MCP Part II - Implementation: Custom Host with VertexAI and Gemini
In the first part of this series, I explored some concepts and convictions regarding agentivity in AI and the potential of tooling to enhance agents.
The final words were about the host (the application) running LLM-powered assistants (Claude, ChatGPT, …). These applications will represent the true battleground. The companies that gain a monopoly on assistant systems will govern tomorrow’s digital business.
This is one reason why, for my experimentation, I do not want to rely on an existing application. I want to understand the standards, how the wiring with the LLM works, and gain new skills in a private environment.
I have decided to implement a host “from scratch.” Well, not really from scratch, because I will heavily rely on the execution engine of an LLM and its SDK.
I could have used Ollama to run a private model, but I decided to use Vertex AI on Google GCP in a private project instead. First, I have access to GCP. Second, the API is fairly stable, and I generally like how the concepts are exposed via Google’s API. It helps me understand how things work.
I have also decided to use Go as a programming language because:
- I know Go.
- Go is fun (really fun).
- The Vertex AI SDK in Go exists (see doc here at pkg.go.dev.
Overall architecture
I will implement a basic chat engine. I will not implement a frontend because very good open-source frontends already exist. I have chosen to use Big-AGI. Since I want to use what is already existing, my chat system will be compatible with OpenAI’s v1 API. It appears this is a common standard in the AI world. Therefore, I will be able to easily connect my host with Big-AGI.
I have chosen to implement the /v1/chat/completions endpoint in a streaming manner. This will provide the best user experience when chatting and will replicate what we are used to in ChatGPT or Claude.
Implementation of the “Chat Handler”
Understanding how the chat session works (with VertexAI)
The entry point of the VertexAI’s GenAI API is an object called the GenerativeModel.
The documentation states:
GenerativeModelis a model that can generate text.
It is therefore the entry point for a conversation.
The model can generate content (or streamed content) via calls to its methods:
GenerateContentGenerateContentStream
This is suitable for a single call, but to handle a full chat session, the API offers another object: the ChatSession.
The ChatSession manages the chat history. Taking the example from Part I of the article, the ChatSession is responsible for maintaining the Context Window.
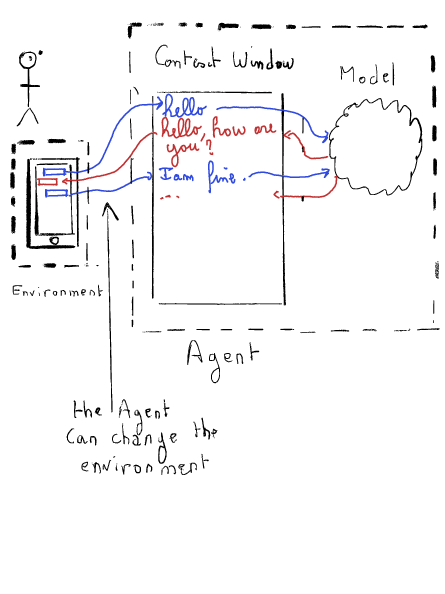
The ChatSession has two methods:
SendMessageSendMessageStream
Both encapsulate the GenerateContent and GenerateContentStream methods mentioned earlier.
Implementing the Chat endpoint
In our implelentation, we are encapsulating the genai.ChatSession and genai.GenerativeModel into our own structure ChatSession.
type ChatSession struct {
cs *genai.ChatSession
model *genai.GenerativeModel
}Then we add a http handler to this structure to handle the call to /v1/chat/completion
func main() {
cs := NewChatSession()
// Initialize the client
mux := http.NewServeMux()
mux.Handle("/v1/chat/completions", http.HandlerFunc(cs.chatCompletionHandler))
}
func (cs *ChatSession) chatCompletionHandler(w http.ResponseWriter, r *http.Request) {...}Authentication to the VertexAI service
The authentication hasn’t been fully developed. I’m using the default authentication methods provided by the API, which rely on the authentication tokens generated by the gcloud service locally.
Note: This makes it fairly portable to a well-configured GCP environment, in a service such as Cloud Run.
client, err := genai.NewClient(ctx, projectID, locationID)Handling the request
The chatCompletionHandler is in charge of decoding the POST request and validating it.
It deserializes the JSON payload into an object ChatCompletionRequest
type ChatCompletionRequest struct {
Model string `json:"model"`
Messages []ChatCompletionMessage `json:"messages"`
MaxTokens int `json:"max_tokens"`
Temperature float64 `json:"temperature"`
Stream bool `json:"stream"`
StreamOptions struct {
IncludeUsage bool `json:"include_usage"`
} `json:"stream_options"`
}
// ChatCompletionMessage represents a single message in the chat conversation.
type ChatCompletionMessage struct {
Role string `json:"role"`
Content interface{} `json:"content,omitempty"` // Can be string or []map[string]interface{}
Name string `json:"name,omitempty"`
ToolCalls []ChatCompletionMessageToolCall `json:"tool_calls,omitempty"`
FunctionCall *ChatCompletionFunctionCall `json:"function_call,omitempty"`
Audio *ChatCompletionAudio `json:"audio,omitempty"`
}It’s worth noting that each completion message takes the model as a parameter. Therefore, with the OpenAI API, it’s possible to use multiple models throughout a conversation.
The handler should also be responsible for validating the current session and using or creating a genai.ChatSession accordingly. In my proof of concept (POC), I haven’t implemented this. As a consequence, I can only handle one session. This means that if I start a new conversation in Big-AGI, I will inherit the history of the previous one, and I have no way to delete it (unless I restart the host).
If the streaming is enabled in the request, we call another method:
func (cs *ChatSession) streamResponse(
w http.ResponseWriter,
r *http.Request,
request ChatCompletionRequest) {
...
}This is where the magic happens.
Sending/Streaming the response
This method uses the genai.ChatSession.SendMessageStream method to ask the model to generate content. This function takes Message Part as parameters. I’ve created a simple method to convert the Messages from the OpenAI API into Google’s genai.Part. Note that it also handles images.
func (c *ChatCompletionMessage) toGenaiPart() []genai.Part {...}The SendMessageStream returns an iterator (Google’s own implementation of an iterator, likely predating the official Go language iterator).
We need to iterate to get the full response from the model and serialize it into a ChatCompletionStreamResponse that will be sent back to the Big-AGI client.
type ChatCompletionStreamResponse struct {
ID string `json:"id"`
Object string `json:"object"`
Created int64 `json:"created"`
Model string `json:"model"`
Choices []ChatCompletionStreamChoice `json:"choices"`
}
type ChatCompletionStreamChoice struct {
Index int `json:"index"`
Delta ChatMessage `json:"delta"`
Logprobs interface{} `json:"logprobs"`
FinishReason string `json:"finish_reason"`
}The API can send multiple choices, but for the purpose of this POC, I’ve chosen to only send one.
This is it, with this simple implementation, I can use the service as a backend to Big-AGI
Implementing functions
My goal is to extend the capabilities of the host, and eventually to use the MCP protocol to do so. The first step is to increase the capabilities of the model by providing functions.
The GenerativeModel’s API has exported fields. One of them it Tools, and this looks like a good starting point:
type GenerativeModel struct {
GenerationConfig
SafetySettings []*SafetySetting
Tools []*Tool
ToolConfig *ToolConfig // configuration for tools
SystemInstruction *Content
// The name of the CachedContent to use.
// Must have already been created with [Client.CreateCachedContent].
CachedContentName string
// contains filtered or unexported fields
}In the doc, it is mentioned that a Tool, is:
a piece of code that enables the system to interact with external systems to perform an action, or set of actions, outside of knowledge and scope of the model. A Tool object should contain exactly one type of Tool (e.g FunctionDeclaration, Retrieval or GoogleSearchRetrieval).
By implementing tools, we will be in the situation described by this diagram:
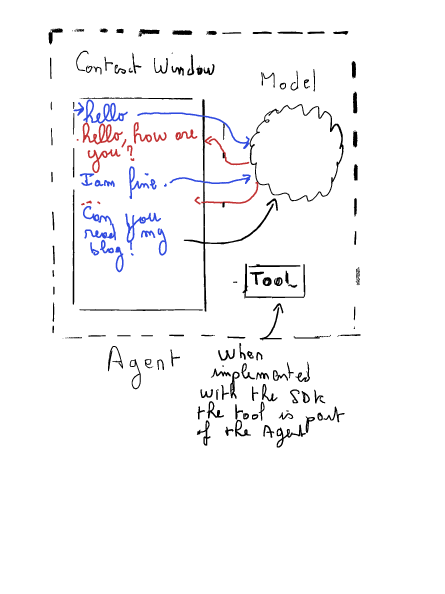
Following the example of the Doc, we can create and add a tool to the model an follow the workflow:
// For using tools, the chat mode is useful because it provides the required
// chat context. A model needs to have tools supplied to it in the chat
// history so it can use them in subsequent conversations.
//
// The flow of message expected here is:
//
// 1. We send a question to the model
// 2. The model recognizes that it needs to use a tool to answer the question,
// an returns a FunctionCall response asking to use the CurrentWeather
// tool.
// 3. We send a FunctionResponse message, simulating the return value of
// CurrentWeather for the model's query.
// 4. The model provides its text answer in response to this message.The problem with the streaming
Initially, I implemented the function as described in the example, find_theater. However, implementing it via streaming didn’t work as expected. When I tried to send the FunctionResponse message, the model returned a 400 error:
Please ensure that function call turns come immediately after a user turn or after a function response turn.
The issue was that the iterator wasn’t empty, and therefore the model was receiving the function response before the function request had been properly set.
I implemented a workaround using a stack of functions with Push and Pop functions. If the request is a function call, I Push the request onto the stack. When the iterator is empty, I Pop the function, execute it, and send its response back to the ChatSession with SendMessageStream. The reply is a new iterator that is used to complete the request sent to the end-user.
type FunctionCallStack struct {
mu sync.Mutex
items []genai.FunctionCall
}
// Push adds a genai.FunctionCall to the top of the stack.
func (s *FunctionCallStack) Push(call genai.FunctionCall) {...}
// Pop removes and returns the last genai.FunctionCall from the stack (FIFO).
// Returns nil if the stack is empty
func (s *FunctionCallStack) Pop() *genai.FunctionCall {...}I’m aware that this isn’t a bulletproof solution, but it works for my POC.
Conclusion and preparation of the MCP
This host is functional, and the model calls the function when it deems it useful. However, my goal is to move the tool out of the agent.
This will be implemented in the last part of this series of articles. To prepare for this, I’ve implemented an abstraction of the function call, so I can avoid tweaking the chatCompletion handlers.
I’ve created an interface callable with the following methods:
type callable interface {
GetGenaiTool() *genai.Tool
Run(genai.FunctionCall) (*genai.FunctionResponse, error)
Name() string
}Then, I’ve updated my ChatSession structure with an inventory of callable:
type ChatSession struct {
cs *genai.ChatSession
model *genai.GenerativeModel
functionsInventory map[string]callable
}Now, I can register all the callables as Tools to the GenerativeModel (by calling the GetGenaiTool() method), and within a chat session, I can detect whether the function’s name is part of the inventory, call the Run() method, and send the reply back.
Final Note About the function call and Conclusion
It is interesting to note that the model decides by itself whether it needs to call the function. As explained before, the model only deals with text. Therefore, the description of the function and its parameters are key. It is really about convincing the model that this function is useful in its reasoning.
On top of that, it is important to note that the result of the function is also injected into the context. The fun part is that I can easily display the history and all the exchanges between the user and the model. It teaches me a lot about the mechanisms of those chatbots.
The strange part about engineering is the lack of idempotence. You can ask the same question twice and get different answers. As Luc De Brabandere wrote, we are now back to the statistical era: it works x% of the time, and we find that good enough.
This proof of concept represents the technological foundation of my POC with the Model Context Protocol.
Now it is fairly easy to add new functions. It is a matter of fulfilling the callable interface.
Please note that this implementation is partial because a Tool can expose several functions, which is not possible with my current implementation.
In the next and final part of this series, I will create an MCP client implementing the callable interface and a sample MCP server.
This server will register its capabilities automatically.
Therefore, providing tools to my chatbot will become easy.
If you want to try this server, the code is on my GitHub