MCP Partie II - Implémentation : Hôte personnalisé avec VertexAI et Gemini
Voici la traduction en français :
Dans la première partie de cette série, j’ai exploré certains concepts et convictions concernant l’agentivité dans l’IA et le potentiel des outils pour améliorer les agents.
Les derniers mots portaient sur l’hôte (l’application) exécutant des assistants alimentés par des LLM (Claude, ChatGPT, …). Ces applications représenteront le véritable champ de bataille. Les entreprises qui obtiendront un monopole sur les systèmes d’assistants gouverneront le business numérique de demain.
C’est l’une des raisons pour lesquelles, dans mes expérimentations, je ne veux pas dépendre d’une application existante. Je veux comprendre les standards, comment fonctionne le câblage avec le LLM et acquérir de nouvelles compétences dans un environnement privé.
J’ai décidé d’implémenter un hôte “from scratch”. Enfin, pas tout à fait, car je vais fortement m’appuyer sur le moteur d’exécution d’un LLM et son SDK.
J’aurais pu utiliser Ollama pour exécuter un modèle privé, mais j’ai décidé d’utiliser Vertex AI sur Google GCP dans un projet privé à la place. Premièrement, j’ai accès à GCP. Deuxièmement, l’API est relativement stable et j’aime généralement la façon dont les concepts sont exposés via l’API de Google. Cela m’aide à comprendre comment les choses fonctionnent.
J’ai également décidé d’utiliser Go comme langage de programmation parce que :
- Je connais Go.
- Go est fun (vraiment fun).
- Le SDK Vertex AI en Go existe (voir la doc ici sur pkg.go.dev).
Architecture générale
Je vais implémenter un moteur de chat basique. Je ne vais pas implémenter de frontend, car il existe déjà de très bons frontends open source. J’ai choisi d’utiliser Big-AGI. Puisque je veux utiliser ce qui existe déjà, mon système de chat sera compatible avec l’API v1 d’OpenAI. Il semble que ce soit un standard courant dans le monde de l’IA. Ainsi, je pourrai facilement connecter mon hôte avec Big-AGI.
J’ai choisi d’implémenter le point d’entrée /v1/chat/completions de manière streaming. Cela offrira la meilleure expérience utilisateur lorsqu’on discute et reproduira ce à quoi nous sommes habitués avec ChatGPT ou Claude.
Implémentation du “Chat Handler”
Comprendre le fonctionnement de la session de chat (avec VertexAI)
Le point d’entrée de l’API GenAI de VertexAI est un objet appelé GenerativeModel.
La documentation indique :
GenerativeModelest un modèle capable de générer du texte.
C’est donc le point d’entrée d’une conversation.
Le modèle peut générer du contenu (ou du contenu en streaming) via les appels à ses méthodes :
GenerateContentGenerateContentStream
Cela convient à un appel unique, mais pour gérer une session de chat complète, l’API propose un autre objet : ChatSession.
La ChatSession gère l’historique du chat. En reprenant l’exemple de la Partie I de l’article, la ChatSession est responsable du maintien de la fenêtre de contexte.
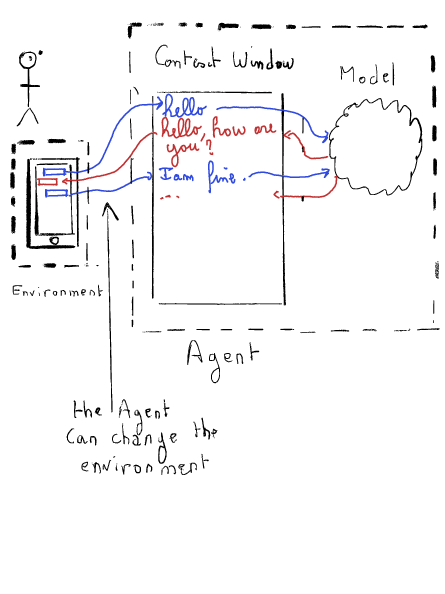
La ChatSession possède deux méthodes :
SendMessageSendMessageStream
Toutes deux encapsulent les méthodes GenerateContent et GenerateContentStream mentionnées précédemment.
Implémentation du point d’entrée Chat
Dans notre implémentation, nous encapsulons genai.ChatSession et genai.GenerativeModel dans notre propre structure ChatSession.
type ChatSession struct {
cs *genai.ChatSession
model *genai.GenerativeModel
}Puis, nous ajoutons un handler HTTP à cette structure pour gérer l’appel à /v1/chat/completion.
func main() {
cs := NewChatSession()
// Initialisation du client
mux := http.NewServeMux()
mux.Handle("/v1/chat/completions", http.HandlerFunc(cs.chatCompletionHandler))
}
func (cs *ChatSession) chatCompletionHandler(w http.ResponseWriter, r *http.Request) {...}Authentification au service VertexAI
L’authentification n’a pas encore été entièrement développée. J’utilise les méthodes d’authentification par défaut fournies par l’API, qui reposent sur les jetons d’authentification générés localement par le service gcloud.
Note : Cela le rend assez portable vers un environnement GCP bien configuré, tel que Cloud Run.
client, err := genai.NewClient(ctx, projectID, locationID)Gestion de la requête
Le chatCompletionHandler est chargé de décoder la requête POST et de la valider.
Il désérialise le JSON en un objet ChatCompletionRequest.
type ChatCompletionRequest struct {
Model string `json:"model"`
Messages []ChatCompletionMessage `json:"messages"`
MaxTokens int `json:"max_tokens"`
Temperature float64 `json:"temperature"`
Stream bool `json:"stream"`
StreamOptions struct {
IncludeUsage bool `json:"include_usage"`
} `json:"stream_options"`
}
// ChatCompletionMessage représente un message unique dans la conversation.
type ChatCompletionMessage struct {
Role string `json:"role"`
Content interface{} `json:"content,omitempty"`
Name string `json:"name,omitempty"`
ToolCalls []ChatCompletionMessageToolCall `json:"tool_calls,omitempty"`
FunctionCall *ChatCompletionFunctionCall `json:"function_call,omitempty"`
Audio *ChatCompletionAudio `json:"audio,omitempty"`
}À noter que chaque message de complétion prend le modèle comme paramètre. Avec l’API OpenAI, il est donc possible d’utiliser plusieurs modèles au cours d’une conversation.
Le handler doit également valider la session en cours et utiliser ou créer une genai.ChatSession en conséquence. Dans mon POC, cette partie n’a pas été implémentée. Par conséquent, je ne peux gérer qu’une seule session. Cela signifie que si je démarre une nouvelle conversation dans Big-AGI, j’hérite de l’historique de la précédente sans moyen de le supprimer (sauf en redémarrant l’hôte).
Si le mode streaming est activé, on appelle une autre méthode :
func (cs *ChatSession) streamResponse(
w http.ResponseWriter,
r *http.Request,
request ChatCompletionRequest) {
...
}C’est là que la magie opère.
Envoi/Streaming de la réponse
Cette méthode utilise la fonction genai.ChatSession.SendMessageStream pour demander au modèle de générer du contenu. Cette fonction prend des Part de type Message comme paramètres. J’ai créé une méthode simple pour convertir les Messages de l’API OpenAI en genai.Part de Google. Notez qu’elle gère également les images.
func (c *ChatCompletionMessage) toGenaiPart() []genai.Part {...}Le SendMessageStream retourne un itérateur (l’implémentation propre à Google d’un itérateur, probablement antérieure à l’itérateur officiel du langage Go).
Nous devons itérer pour obtenir la réponse complète du modèle et la sérialiser en ChatCompletionStreamResponse qui sera renvoyée au client Big-AGI.
type ChatCompletionStreamResponse struct {
ID string `json:"id"`
Object string `json:"object"`
Created int64 `json:"created"`
Model string `json:"model"`
Choices []ChatCompletionStreamChoice `json:"choices"`
}
type ChatCompletionStreamChoice struct {
Index int `json:"index"`
Delta ChatMessage `json:"delta"`
Logprobs interface{} `json:"logprobs"`
FinishReason string `json:"finish_reason"`
}L’API peut envoyer plusieurs choix, mais pour les besoins de cette preuve de concept, j’ai choisi de n’en envoyer qu’un seul.
C’est tout, avec cette implémentation simple, je peux utiliser le service comme backend pour Big-AGI.
Implémentation des fonctions
Mon objectif est d’étendre les capacités de l’hôte, et éventuellement d’utiliser le protocole MCP pour le faire. La première étape consiste à augmenter les capacités du modèle en fournissant des fonctions.
L’API du GenerativeModel a des champs exportés. L’un d’eux est Tools, et cela semble être un bon point de départ :
type GenerativeModel struct {
GenerationConfig
SafetySettings []*SafetySetting
Tools []*Tool
ToolConfig *ToolConfig // configuration pour les outils
SystemInstruction *Content
// Le nom du CachedContent à utiliser.
// Doit avoir été créé préalablement avec [Client.CreateCachedContent].
CachedContentName string
// contient des champs filtrés ou non exportés
}Dans la documentation, il est mentionné qu’un Tool est :
un morceau de code qui permet au système d’interagir avec des systèmes externes pour effectuer une action ou un ensemble d’actions en dehors des connaissances et de la portée du modèle. Un objet Tool doit contenir exactement un type d’outil (par exemple FunctionDeclaration, Retrieval ou GoogleSearchRetrieval).
En implémentant des outils, nous serons dans la situation décrite par ce diagramme :
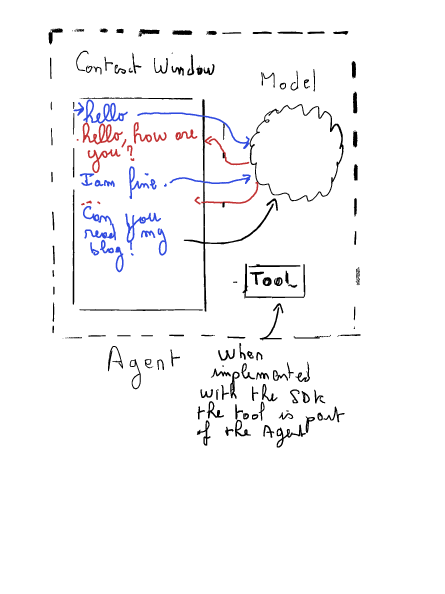
En suivant l’exemple de la documentation, nous pouvons créer et ajouter un outil au modèle et suivre le flux de travail :
// Pour utiliser des outils, le mode chat est utile car il fournit le contexte
// de chat requis. Un modèle doit avoir des outils fournis dans l'historique
// du chat pour pouvoir les utiliser dans les conversations suivantes.
//
// Le flux de messages attendu ici est :
//
// 1. Nous envoyons une question au modèle
// 2. Le modèle reconnaît qu'il a besoin d'utiliser un outil pour répondre à la question,
// et retourne une réponse FunctionCall demandant à utiliser l'outil CurrentWeather
// 3. Nous envoyons un message FunctionResponse, simulant la valeur de retour de
// CurrentWeather pour la requête du modèle.
// 4. Le modèle fournit sa réponse textuelle en réponse à ce message.Le problème avec le streaming
Initialement, j’ai implémenté la fonction comme décrit dans l’exemple, find_theater. Cependant, l’implémentation via le streaming n’a pas fonctionné comme prévu. Lorsque j’ai essayé d’envoyer le message FunctionResponse, le modèle a retourné une erreur 400 :
Veuillez vous assurer que les tours d'appel de fonction viennent immédiatement après un tour utilisateur ou après un tour de réponse de fonction.
Le problème était que l’itérateur n’était pas vide, et donc le modèle recevait la réponse de fonction avant que la demande de fonction n’ait été correctement établie.
J’ai implémenté une solution de contournement utilisant une pile de fonctions avec les fonctions Push et Pop. Si la requête est un appel de fonction, je Push la requête sur la pile. Quand l’itérateur est vide, je Pop la fonction, je l’exécute, et j’envoie sa réponse au ChatSession avec SendMessageStream. La réponse est un nouvel itérateur qui est utilisé pour compléter la requête envoyée à l’utilisateur final.
type FunctionCallStack struct {
mu sync.Mutex
items []genai.FunctionCall
}
// Push ajoute un genai.FunctionCall au sommet de la pile.
func (s *FunctionCallStack) Push(call genai.FunctionCall) {...}
// Pop supprime et retourne le dernier genai.FunctionCall de la pile (FIFO).
// Retourne nil si la pile est vide
func (s *FunctionCallStack) Pop() *genai.FunctionCall {...}Je suis conscient que ce n’est pas une solution infaillible, mais elle fonctionne pour ma preuve de concept.
Conclusion et préparation du MCP
Cet hôte est fonctionnel, et le modèle appelle la fonction quand il le juge utile. Cependant, mon objectif est de déplacer l’outil hors de l’agent.
Cela sera implémenté dans la dernière partie de cette série d’articles. Pour préparer cela, j’ai implémenté une abstraction de l’appel de fonction, afin d’éviter de modifier les gestionnaires chatCompletion.
J’ai créé une interface callable avec les méthodes suivantes :
type callable interface {
GetGenaiTool() *genai.Tool
Run(genai.FunctionCall) (*genai.FunctionResponse, error)
Name() string
}Ensuite, j’ai mis à jour ma structure ChatSession avec un inventaire de callable :
type ChatSession struct {
cs *genai.ChatSession
model *genai.GenerativeModel
functionsInventory map[string]callable
}Maintenant, je peux enregistrer tous les callables comme Tools dans le GenerativeModel (en appelant la méthode GetGenaiTool()), et dans une session de chat, je peux détecter si le nom de la fonction fait partie de l’inventaire, appeler la méthode Run(), et renvoyer la réponse.
Note finale sur l’appel de fonction et Conclusion
Il est intéressant de noter que le modèle décide par lui-même s’il a besoin d’appeler la fonction. Comme expliqué précédemment, le modèle ne traite que du texte. Par conséquent, la description de la fonction et de ses paramètres est essentielle. Il s’agit vraiment de convaincre le modèle que cette fonction est utile dans son raisonnement.
De plus, il est important de noter que le résultat de la fonction est également injecté dans le contexte. La partie amusante est que je peux facilement afficher l’historique et tous les échanges entre l’utilisateur et le modèle. Cela m’apprend beaucoup sur les mécanismes de ces chatbots.
La partie étrange de l’ingénierie est le manque d’idempotence. Vous pouvez poser la même question deux fois et obtenir des réponses différentes. Comme l’a écrit Luc De Brabandere, nous sommes maintenant de retour à l’ère statistique : ça fonctionne x% du temps, et nous trouvons cela suffisamment bon.
Cette preuve de concept représente la base technologique de mon POC avec le Model Context Protocol.
Maintenant, il est assez facile d’ajouter de nouvelles fonctions. Il suffit de satisfaire l’interface callable.
Notez que cette implémentation est partielle car un Tool peut exposer plusieurs fonctions, ce qui n’est pas possible avec mon implémentation actuelle.
Dans la prochaine et dernière partie de cette série, je créerai un client MCP implémentant l’interface callable et un exemple de serveur MCP.
Ce serveur enregistrera automatiquement ses capacités.
Ainsi, fournir des outils à mon chatbot deviendra facile.
Si vous voulez essayer ce serveur, le code est sur mon GitHub