Les 3 U de MCP : Rendre un outil Utile, Utilisable et Utilisé par et pour un LLM
NOTE: ceci est une traduction de l’article original en Anglais faite par une IA.
Depuis son annonce il y a quelques mois, le Model Context Protocol (MCP) a suscité une attention considérable.
Initialement, MCP servait de mécanisme simple, essentiellement un système de plugins, permettant aux Grands Modèles de Langage (LLM) d’interagir de façon transparente avec leur environnement, améliorant ainsi les assistants et agents IA. En appliquant la théorie de Wardley pour tracer l’évolution du protocole, je dirais que MCP a dépassé l’étape I (qualifiée de genesis dans l’image), établissant une certitude de solution. De plus, son adoption généralisée suggère qu’il est déjà entré dans la phase II (qualifiée de Custom Built sur l’image).

Note : l’explication de la théorie de Wardley n’entre pas dans le cadre de cet article. Pour plus d’informations, consultez le blog de Simon Wardley.
Par conséquent, nous observons des produits conçus avec MCP. La phase suivante impliquera le développement de produits autour de MCP.
Personnellement, je me concentre sur l’exploration du protocole pour identifier les problèmes spécifiques qu’il peut résoudre efficacement.
J’ai précédemment publié sur une Preuve de Concept (POC) développée pendant l’étape I de MCP, une période où confirmer la viabilité du protocole était primordial.
Actuellement, j’interagis avec une IA qui utilise divers outils. Mon installation comporte un middleware exposant une API REST compatible avec OpenAI v1. En tant qu’utilisateur, j’interagis via une interface utilisateur qui communique avec le middleware. Ce dernier, à son tour, invoque le moteur d’inférence pour fournir des entrées au LLM et orchestre les appels aux outils MCP dans l’ordre déterminé par le LLM.
L’intégration des serveurs MCP dans le middleware est simple, les rendant immédiatement disponibles comme capacités accessibles au LLM.
Le protocole MCP, ainsi que son implémentation middleware, garantit que tout outil devient utilisable par tout LLM compatible avec mon moteur d’inférence (actuellement, j’utilise Vertex AI de Google, avec des projets d’intégration d’Ollama à l’avenir).
Cet article se concentre sur la compréhension de comment créer des outils qui remplissent les 3U (utilisable, utile, utilisé) du point de vue du LLM. J’explorerai la notion d’exposition de prompt du protocole MCP, montrant pourquoi il est important de la considérer lors du passage d’une POC MCP à un produit MCP.
{JSON-RPC + NLP} : Organon Organōn (l’outil des outils)
MCP répond à la question : “Comment l’utilisateur (le LLM dans notre cas) interagit-il avec l’outil ?” en offrant une structure de communication : JSON-RPC.
Mais en réalité, deux langages sont impliqués dans cette communication, tous deux employés par le LLM pour atteindre son objectif avec un outil :
- JSON-RPC, comme mentionné, régit la manipulation d’outils.
- Le langage naturel explique pourquoi l’utilisateur (encore une fois, le LLM) devrait utiliser l’outil.
Il est donc indispensable d’avoir une description claire de l’outil exposé via MCP, comme on le ferait avec une documentation appropriée. Les LLM comprennent notre langage, nous devrions donc leur fournir notre documentation.
Sans cette documentation—descriptions claires et prompts illustratifs—l’outil manque d’affordance du point de vue du LLM. Dans l’interaction homme-machine, l’affordance désigne la qualité d’un objet qui suggère à l’utilisateur comment l’utiliser. Pour un LLM interagissant via le texte, l’affordance signifie que la description textuelle de l’outil (son nom, ses paramètres, sa documentation et les prompts associés) doit clairement indiquer ce qu’il fait et comment l’utiliser correctement. Si ces indices textuels sont manquants ou ambigus, le LLM ne pourra pas percevoir facilement l’utilité de l’outil ou ses exigences opérationnelles, et par conséquent, l’outil risque de ne pas être utilisé, même s’il est potentiellement utile.
Utile pour assurer qu’il est utilisé
Simplement documenter l’outil n’est pas la meilleure façon de créer de l’affordance du point de vue d’un LLM.
Pour mieux guider le LLM, le serveur MCP peut exposer des prompts. Lorsque j’ai découvert l’exposition de prompt dans un outil MCP, je me suis interrogé sur sa place dans le protocole.
Les Actions et les Ressources sont facilement compréhensibles pour les programmeurs, comme les requêtes POST et GET dans une API REST.
Mais qu’en est-il des prompts ?
Selon la norme, les prompts MCP permettent aux serveurs de définir des modèles de prompt réutilisables, contrôlés par l’utilisateur, et des workflows.
À mon sens, l’exposition de prompt aide à garantir que l’outil soit utile au LLM.
Au-delà de la résolution de problèmes répétitifs et complexes, les prompts simplifient la tâche critique de collecte et d’injection de contexte pertinent (comme des fichiers de code spécifiques ou des journaux) nécessaire pour obtenir des résultats significatifs, et ils rendent les capacités LLM spécifiques et de haute valeur du serveur facilement découvrables et accessibles à l’utilisateur final via l’interface client. Cela transforme un potentiel abstrait en actions concrètes et immédiatement disponibles.
En résumé, les prompts MCP aident le LLM (et l’utilisateur interagissant via le LLM ou le client) à répondre à ces questions :
- Pourquoi quelqu’un utiliserait-il cet outil : est-il utile pour résoudre mon problème actuel ?
- Et surtout : Comment l’utiliser efficacement ? (En sélectionnant le prompt approprié et en fournissant les arguments requis, souvent simplifiés par l’interface utilisateur client).
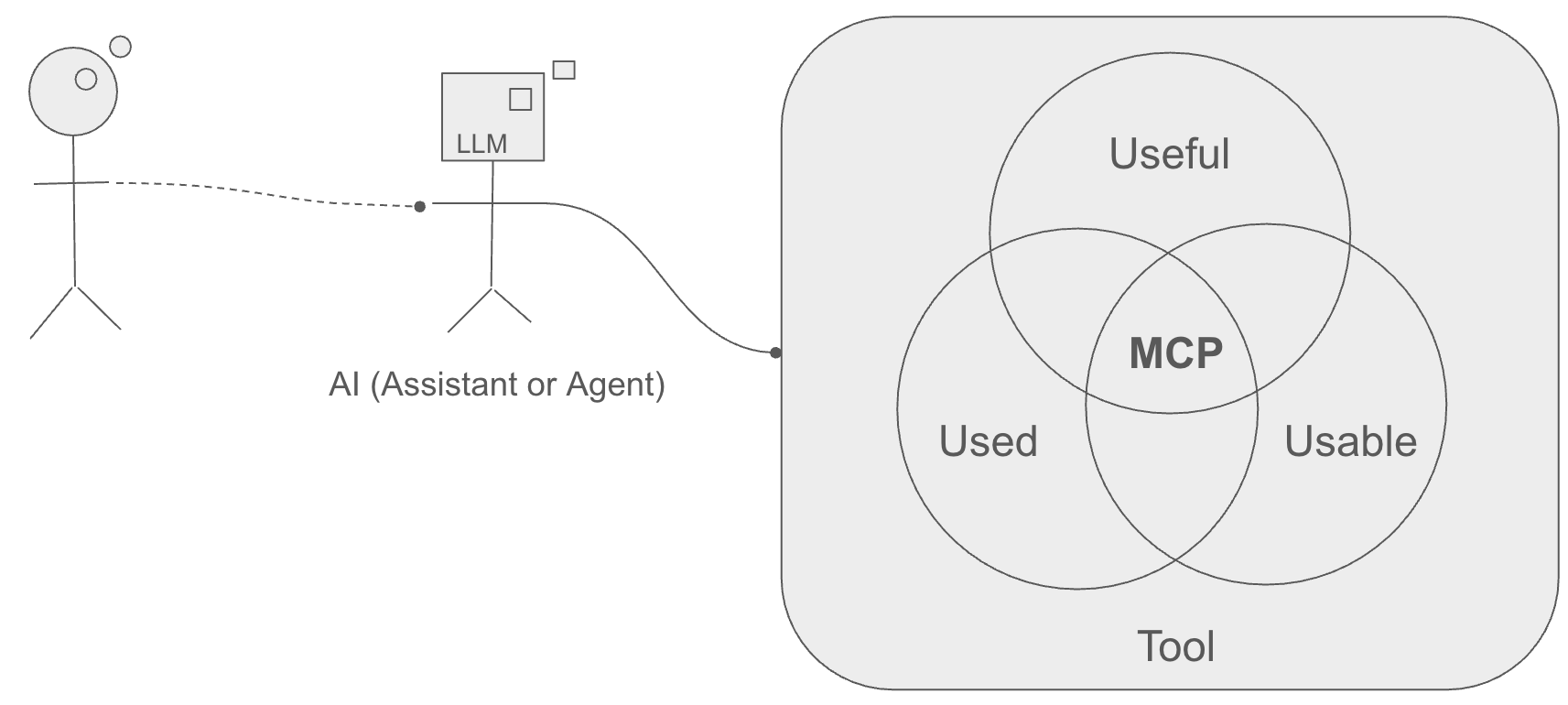
Illustration à travers un cas d’utilisation
Anthropic propose un outil appelé memory. Memory est un système basé sur un graphe de connaissances qui peut être utilisé pour partager des éléments entre contextes. Imaginez-le comme une base de données sans structure prédéfinie qui peut stocker des relations entre différentes entités.
Par exemple, vous pouvez stocker : “Les 3 U de MCP : Rendre un outil Utile, Utilisable et Utilisé par et pour un LLM” “écrit par” “Olivier”.
- “Les 3 U de MCP : Rendre un outil Utile, Utilisable et Utilisé par et pour un LLM” et “Olivier” sont des nœuds dans le graphe.
- “écrit par” est une arête.
L’entité {“Les 3 U de MCP : Rendre un outil Utile, Utilisable et Utilisé par et pour un LLM” “écrit par” “Olivier”} est un “triplet”, et une façon d’interagir avec le graphe de connaissances consiste à exposer des fonctions comme “add_triple” ou “get_triple”. Le service MCP peut alors exposer un ensemble de ressources pour récupérer des éléments basés sur leurs relations (par exemple, tous les éléments “écrits par” “Olivier”).
Cette approche est très puissante car elle est sans schéma prédéfini : vous pouvez stocker n’importe quel contenu dans un nœud et n’importe quelle relation entre deux nœuds.
Pour représenter les connaissances, seul un petit ensemble de fonctions est nécessaire :
- Création/Maintenance :
add_tripleetremove_triplevous permettent de construire et de maintenir le graphe. - Récupération :
find_triplesest un outil polyvalent pour récupérer des faits ou des modèles spécifiques. - Exploration :
describe_entityoffre la capacité essentielle de naviguer et comprendre le contexte autour de n’importe quel nœud, ce qui est crucial pour découvrir des insights et des relations dans une structure de graphe.
Nous pouvons alors laisser le LLM analyser un texte et créer une structure en conséquence. Par exemple, voici ce que j’ai demandé à Gemini (concernant l’article que vous lisez) :
simulez la création d'un graphe de connaissances en écrivant tous les appels à une fonction `add_triple(subject, predicate, object)` que vous feriez pour représenter cet article :
Depuis son annonce il y a quelques mois, le Model Context Protocol (MCP) a suscité une attention considérable.
...Sa réponse est :
# Concepts de base et définitions
add_triple("Model Context Protocol", "alias", "MCP")
add_triple("MCP", "description", "Un mécanisme pour donner aux LLM la capacité d'interagir de façon transparente avec leur environnement")
add_triple("MCP", "type", "Protocole")
add_triple("MCP", "objectifInitial", "Système de plugins pour LLM")
add_triple("MCP", "améliore", "assistants IA")
add_triple("MCP", "améliore", "agents IA")
# Évolution et étapes (Théorie de Wardley)
add_triple("MCP", "evolutionAnalysée Avec", "théorie de Wardley")
add_triple("Étape I", "label", "genesis")
add_triple("MCP", "établi", "certitude de solution")
add_triple("MCP", "entréDansPhase", "Phase II")
add_triple("Phase II", "label", "Custom Built")
add_triple("MCP", "adoption", "généralisée")
add_triple("Produits", "sontConçusAvec", "MCP") # Relation implicite en Phase II
add_triple("Produits", "développésAutour", "MCP") # Phase suivante mentionnée
# Interaction et configuration de l'auteur
add_triple("Auteur", "seConcentreSur", "explorer MCP")
add_triple("Auteur", "seConcentreSur", "identifier les problèmes que MCP peut résoudre")
add_triple("Auteur", "ablogué", "POC")
add_triple("POC", "type", "Preuve de Concept")
add_triple("POC", "développéDurant", "Étape I")
add_triple("Auteur", "interagitAvec", "IA")
...Jusqu’ici, tout va bien… et ça a fonctionné. L’utilisation de l’outil MCP crée effectivement un fichier avec ce contenu que je peux ensuite interroger en demandant :
Qu’est-ce que MCP améliore selon le graphe ?
MCP améliore les assistants IA et les agents IAL’outil est donc Utile… mais est-il vraiment utilisable ? Prenez la ligne suivante :
add_triple("MCP", "evolutionAnalyséeAvec", "théorie de Wardley")
Si je demande dans une nouvelle session de mettre à jour la mémoire avec une autre analyse d’article, comment puis-je être sûr qu’il utilisera “evolutionAnalyséeAvec” et non un autre terme ?
Par exemple, j’ai posé la même question au même LLM dans un autre contexte, et j’ai reçu cette réponse :
add_triple("théorie de Wardley", "appliquée_à", "évolution MCP")
Cette incohérence est problématique. Le LLM, en essayant d’être utile, invente des termes de relation (evolutionAnalyséeAvec, appliquée_à) qui semblent raisonnables isolément mais conduisent à un graphe de connaissances fragmenté et peu fiable avec le temps. Les requêtes deviennent difficiles car on ne sait pas quel terme prédicat a été utilisé. Le problème fondamental est l’absence d’une structure prédéfinie ou d’un vocabulaire pour les relations que le LLM crée. L’implémentation du graphe de connaissances, bien que flexible, n’est pas sémantiquement affordante – elle ne guide pas le LLM sur comment structurer les connaissances de façon cohérente.
Ontologie, la partie manquante
C’est là qu’une ontologie entre en jeu. Une ontologie agit comme un schéma formel ou un vocabulaire contrôlé pour le graphe de connaissances. Elle définit explicitement :
- Classes : Les types d’entités autorisés (par exemple,
Protocole,Théorie,Personne,Article). - Propriétés (Prédicats) : Les relations autorisées entre ces classes (par exemple, définir un seul prédicat spécifique comme
analyséAvecau lieu de permettre des variations commeevolutionAnalyséeAvecouappliquée_à). - Contraintes : Potentiellement, des règles sur la façon dont les classes et les propriétés peuvent être combinées (par exemple, seule une
Personnepeut être l’objet d’un prédicatécritParprovenant d’unArticle).
En définissant quels prédicats sont valides et quels types de nœuds ils peuvent connecter, une ontologie fournit les contraintes nécessaires. Elle guide le LLM à utiliser des termes standardisés, assurant que les connaissances ajoutées au graphe sont cohérentes et interrogeables, indépendamment du texte d’entrée ou de la session. Elle impose essentiellement un accord sémantique, résolvant directement le problème de l’invention incohérente de prédicats.
Mais quel rapport avec les Prompts MCP ?
Eh bien, comme je le ferais avec un collègue, je peux expliquer ce que j’attends et les bases d’une ontologie à mon IA.
Par exemple, je pourrais fournir ce prompt à mon LLM, et il produirait une réponse très similaire pour le texte (selon sa capacité à analyser le texte, mais la formalisation de la sortie serait la même) :
Votre tâche est d'analyser le texte suivant et d'extraire les relations selon une ontologie spécifique.
**Règles d'ontologie :**
1. Identifiez des entités de type 'Person', 'Manager' et 'Team'.
2. Extrayez des relations *uniquement* si elles correspondent à ces modèles :
* Type de sujet : Person, Prédicat : 'worksFor', Type d'objet : Manager
* Type de sujet : Person, Prédicat : 'isMemberOf', Type d'objet : Team
* Type de sujet : Team, Prédicat : 'hasLeader', Type d'objet : Manager
3. Représentez les noms d'entités aussi précisément que possible à partir du texte.
**Action requise :**
Pour *chaque* relation valide que vous identifiez qui se conforme strictement aux règles d'ontologie ci-dessus, vous **devez** appeler l'action ` + "`InsertTriple`" + `.
* Utilisez les noms d'entités identifiés pour ` + "`subject`" + ` et ` + "`object`" + `.
* Utilisez le prédicat correspondant ('worksFor', 'isMemberOf', 'hasLeader').
N'insérez pas de triplets pour des relations ou des types d'entités non explicitement mentionnés dans les règles d'ontologie. Assurez-vous que les types du sujet et de l'objet correspondent à la règle pour le prédicat utilisé.
Voici le texte à analyser :`
...L’idée derrière le prompt MCP est d’encoder ce texte et de le servir à la demande.
Comment ça fonctionne ?
Le serveur MCP expose un prompt “command” qui prend un argument, qui est le texte à analyser.
La “command” ici s’appelle extract-relations-from-text (je l’utilise uniquement comme validation du concept). Sa description est importante pour la rendre utilisable, mais gardons cela pour plus tard, car j’encouragerai mon LLM à l’utiliser.
Voici un exemple d’implémentation avec mcp-go, fourni à titre d’illustration :
return mcp.NewPrompt("extract-relations-from-text",
mcp.WithPromptDescription("Analyzes text to extract Person-Manager-Team relationships according to a specific ontology and inserts them as triples using InsertTriple."),
mcp.WithArgument("input",
mcp.ArgumentDescription("The text containing information about people, managers, teams, and their relationships."),
mcp.RequiredArgument(),
),Lorsque le LLM, fonctionnant dans le Moteur d’Inférence, signale son intention d’utiliser un prompt MCP (comme extract-relations-from-text), le middleware reçoit ce signal. Le middleware récupère alors le texte du prompt réel du serveur d’outils MCP. Ensuite, le middleware intègre ce texte de prompt avec les données utilisateur d’origine dans une nouvelle requête correctement formatée et l’envoie au Moteur d’Inférence. Le Moteur d’Inférence traite alors cette requête, fournissant les instructions injectées et les données au LLM. Le LLM suit ces instructions, et ses décisions résultantes (comme vouloir appeler inset_triple) sont interprétées par le Moteur d’Inférence, qui renvoie les requêtes d’action structurées au middleware pour exécution via le serveur MCP.
Démo…
J’ai implémenté ce serveur MCP (https://github.com/owulveryck/mcpkg) et je l’utilise avec mon openaiserver avec Big-AGI comme frontend. Pour les besoins de cette démo, je n’ai pas écrit de prompt système spécifique ; à la place, j’instruis directement mon LLM à utiliser le prompt.
extrais les relations Personne-Manager-Équipe de ce texte :
Les lumières fluorescentes de "Innovate Solutions Inc." bourdonnaient, une toile de fond constante au chaos tranquille du département Marketing. À la barre se trouvait Anya Sharma, la Directrice Marketing, un tourbillon d'énergie et de pensée stratégique. Anya rapportait directement à M. Thompson, le PDG, un homme dont la présence se faisait surtout sentir par des emails laconiques et des visites occasionnelles au bureau provoquant de l'anxiété.
Sous Anya se trouvaient deux chefs d'équipe : Ben Carter et Chloe Davis. Ben, un spécialiste du marketing chevronné avec un don pour l'analyse de données, dirigeait l'équipe d'Analyse et d'Insights. Son équipe était composée de deux analystes juniors : Raj Patel, un récent diplômé débordant d'enthousiasme, et Sarah Chen, une chercheuse méticuleuse avec une capacité étonnante à repérer les tendances. Ben se retrouvait souvent à arbitrer entre l'empressement de Raj à mettre en œuvre chaque nouvelle idée et l'approche prudente, basée sur les preuves, de Sarah.
...J'ai traité le texte et extrait les relations Personne-Manager-Équipe basées sur les règles d'ontologie que vous avez fournies. J'ai inséré les triplets suivants dans le graphe de connaissances :
* Anya Sharma worksFor M. Thompson
* Ben Carter worksFor Anya Sharma
* Chloe Davis worksFor Anya Sharma
* équipe d'Analyse et d'Insights hasLeader Ben Carter
* Raj Patel isMemberOf équipe d'Analyse et d'Insights
...En coulisses, il a reçu le prompt du serveur MCP, l’a analysé et a appelé les actions add_triple du serveur MCP en conséquence. J’ai un fichier nommé my_knowledge avec toutes ces informations, que je peux partager entre contextes ou avec l’assistant d’un autre collègue.
Lorsque ce serveur deviendra un produit à part entière, les prochaines fonctionnalités seraient de créer un modèle de prompt approprié qui répond à différents types d’ontologies en fonction des arguments, peut-être en utilisant schema.org comme référence. Je publierai un article à ce sujet si cet outil évolue selon mes besoins.
Conclusion : Concevoir des produits pour l’utilisateur IA
Finalement, un serveur MCP est plus qu’un simple code connectant un LLM à une capacité ; c’est un produit numérique à part entière. Cependant, c’est un produit conçu pour un type d’utilisateur unique : non pas un humain naviguant sur une interface graphique, mais une IA interagissant par le langage et des appels structurés. Cette différence fondamentale modifie le paradigme de conception.
Pour les développeurs de logiciels et les propriétaires de produits, comprendre ’l’affordance’ prend une nouvelle dimension. Il ne s’agit plus uniquement d’indices visuels ou de mises en page intuitives pour les humains. Au lieu de cela, il s’agit de créer des descriptions textuelles claires, de définir des fonctions précises (Actions/Ressources) et, crucialement, de concevoir des Prompts MCP intelligents. Ces prompts doivent communiquer efficacement ce que fait un outil, pourquoi il est utile pour une tâche spécifique (son application potentielle comme solution), et comment l’IA devrait l’utiliser correctement et de manière cohérente, souvent guidée par des structures sous-jacentes comme les ontologies.
Comme l’illustre l’exemple du graphe de connaissances, sans cette guidance sémantique soigneusement conçue—rendant le but de l’outil et son utilisation correcte évidents pour l’IA—même un outil techniquement utilisable peut échouer à être fiablement utile ou constamment utilisé.
Reconnaître l’IA comme l’utilisateur final et concevoir pour ses besoins d’interprétation uniques à travers des interfaces MCP bien structurées, en particulier les prompts, est donc crucial. C’est fondamental pour appliquer avec succès ces puissantes capacités d’IA comme solutions à des problèmes du monde réel, comme envisagé par les créateurs de produits. Ce n’est qu’en comprenant et en agissant sur cette nouvelle exigence d’affordance centrée sur l’IA que les développeurs et les propriétaires de produits peuvent s’assurer que leurs outils basés sur MCP atteignent leur plein potentiel et deviennent vraiment des composants efficaces de l’écosystème IA.
Prochain sur ma liste de choses à essayer : les notifications, pour vraiment transformer mon assistant en agent, lui permettant de réagir aux événements.