Ontologie, graphes et turtles - Partie I
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
Nous sommes maintenant submergés de données, et le nouveau problème est de savoir comment leur donner un sens.
Project Haystack1
L’apprentissage automatique laisse l’impression qu’alimenter un modèle avec beaucoup de données pourrait produire un résultat magique.
De plus, les dirigeants d’entreprise pensent que l’apprentissage automatique est une arme ultime qui apportera en douceur un avantage concurrentiel.
Malheureusement, l’expérience a montré qu’aucun modèle n’est assez puissant pour comprendre des données sans structure.
Pour trouver un modèle représentant l’information, il est nécessaire de vraiment comprendre la forme de la connaissance cachée dans les données.
Nous parlons ici de sémantique. Cette série d’articles traite d’une façon d’exprimer une sémantique des données : l’ontologie.
À propos de l’ontologie
Comme défini dans l’introduction, le but de la sémantique est d’aider à organiser l’information pour mieux comprendre la connaissance qu’elle porte.
La science derrière l’idée de décrire un domaine de connaissance en nommant et catégorisant les choses s’appelle la taxonomie. Une taxonomie est en gros un arbre représentant divers éléments d’un domaine d’expertise.
L’ontologie va un pas plus loin en décrivant la relation entre les éléments. Elle peut être vue comme une collection de diverses taxonomies représentant un domaine de connaissance et les relations entre elles.
Une ontologie est un ensemble de concepts et de catégories dans un domaine ou un sujet qui montre leurs propriétés et les relations entre eux.
dictionnaire Oxford
Plus simplement, une ontologie est une façon de montrer les propriétés d’un domaine et comment elles sont liées en définissant un ensemble de concepts et de catégories qui représentent le sujet (Wikipedia).
Aujourd’hui, la plupart des données opérationnelles ont une modélisation sémantique faible et nécessitent un processus manuel et intensif pour “cartographier” les données avant que la création de valeur puisse commencer. L’utilisation pratique des conventions de nommage et des taxonomies peut rendre plus rentable l’analyse, la visualisation et l’extraction de valeur de nos données opérationnelles.
Exemple
Pour illustrer, je prends le même modèle que Mark Burgess dans son livre “In search of certainty”2 : représenter les connaissances concernant les performances musicales.
La taxonomie aide à représenter un artiste, un disque, et à définir qu’ils sont liés d’une certaine manière. Considérant que je veux classer mes disques vinyles, je peux d’abord les ordonner par artistes puis par titre d’album. Par conséquent, chaque chanteur est une catégorie où je trouve tous les albums sur lesquels ils jouent.
Prenons cet exemple visuel trivial :

Nous voyons ici que Peter Gabriel est lié à l’album So.
Considérons maintenant cet autre arbre (imaginez que je possède deux fois le disque et que je mets une étiquette Peter Gabriel sur l’un, et Daniel Lanois sur le second) :

En tant qu’humain, si vous connaissez assez bien le pop/rock, vous savez peut-être que Peter Gabriel est l’interprète du disque. Peut-être savez-vous que Daniel Lanois est le producteur… Mais aucune de ces informations n’est portée dans les données.
L’ontologie est intéressante car nous appliquons des métadonnées à la relation elle-même ; cela permet d’enrichir l’information tout en restant libre des contraintes d’une structure de données.

Sémantique : sujets, prédicats, objets
En français simple, nous pouvons exprimer la connaissance représentée par les images en utilisant des phrases simples comme :
- “Peter Gabriel est le chanteur de l’album So.”
- “Daniel Lanois est le producteur de l’album So.”
Les règles de la grammaire (française) donnent un modèle qui explique la construction de ces phrases. Ce modèle est un simple triplet : sujet, prédicat, objet.
“Peter Gabriel” et “Daniel Lanois” sont les sujets des phrases, “est le chanteur” et “est le producteur” sont les prédicats, et “de l’album So” sont les objets qui complètent le prédicat.
Ce modèle simple, sujet/prédicat/objet, est l’un des outils qui trouve une application appropriée dans le domaine de l’IA connu sous le nom de représentation et raisonnement des connaissances (KR², KR&R).
Représentation des connaissances
La représentation des connaissances est un domaine de l’intelligence artificielle qui se concentre sur la conception de représentations informatiques qui capturent des informations sur le monde pouvant être utilisées pour résoudre des problèmes complexes. (Wikipedia)
Appliqué aux entreprises, un raccourci pourrait être : si la connaissance est le nouveau pétrole, la représentation des connaissances est son sol.
Expression des données
Une donnée est une façon d’exprimer des actifs pour les rendre traitables par un ordinateur (les données sont un ensemble de données). L’information est un ensemble de données, dont les significations des parties sont établies par un groupe de règles de langage. La connaissance est un ensemble d’informations.
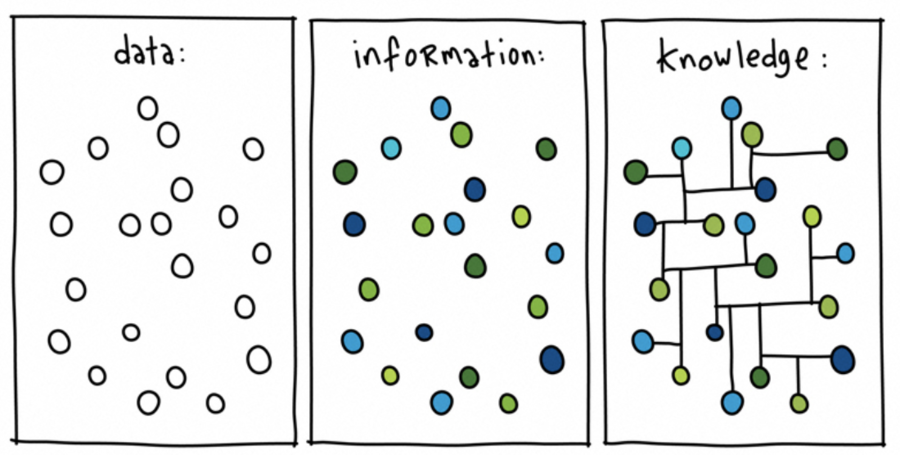
Pour sérialiser l’information (et donc la connaissance), nous pouvons utiliser des données et appliquer la règle fournie par le modèle sujets/prédicats/objets.
Évolution progressive vers un graphe de connaissance avec turtle
Prenons un raccourci et considérons qu’il est donc possible de représenter la connaissance que nous avons d’un domaine avec un graphe. Considérons également que ce graphe peut être exprimé grâce à une sémantique très simple basée sur des triplets (appelés triplets).
Nous recherchons maintenant un moyen d’exprimer cette nouvelle base de données d’information.
Tout ne peut pas rentrer dans des lignes et des colonnes
Ashok Vishwakarma3
Ce dont nous avons besoin maintenant est une façon informatique d’exprimer ces triplets. Une sorte de langage primaire qu’un ordinateur peut comprendre (sinon nous pourrions utiliser n’importe quel langage humain, qui est une façon relativement complète de décrire le monde)
Heureusement, c’est un problème résolu, et le consortium w3 a validé la spécification de langages permettant l’expression de triplets pour être facilement compris par les ordinateurs et par les humains.
Pour le bien de ces articles, et concernant mes expériences, je me concentrerai sur l’un d’entre eux : Turtle.
Turtle est une syntaxe très simple au-dessus du Resource Description Framework (RDF). C’est un langage à usage général pour représenter l’information sur le Web.
C’est un moyen pratique d’exprimer un schéma et un triplestore, une base de données contenant une structure de graphe pour représenter la connaissance des données.
Note: pour la communication machine-à-machine sur le web, la représentation JSON-LD peut être préférée. Beaucoup de gens pensent que JSON est convivial ; je ne suis peut-être pas l’un de ses amis.
Turtle, en 30 secondes.
Turtle a une syntaxe simple et directe.
Une phrase est composée de trois termes séparés par des blancs (espaces, tabulations, nouvelles lignes, …) et terminés par un point.
Les termes peuvent être des littéraux, des Internationalized Resource Identifiers (IRIs) (enclos par des crochets angulaires <>). Les trois termes apparaissent dans l’ordre en tant que sujet, prédicat, objet.
Un sujet peut avoir de nombreux prédicats séparés par des points-virgules, et les prédicats peuvent pointer vers plusieurs objets séparés par des virgules.
Ex:
"Peter Gabriel" "Sing" "So" .L’utilisation d’IRI facilite l’échange d’informations et permet de s’assurer qu’elles ont la même signification au-delà des frontières des domaines d’activité.
Ex:
<http://mydomain/#PeterGabriel>
<http://mydomain/schema/person/job/Sing> <http://mydomain/#So> .Cela permet de référencer “Peter Gabriel” avec un ID unique à travers le monde, et d’interroger toutes les informations que nous connaissons à son sujet.
Pour simplifier l’utilisation d’IRI, Turtle introduit également une notion de “préfixe”. Un préfixe est une sorte de raccourci vers les espaces de noms.
Le dernier exemple pourrait donc être exprimé comme ceci :
@prefix ex <http://mydomain/#>
ex:PeterGabriel <http://mydomain/schema/person/job/Sing> ex:So .Exemple plus concret : Wikidata
Wikipedia s’appuie sur ces principes pour organiser ses connaissances. Les informations sur les méta-informations peuvent être trouvées sur le côté de n’importe quelle page Wikipedia sous le lien “élément wikidata”.
Les préfixes utilisés dans la représentation turtle sont :
@prefix wd: <http://www.wikidata.org/entity/> .
@prefix wdt: <http://www.wikidata.org/prop/direct/> .wd représente une donnée ; wdt une propriété. Une phrase est construite de cette façon :
wd:entity1 wdt:property wd:entity2 .Cette phrase peut être traduite en français comme :
entity1 a la propriété entity2 .
Alors ?
Pour utiliser notre exemple musical, extrayons quelques éléments de Wikipedia :
| label | notation courte | IRI complet |
|---|---|---|
| Peter Gabriel | wd:Q175195 | http://www.wikidata.org/entity/Q175195 |
| Daniel Lanois | wd:Q935369 | http://www.wikidata.org/entity/Q935369 |
| Producteur | wdt:P162 | http://www.wikidata.org/prop/direct/P162 |
| Interprète | wdt:P175 | http://www.wikidata.org/prop/direct/P175 |
Imaginons que nous voulions trouver des éléments correspondant à ces déclarations :
- cet élément a un interprète (http://www.wikidata.org/prop/direct/P175) qui est Peter Gabriel (http://www.wikidata.org/entity/Q175195).
- cet élément a un producteur (http://www.wikidata.org/prop/direct/P162) qui est Daniel Lanois (http://www.wikidata.org/entity/Q935369).
Maintenant, convertissons-le en triplets
?element wdt:P162 wd:Q935369 .
?element wdt:P175 wd:Q175195 .Et nous ajoutons quelques éléments syntaxiques pour faire une requête appropriée en SPARQL4 :
SELECT ?element ?elementLabel
WHERE
{
?element wdt:P162 wd:Q935369 .
?element wdt:P175 wd:Q175195 .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}L’exécution de la requête dans query.wikidata.org donne les résultats attendus et plus :
| element | elementLabel |
|---|---|
| wd:Q587020 | Big Time |
| wd:Q593978 | Sledgehammer |
| wd:Q657185 | So |
| wd:Q2328200 | Us |
| wd:Q2518359 | Birdy |
| wd:Q4122307 | In Your Eyes |
| wd:Q4244402 | Steam |
| wd:Q4244573 | Blood of Eden |
| wd:Q4246560 | Digging in the Dirt |
| wd:Q6818803 | Mercy Street |
| wd:Q12860980 | Kiss That Frog |
| wd:Q59219021 | Don’t Give Up |
| wd:Q59220135 | In Your Eyes |
Nous avons plus de résultats que prévu car la requête renvoie tous les éléments, pas seulement les albums. Pour filtrer sur l’album, nous devrions ajouter une déclaration :
Cet élément est une instance de album studio.
Ceci est laissé comme exercice au lecteur.
Et après
Dans cet article, j’ai introduit les concepts derrière l’ontologie et le graphe de connaissances. Je crois que ces concepts sont essentiels pour exploiter la quantité de données qui inondent nos centres de données. Important car c’est un moyen pour une entreprise d’exposer son langage ubiquitaire pour décrire les actifs qu’elle gère.
Partager la connaissance, c’est le pouvoir !
Le prochain article présentera une façon technique d’analyser la base de données de connaissances (triplestore) pour créer une structure de graphe en mémoire. Un troisième article expliquera éventuellement comment exploiter le graphe pour exposer l’information avec un moteur de modèle. L’objectif est de pouvoir rendre l’information de la même manière que schema.org le fait.
-
In Search of Certainty - Mark Burgess - Chapitre 11. The Human Condition: How humans make friends to solve problems. ↩︎
-
Ashok Vishwakarma - https://speakerdeck.com/avishwakarma/not-everything-can-fit-in-rows-and-columns ↩︎
-
SPARQL est un langage de requête sémantique pour les bases de données, capable de récupérer et de manipuler des données stockées au format Resource Description Framework (RDF). Sa présentation est hors de portée de cet article, pour en savoir plus, veuillez consulter https://www.wikidata.org/wiki/Wikidata:SPARQL_tutorial pour plus d’informations sur son utilisation avec wikidata. ↩︎