L'humain dans la boucle d'apprentissage des IA
L’émerveillement initial
J’ai toujours été fasciné par AlphaGo, puis AlphaZero, et cette idée d’apprentissage par renforcement. La machine qui joue contre elle-même, apprend seule, et atteint un niveau surhumain. Il y a là quelque chose de magique qui dépasse la simple prouesse technique.
Lorsqu’en 2016, AlphaGo a vaincu Lee Sedol, l’un des plus grands joueurs de Go de tous les temps, ce n’était pas simplement une victoire technologique. C’était un moment de bascule dans notre rapport à l’intelligence artificielle. Pour la première fois, une machine démontrait sa capacité à maîtriser un jeu considéré comme l’apogée de l’intuition humaine, un domaine où l’expérience et la créativité semblaient irremplaçables.
Puis est venu AlphaZero, système auto-apprenant par excellence. Sans autre connaissance que les règles du jeu, il a développé seul des stratégies innovantes au Go, aux échecs et au shogi, dépassant rapidement toutes les intelligences artificielles spécialisées et les meilleurs joueurs humains. Sa méthode ? Jouer inlassablement contre lui-même, apprendre de chaque partie, affiner sa compréhension du jeu dans sa forme la plus pure.
Ce parcours me rappelle étrangement le film WarGames et sa conclusion philosophique : “The only winning move is not to play” – cette idée d’une IA qui découvre elle-même la sagesse, au-delà de la simple performance. C’était le rêve initial : une intelligence qui apprend à comprendre le monde de façon autonome.
Mais aujourd’hui, l’IA générative, elle, génère. Peu importe le contexte, elle produit une réponse. Toujours. Est-ce vraiment intelligent ? N’avons-nous pas abandonné quelque chose d’essentiel en cours de route ?
L’écoute de David Silver — un éclairage clé
Dans un récent épisode du podcast de DeepMind, j’ai été particulièrement marqué par les propos de David Silver, l’architecte principal d’AlphaGo et AlphaZero. Il y soulignait une distinction fondamentale qui m’a semblé éclairer toute l’évolution récente de l’IA :
“Plus on introduit d’intervention humaine dans un système, plus ses performances tendent à se dégrader. À l’inverse, lorsque l’humain se retire, le système devient plus performant.”
Cette observation peut sembler contre-intuitive, voire provocatrice dans un monde où l’on parle constamment d’IA centrée sur l’humain. Pourtant, elle révèle une vérité profonde sur la nature de l’apprentissage machine.
AlphaZero a découvert des stratégies que des siècles de théorie échiquéenne n’avaient pas explorées, précisément parce qu’il n’était pas limité par nos préconceptions. Il a appris directement du monde – ou plutôt d’une simulation parfaite de celui-ci – sans le filtre des jugements humains.
L’intégralité de ses idées sont reprises dans un papier téléchargeable ici: Welcome to the Era of Experience. La suite de cet article est essentiellement une synthèse de ses propos auxquels j’adhère.
Ce qui a changé avec les grands modèles de langage
Avec l’avènement des grands modèles de langage (LLMs) comme ChatGPT, Claude ou Gemini, nous avons assisté à un changement de paradigme subtil mais profond. L’apprentissage par renforcement continue à jouer un rôle clé, mais selon des modalités radicalement différentes.
Contrairement à AlphaZero, les LLMs modernes intègrent l’apprentissage par renforcement à des données issues d’interactions humaines. La différence essentielle ? Ils sont optimisés en fonction des préférences humaines.
Le processus, connu sous le nom de Reinforcement Learning from Human Feedback (RLHF), fonctionne ainsi :
- Le système génère plusieurs sorties potentielles pour une même requête
- Un évaluateur humain compare ces réponses et indique celle qu’il juge préférable
- Le système ajuste alors son comportement pour maximiser la probabilité de produire des réponses similaires à celles préférées
Le modèle ne joue plus contre lui-même dans un environnement aux règles objectives ; il “joue” désormais pour satisfaire un évaluateur humain. Cette approche s’est révélée cruciale dans la mise en production de modèles véritablement utiles au quotidien.
RLHF : une avancée… et une limite
Le RLHF représente une avancée incontestable. Plutôt que de simplement répliquer les données du web, souvent problématiques ou inadaptées, cette méthode permet aux modèles de générer des réponses plus pertinentes, cohérentes et alignées avec les attentes humaines.
Sans le RLHF, nos interactions avec les LLMs seraient probablement frustrants, incohérentes, voire dangereuses. Ce processus a transformé des modèles statistiques en assistants utiles.
Cependant, cette méthode introduit une contrainte fondamentale : elle limite la capacité des modèles à dépasser le cadre des connaissances humaines. Si un évaluateur humain ne perçoit pas la valeur d’une réponse innovante ou d’une stratégie optimisée, le système n’a aucun moyen de l’apprendre.
Prenons un exemple concret : on demande au modèle une recette de gâteau. Il en propose une. L’évaluateur humain juge sa qualité… sans jamais la cuisiner. Le retour fourni est donc spéculatif, fondé sur une appréciation théorique — non sur une expérimentation réelle.
Ce n’est pas un retour du monde réel. C’est une appréciation esthétique, pas une validation empirique. L’apprentissage reste borné par ce que l’humain sait reconnaître, valoriser ou comprendre.
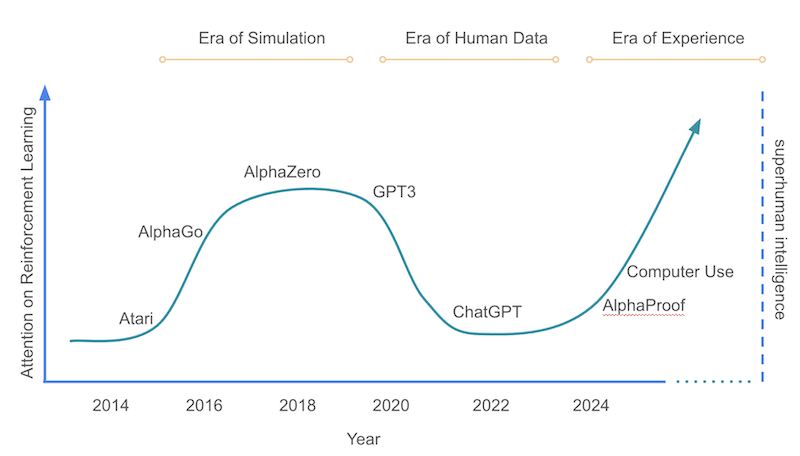
L’importance de l’ancrage dans le réel
Ceci nous amène à une notion fondamentale : l’ancrage dans le réel (grounding). Il s’agit de la capacité d’un système d’IA à établir une correspondance fiable entre ses représentations internes et le monde physique ou opérationnel dans lequel il intervient.
Or, voici le paradoxe : l’optimisation par retour humain peut, en réalité, diminuer le degré d’ancrage du système dans le réel. Pourquoi ? Parce que le système est évalué avant que ses sorties ne soient confrontées à la réalité concrète.
Un retour véritablement ancré impliquerait qu’un individu réalise la recette, goûte le gâteau, et fournisse un retour objectif : “C’est réussi” ou “C’est raté”. C’est cela, le feedback du monde réel — celui qui permet l’apprentissage expérientiel, la découverte, et parfois l’innovation.
À l’inverse, un retour spéculatif introduit un biais cognitif et fige le système dans les limites du connu. Il l’empêche d’explorer des pistes contre-intuitives, voire contre-culturelles. Nous créons ainsi des systèmes optimisés pour dire ce que nous voulons entendre – des simulacres d’intelligence plutôt que des entités capables d’une compréhension authentique du monde.
Pour réintroduire le réel : tester, expérimenter, échouer
Comment sortir de cette impasse ? La solution réside peut-être dans une réintroduction du feedback empirique – basé sur l’expérience, l’action et ses conséquences – dans nos architectures d’IA.
Nous avons besoin de modèles capables d’expérimenter dans des environnements simulés ou physiques, où les résultats de leurs décisions peuvent être mesurés objectivement, indépendamment des préférences humaines.
AlphaZero demeure un exemple inspirant d’exploration libre. Sa capacité à découvrir des stratégies inédites vient précisément de son interaction directe avec un environnement aux règles claires, où chaque partie se termine par une victoire, une défaite ou une égalité – des signaux non ambigus du monde.
Des projets comme l’intégration d’agents IA dans des environnements virtuels complexes, où ils peuvent interagir avec des objets, résoudre des problèmes et observer les conséquences de leurs actions, constituent des pas dans cette direction. De même que les robots qui apprennent par essai-erreur à manipuler des objets physiques.
Conclusion – Vers une IA qui redécouvre le monde
Parfois, il faut vraiment cuire ce fameux muffin aux Monster Munch que décrit le Professeur Hannah Fry pour découvrir qu’il est peut-être… délicieux. Les modèles n’apprendront rien de nouveau tant qu’on ne les laisse pas tenter, rater, réussir – au contact du réel.
L’avenir de l’IA ne réside pas uniquement dans des systèmes toujours plus grands, entraînés sur toujours plus de données textuelles et optimisés pour plaire aux humains. Il se trouve peut-être dans une redécouverte de l’apprentissage par l’expérience directe – qu’elle soit simulée ou réelle.
Il est temps de repenser nos boucles d’apprentissage, de réintroduire des environnements où l’IA peut apprendre des conséquences, pas seulement des préférences. De créer des systèmes qui, comme AlphaZero en son temps, peuvent nous surprendre en découvrant des solutions que nous n’aurions jamais envisagées.
Car l’intelligence véritable ne se mesure pas à sa capacité à reproduire ce que nous savons déjà, mais à découvrir ce que nous ignorons encore. Et pour cela, il faut renouer avec le réel – ce terrain d’expérimentation infini où l’échec précède souvent la découverte, et où l’inattendu peut se révéler précieux.