The Human in the AI Learning Loop
Note: this article has been translated by an AI; original is in French
Introduction
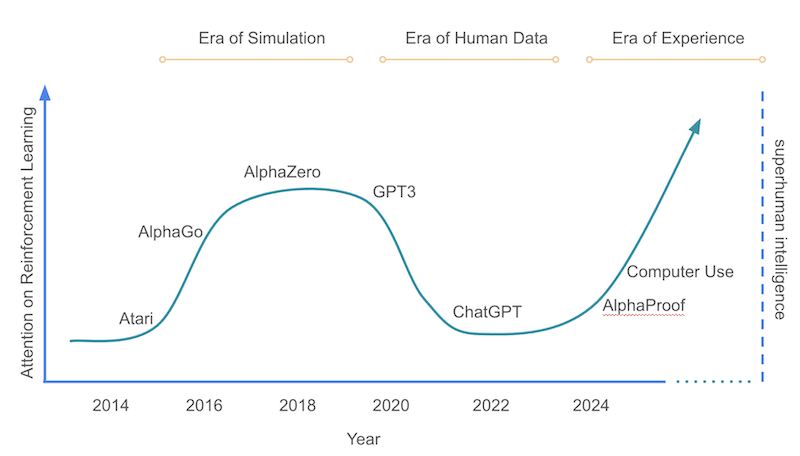
I have always been fascinated by AlphaGo, then AlphaZero, and this concept of reinforcement learning. A machine that plays against itself, learns on its own, and reaches superhuman levels. There is something magical there that goes beyond mere technical prowess.
When in 2016, AlphaGo defeated Lee Sedol, one of the greatest Go players of all time, it wasn’t simply a technological victory. It was a pivotal moment in our relationship with artificial intelligence. For the first time, a machine demonstrated its ability to master a game considered the pinnacle of human intuition, a domain where experience and creativity seemed irreplaceable.
Then came AlphaZero, the quintessential self-learning system. With no knowledge other than the rules of the game, it independently developed innovative strategies in Go, chess, and shogi, quickly surpassing all specialized artificial intelligences and the best human players. Its method? Tirelessly playing against itself, learning from each game, refining its understanding of the game in its purest form.
This journey strangely reminds me of the movie WarGames and its philosophical conclusion: “The only winning move is not to play” – this idea of an AI that discovers wisdom on its own, beyond mere performance. That was the initial dream: an intelligence that learns to understand the world autonomously.
But today, generative AI simply generates. Regardless of the context, it produces a response. Always. Is that truly intelligent? Haven’t we abandoned something essential along the way?
Listening to David Silver — A Key Insight
In a recent episode of the DeepMind podcast, I was particularly struck by the remarks of David Silver, the principal architect of AlphaGo and AlphaZero. He highlighted a fundamental distinction that seemed to illuminate the entire recent evolution of AI:
“The more human intervention you introduce into a system, the more its performance tends to degrade. Conversely, when humans step back, the system becomes more effective.”
This observation may seem counterintuitive, even provocative in a world where we constantly talk about human-centered AI. Yet, it reveals a profound truth about the nature of machine learning.
AlphaZero discovered strategies that centuries of chess theory had not explored, precisely because it wasn’t limited by our preconceptions. It learned directly from the world – or rather from a perfect simulation of it – without the filter of human judgments.
His ideas are fully captured in a paper downloadable here: Welcome to the Era of Experience. The rest of this article is essentially a synthesis of his perspectives, which I endorse.
What Changed With Large Language Models
With the advent of large language models (LLMs) like ChatGPT, Claude, or Gemini, we have witnessed a subtle but profound paradigm shift. Reinforcement learning continues to play a key role, but in radically different ways.
Unlike AlphaZero, modern LLMs integrate reinforcement learning with data from human interactions. The essential difference? They are optimized according to human preferences.
The process, known as Reinforcement Learning from Human Feedback (RLHF), works as follows:
- The system generates multiple potential outputs for the same query
- A human evaluator compares these responses and indicates which one they consider preferable
- The system then adjusts its behavior to maximize the probability of producing responses similar to those preferred
The model no longer plays against itself in an environment with objective rules; it now “plays” to satisfy a human evaluator. This approach has proven crucial in deploying models that are truly useful in everyday life.
RLHF: An Advancement… and a Limitation
RLHF represents an undeniable advancement. Rather than simply replicating web data, which is often problematic or inappropriate, this method allows models to generate more relevant, coherent responses aligned with human expectations.
Without RLHF, our interactions with LLMs would probably be frustrating, inconsistent, or even dangerous. This process has transformed statistical models into useful assistants.
However, this method introduces a fundamental constraint: it limits the models’ ability to go beyond the framework of human knowledge. If a human evaluator does not perceive the value of an innovative response or an optimized strategy, the system has no way of learning it.
Let’s take a concrete example: a model is asked for a cake recipe. It proposes one. The human evaluator judges its quality… without ever baking it. The feedback provided is therefore speculative, based on a theoretical appreciation — not on actual experimentation.
This is not feedback from the real world. It’s an aesthetic appreciation, not empirical validation. Learning remains bounded by what humans can recognize, value, or understand.
The Importance of Grounding in Reality
This brings us to a fundamental notion: grounding. This refers to an AI system’s ability to establish a reliable correspondence between its internal representations and the physical or operational world in which it operates.
Here’s the paradox: optimization through human feedback can actually decrease the system’s degree of grounding in reality. Why? Because the system is evaluated before its outputs are confronted with concrete reality.
Truly grounded feedback would involve someone making the recipe, tasting the cake, and providing objective feedback: “It’s successful” or “It’s a failure.” This is feedback from the real world — the kind that enables experiential learning, discovery, and sometimes innovation.
Conversely, speculative feedback introduces cognitive bias and locks the system within the limits of the known. It prevents it from exploring counter-intuitive, even counter-cultural avenues. We thus create systems optimized to tell us what we want to hear – simulacra of intelligence rather than entities capable of an authentic understanding of the world.
To Reintroduce Reality: Test, Experiment, Fail
How do we break out of this impasse? The solution may lie in a reintroduction of empirical feedback – based on experience, action, and its consequences – into our AI architectures.
We need models capable of experimenting in simulated or physical environments, where the results of their decisions can be measured objectively, independently of human preferences.
AlphaZero remains an inspiring example of free exploration. Its ability to discover unprecedented strategies comes precisely from its direct interaction with an environment with clear rules, where each game ends in a win, loss, or draw – unambiguous signals from the world.
Projects such as integrating AI agents into complex virtual environments, where they can interact with objects, solve problems, and observe the consequences of their actions, are steps in this direction. As are robots that learn through trial and error to manipulate physical objects.
Conclusion – Towards an AI that Rediscovers the World
Sometimes, you really need to bake that Monster Munch muffin described by Professor Hannah Fry to discover that it might be… delicious. Models won’t learn anything new as long as we don’t let them try, fail, succeed – in contact with reality.
The future of AI doesn’t solely lie in ever-larger systems, trained on ever more textual data and optimized to please humans. It may be found in a rediscovery of learning through direct experience – whether simulated or real.
It’s time to rethink our learning loops, to reintroduce environments where AI can learn from consequences, not just preferences. To create systems that, like AlphaZero in its time, can surprise us by discovering solutions we would never have envisioned.
Because true intelligence is not measured by its ability to reproduce what we already know, but to discover what we still don’t know. And for that, we must reconnect with reality – that infinite field of experimentation where failure often precedes discovery, and where the unexpected can prove valuable.