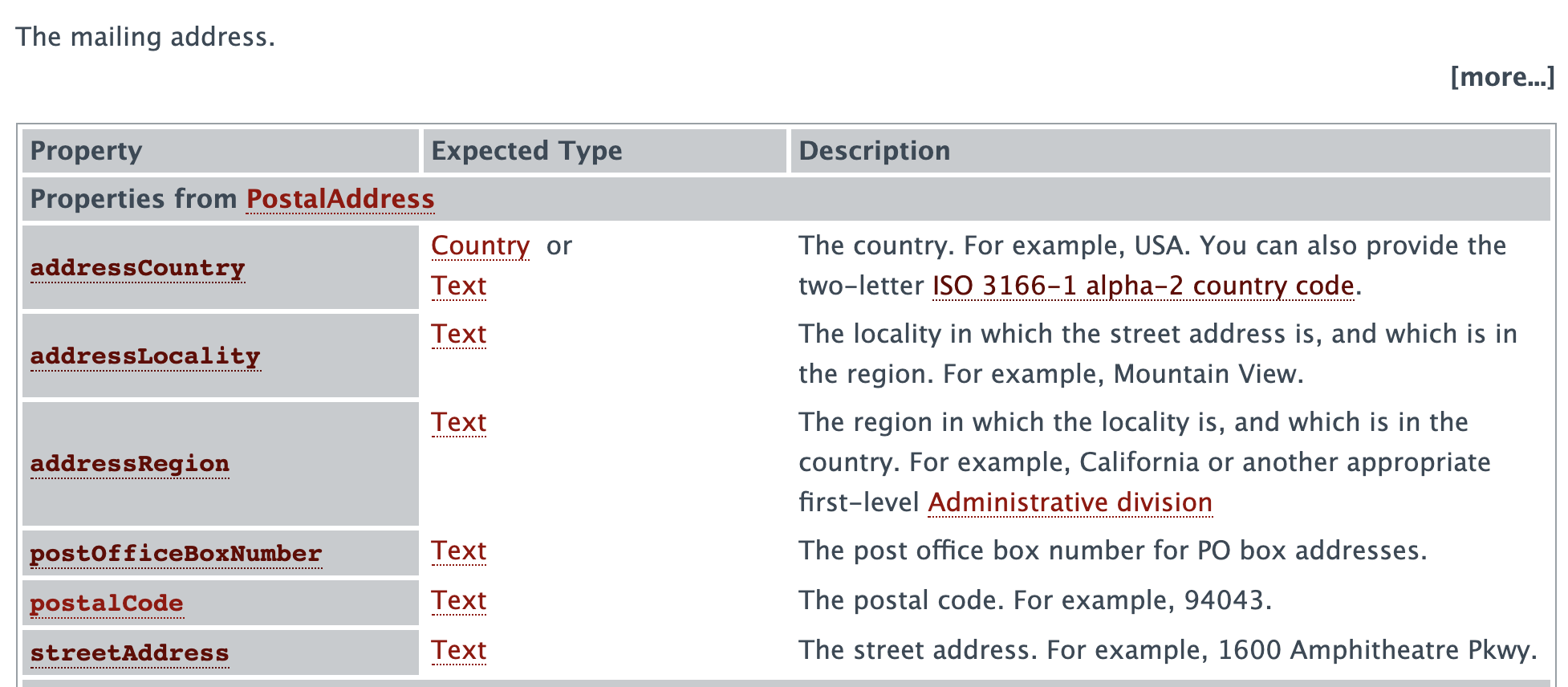
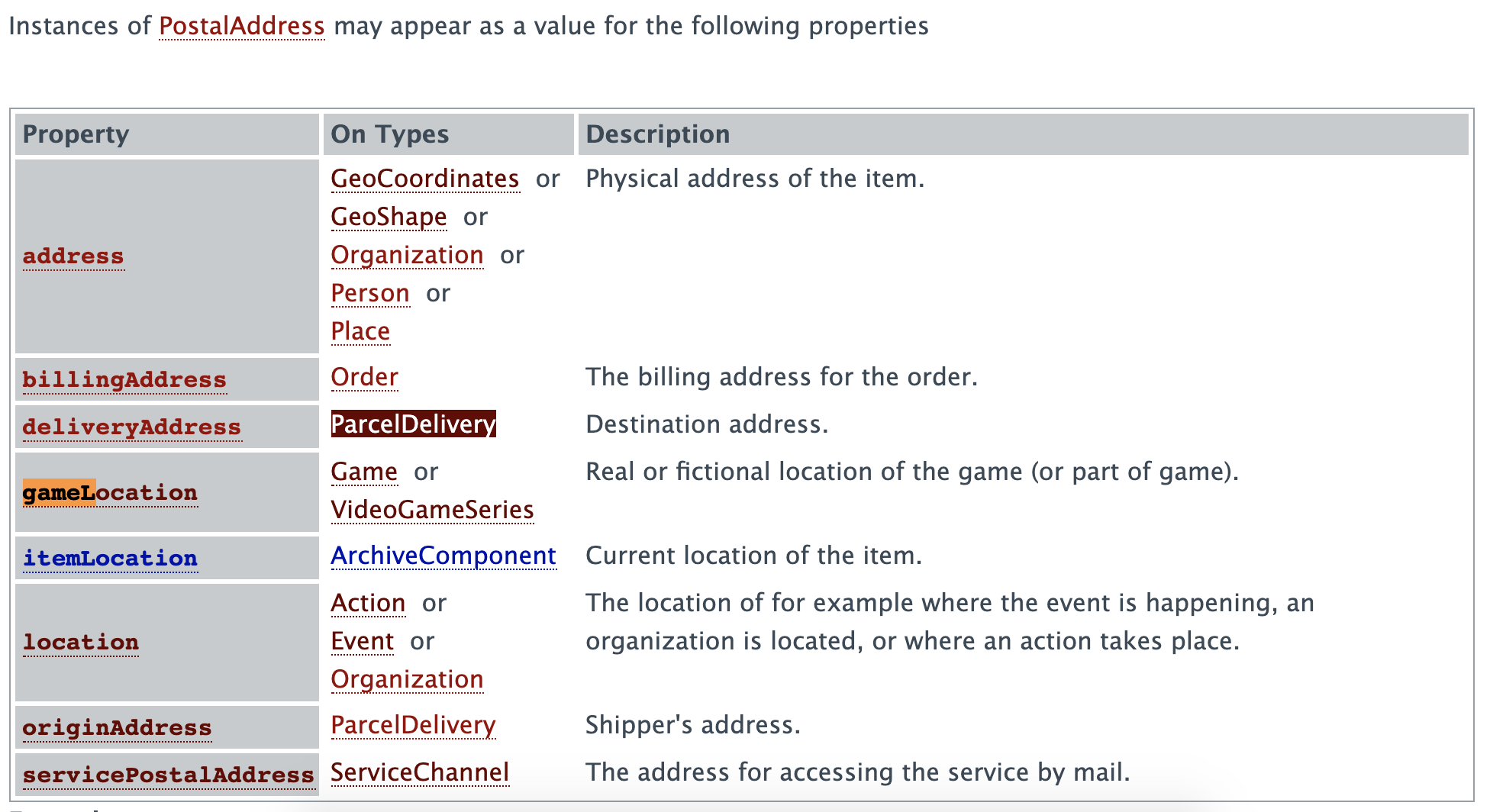
Rappelez-vous, nous traitons avec l’ontologie ; par conséquent, le lien a une signification. Et cette signification a été définie comme un attribut de l’arête. Si nous modifions le code pour afficher l’arête comme ceci :
for it.Next() {
n := it.Node().(*graph.Node) // need inference here because gonum's simple graph returns a type graph.Node which is an interface
e := g.Edge(n.ID(), node.ID()).(graph.Edge)
fmt.Printf("%v -%v-> %v\n", node.Subject, e.Term, n.Subject)
}nous obtenons :
<http://schema.org/PostalAddress> -<http://schema.org/domainIncludes>-> <http://schema.org/addressRegion>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/billingAddress>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/servicePostalAddress>
<http://schema.org/PostalAddress> -<http://schema.org/domainIncludes>-> <http://schema.org/streetAddress>
<http://schema.org/PostalAddress> -<http://schema.org/domainIncludes>-> <http://schema.org/addressCountry>
<http://schema.org/PostalAddress> -<http://schema.org/domainIncludes>-> <http://schema.org/postOfficeBoxNumber>
<http://schema.org/PostalAddress> -<http://schema.org/domainIncludes>-> <http://schema.org/addressLocality>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/location>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/itemLocation>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/deliveryAddress>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/address>
<http://schema.org/PostalAddress> -<http://schema.org/domainIncludes>-> <http://schema.org/postalCode>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/gameLocation>
<http://schema.org/PostalAddress> -<http://schema.org/rangeIncludes>-> <http://schema.org/originAddress>Conclusion
Nous avons construit rapidement une structure de graphe en mémoire. Ce qui est important n’est pas la structure en soi. L’important est les perspectives qu’elle ouvre. Jusqu’à présent, nous avons travaillé sur des schémas, mais la sémantique s’applique aux données elles-mêmes. En plus de cela, le graphe que nous avons généré est raisonnablement générique. Par conséquent, le même principe pourrait être utilisé pour stocker notre graphe de connaissances dans une base de données persistante telle que dgraph ou peut-être neo4j.
Dans le prochain article, nous travaillerons avec le graphe et mettrons en place un moteur de modèle pour créer une documentation générique de notre graphe de connaissances en utilisant go template.
En attendant, vous pouvez récupérer le code (qui n’est pas prêt pour la production) sur mon github