Ontology, graphs and turtles - Part I
We are now awash in data, and the new problem is how to make sense of it.
Project Haystack1
Machine Learning leaves the impression that feeding a model with much data could produce a magical result.
Moreover, business C-Levels think machine learning is an ultimate weapon that will smoothly bring a competitive advantage.
Sadly, the experience has shown that no model is powerful enough to understand structureless data.
To find a model representing information, there is a need to truly understand the shape of the knowledge hidden in the data.
We are talking about semantic here. This series of posts is about a way to express a semantic of data: ontology.
About ontology
As defined in the introduction, the semantic purpose is to help organize the information to better understand the knowledge it carries.
The science behind the idea of describing a domain of knowledge by naming and categorizing things is called taxonomy. A taxonomy is roughly a tree representing various elements of a field of expertise.
Ontology goes one step further by describing the relationship between the elements. It can be seen as a collection of various taxonomies representing a domain of knowledge and the relationships among them.
An ontology is a set of concepts and categories in a subject area or domain that shows their properties and the relations between them.
oxford dictionary
More simply, an ontology is a way of showing the properties of a subject area and how they are related by defining a set of concepts and categories that represent the subject (Wikipedia).
Today most operational data has low semantic modeling and requires a manual, labor-intensive process to “map” the data before value creation can begin. Practical use of naming conventions and taxonomies can make it more cost-effective to analyze, visualize, and derive value from our operational data.
Example
To illustrate, I am taking the same model as Mark Burgess in his book “In search of certainty”2: representing knowledge regarding musical performances.
Taxonomy helps to represent an artist, a record, and define that they are linked somehow. Considering that I want to classify my LPs, I can first order them by artists and then by album title. Therefore each singer is a category where I find all the albums they perform on.
Let’s take this trivial visual example:

We see here that Peter Gabriel is linked to the album So.
Now consider this other tree (imagine that I own two times the record and I put a label Peter Gabriel on one, and Daniel Lanois on the second):

As a human, if you know enough pop/rock, you may know that Peter Gabriel is the record’s performer. Maybe you know that Daniel Lanois is the producer… But none of this information is carried within the data.
Ontology is interesting because we apply metadata to the relationship itself; it allows to enrich the information while remaining free of the constraints of a data structure.

Semantic: subjects, predicates, objects
In plain English, we can express the knowledge represented by the pictures using simple sentences like:
- “Peter Gabriel is the singer on the Album So.”
- “Daniel Lanois is the producer of the Album So.”
The rules of (English) grammar give a model that explains the construction of those sentences. This model is a simple triple: subject, predicate, object.
“Peter Gabriel” and “Daniel Lanois” are subjects of the sentences, “is the singer” and “is the producer” predicate, and “on/of the album So” are objects that complete the predicate.
This simple model, subject/predicate/object, is one of the tools that find a proper application on the AI field known as knowledge representation and reasoning (KR², KR&R).
Knowledge representation
Knowledge-representation is a field of artificial intelligence that focuses on designing computer representations that capture information about the world that can be used to solve complex problems. (Wikipedia)
Applied to business, a shortcut could be: if knowledge is the new oil, knowledge representation is its soil.
Data expression
A datum is a way to express assets to make it processable by a computer (data is a set of datum). Information is a set of data, the meanings of whose parts are laid down by a group of language rules. Knowledge is a set of information.
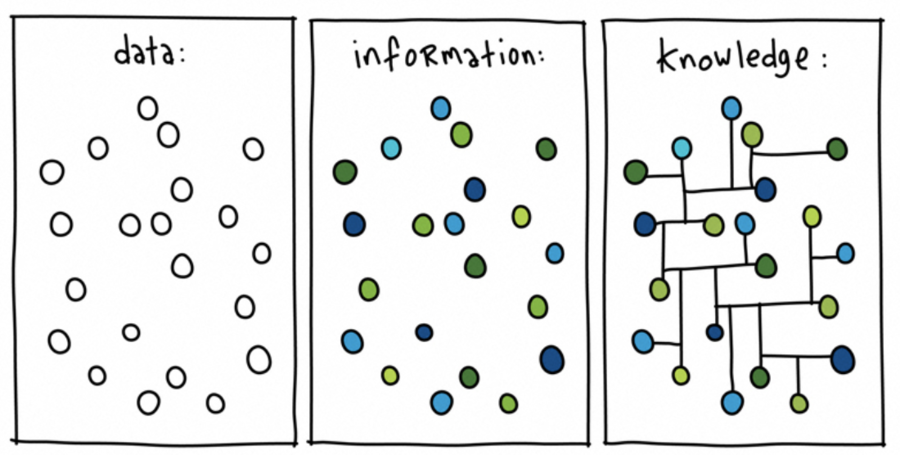
To serialize the information (and therefore the knowledge), we can use data and apply the rule provided by the model subjects/predicates/objects.
Slowly moving to a knowledge graph with turtle
Let’s take a shortcut and consider that it is, therefore, possible to represent the knowledge we have of a domain with a graph. Let’s also act that this graph can be expressed thanks to a very simple semantic based on 3-tuple (called triples).
We are now seeking a way to express this new database of information.
Not everything can fit in rows and columns
Ashok Vishwakarma3
What we need now is a computer way to express those triples. A sort of primary language a computer can understand (otherwise we could use any human language, which is a relatively complete way to describe the world)
Luckily this is a solved problem, and the w3 consortium has validated the specification of languages allowing the expression of triples to be easily understood by computers and by humans.
For the sake of those articles, and regarding my experiments, I will focus on one of those: Turtle.
Turtle is a very simple syntax on top of the Resource Description Framework (RDF). It is a general-purpose language for representing information in the Web.
It is a convenient way to express a schema and a triplestore, a database holding a graph structure for representing the knowledge of data.
Note: for machine-to-machine communication over the web, the JSON-LD representation may be preferred. Many people think that JSON is user friendly; I may not be one of its friends.
Turtle, in 30 seconds.
Turtle has a simple and straightforward syntax.
A sentence is composed of three terms separated by blank (spaces, tabs, newlines, …) and ended by a dot.
Terms can be literals, Internationalized Resource Identifiers (IRIs) (enclosed by angle brackets <>). The three terms appear in order as subject, predicate, object.
A subject can have many predicates separated by semi-colons, and predicates can point to several objects separated by commas.
Ex:
"Peter Gabriel" "Sing" "So" .The use of IRI makes it easier to exchange information and to make sure that they have the same meaning across the boundaries of the business domains.
Ex:
<http://mydomain/#PeterGabriel>
<http://mydomain/schema/person/job/Sing> <http://mydomain/#So> .This allows to reference “Peter Gabriel” with a unique ID across the world, and to query all of the information we know about him.
To simplify the use of IRI, Turtle also introduces a notion of “prefix”. A prefix is a kind of shortcut to namespaces.
The last example could therefore be expressed like this:
@prefix ex <http://mydomain/#>
ex:PeterGabriel <http://mydomain/schema/person/job/Sing> ex:So .More concrete example: Wikidata
Wikipedia relies on the principles to organize its knowledge. Information about meta information can be found on the side of any Wikipedia page under the link “wikidata item”.
The prefixes used in the turtle representation are:
@prefix wd: <http://www.wikidata.org/entity/> .
@prefix wdt: <http://www.wikidata.org/prop/direct/> .wd represents a data; wdt a property. A sentence is constructed this way:
wd:entity1 wdt:property wd:entity2 .This sentence can be translated in English as:
entity1 has the property entity2 .
So?
To use our musical example, let’s extract some elements from Wikipedia:
| label | short notation | full IRI |
|---|---|---|
| Peter Gabriel | wd:Q175195 | http://www.wikidata.org/entity/Q175195 |
| Daniel Lanois | wd:Q935369 | http://www.wikidata.org/entity/Q935369 |
| Producer | wdt:P162 | http://www.wikidata.org/prop/direct/P162 |
| Performer | wdt:P175 | http://www.wikidata.org/prop/direct/P175 |
Imagine that we want to find elements corresponding to those statements:
- this element has a perfomer (http://www.wikidata.org/prop/direct/P175) who is Peter Gabriel (http://www.wikidata.org/entity/Q175195).
- this element has a producer (http://www.wikidata.org/prop/direct/P162) who is Daniel Lanois (http://www.wikidata.org/entity/Q935369).
Now convert it into triples
?element wdt:P162 wd:Q935369 .
?element wdt:P175 wd:Q175195 .And we add some syntactic sugar to do a proper query in SPARQL4:
SELECT ?element ?elementLabel
WHERE
{
?element wdt:P162 wd:Q935369 .
?element wdt:P175 wd:Q175195 .
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}Executing the query inside query.wikidata.org gives the expected results and more:
| element | elementLabel |
|---|---|
| wd:Q587020 | Big Time |
| wd:Q593978 | Sledgehammer |
| wd:Q657185 | So |
| wd:Q2328200 | Us |
| wd:Q2518359 | Birdy |
| wd:Q4122307 | In Your Eyes |
| wd:Q4244402 | Steam |
| wd:Q4244573 | Blood of Eden |
| wd:Q4246560 | Digging in the Dirt |
| wd:Q6818803 | Mercy Street |
| wd:Q12860980 | Kiss That Frog |
| wd:Q59219021 | Don’t Give Up |
| wd:Q59220135 | In Your Eyes |
We have more results than expected because the query returns all the elements, not only the albums. To filter on the album, we should add a statement:
This element is an instance of studio album.
This is left as an exercise to the reader.
What’s next
In this article, I have introduced the concepts behind the ontology and knowledge graph. I believe that those concepts are essential to exploit the amount of data flooding our data-centers. Important because it is a way for a business to expose its ubiquitous language to describe the assets it manages.
Sharing knowledge is power!
The next article will present a technical way to parse the knowledge database (triplestore) to create a graph structure in-memory. A third article will eventually explain how to exploit the graph to expose the information with a template engine. The goal is to be able to render information the same way schema.org does.
-
In Search of Certainty - Mark Burgess - Chapter 11. The Human Condition: How humans make friends to solve problems. ↩︎
-
Ashok Vishwakarma - https://speakerdeck.com/avishwakarma/not-everything-can-fit-in-rows-and-columns ↩︎
-
SPARQL is a a semantic query language for databases, able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. Its presentation is out-of-scope of this article, to learn more, please cf https://www.wikidata.org/wiki/Wikidata:SPARQL_tutorial for more info on how to use it with wikidata. ↩︎