Data-as-a-Product: la pierre angulaire du data-mesh
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
Note: ceci est une traduction de l’article que j’ai publié l’année dernière en français sur le Blog OCTO “Data-as-a-product: pierre angulaire du Data-Mesh”
Exploiter les données à grande échelle : un enjeu stratégique ?
Dans son livre Empowered, Marty Cagan cite quatre éléments essentiels d’une approche orientée produit :
- Le premier est d’être prêt à faire des choix difficiles sur ce qui est vraiment important.
- Le deuxième implique de générer, identifier et exploiter l’information pour guider ces choix.
- Le troisième consiste à transformer les idées en action.
- Et le quatrième implique une gestion active des personnes/équipes sans recourir au micromanagement.
Faire des choix signifie accepter que tout n’est pas également important. Le rôle fondamental de l’exploitation des données est d’éclairer et de guider ces choix.
C’est l’objectif de la Business Intelligence (BI), qui fait partie du monde numérique analytique. Il s’agit de créer des tableaux de bord, des projections pour prendre les décisions les plus pertinentes, et de faire émerger des idées qui se transformeront en actions.
Ce sont des projections visuelles des connaissances que l’entreprise a accumulées et diffusées dans les données collectées au fil du temps.
De plus, dans le monde numérique qui permet les opérations commerciales (comme un système de commerce électronique), l’exploitation de ces données par des programmes promet que les automatisations peuvent partiellement autopiloter les activités opérationnelles, par exemple, en aidant le consommateur dans ses propres décisions.
L’entreprise aura alors un ensemble de produits numériques en son cœur, liés aux données.
Le défi sera d’organiser les données pour augmenter l’efficacité des équipes.
Cet article propose de définir les deux concepts de produit de données et de données-en-tant-que-produit comme fondement sémantique pour les équipes souhaitant travailler sur l’urbanisation de leurs actifs de données. Ensuite, nous verrons comment ces deux concepts peuvent être concrètement déclinés pour soutenir une stratégie d’entreprise.
Langage ubiquitaire dans cet article
Produit
Un produit, au sens large, est une structure d’origine artificielle conçue pour résoudre un problème spécifique.
Un produit numérique est une variante des produits technologiques. Pour atteindre son objectif, il doit :
- Être techniquement faisable.
- Durer dans le temps, au moins aussi longtemps que le besoin existe.
- Fournir une valeur intrinsèque.
- Être utilisable par les personnes concernées par la résolution du problème. Dans un produit numérique, l’interface utilisateur est le lien entre l’utilisateur (humain) et les fonctionnalités offertes par le produit.
Système opérationnel
Un ensemble d’éléments numériques permettant les opérations commerciales.
Système analytique
Un ensemble d’éléments numériques permettant la prise de décision commerciale.
Produits et données
Dans cette partie, nous explorerons deux concepts :
-
Le produit de données, qui vise à résoudre un problème dans un domaine spécifique (c’est une solution numérique à un problème, pilotée par les données).
-
Les données-en-tant-que-produit, qui fournissent des solutions pour la gestion des données afin de permettre aux produits de données de remplir leurs tâches (c’est une solution au problème de rendre les données disponibles à l’échelle de l’entreprise, conçue pour faciliter le développement de produits de données).
Produit de données
Utilisons le travail de DJ Patil comme fondement :
Pour commencer, pour moi, une bonne définition d’un produit de données est un produit qui facilite un objectif final grâce à l’utilisation de données.
Data Jujitsu - The art of turning data into product - DJ Patil - 2012
Nous définissons un produit de données comme un produit qui atteint son objectif grâce à l’utilisation de données.
Dans un système analytique, un produit de données peut prendre la forme d’un rapport pour prendre des décisions éclairées.
Dans un système opérationnel, un produit de données pourrait être, par exemple, un système de recommandation de produits dans un contexte de commerce électronique.
Données-en-tant-que-produit
Les données-en-tant-que-produit sont un concept issu du monde du data-mesh, formalisé par Zhamak Dehghani. Dans le contexte du data-mesh, le terme ‘données’ représente également un ensemble d’éléments dont les significations sont définies par un ensemble de règles sémantiques (la définition est la même que dans le contexte d’un produit de données, car elle fait référence aux mêmes données).
Transformer les données en données-en-tant-que-produit implique d’appliquer les principes de la pensée produit directement aux données. Le problème que nous visons à résoudre avec les données-en-tant-que-produit est le besoin des produits de données d’avoir des données fiables, de qualité, accessibles et dignes de confiance.
Par conséquent, les données-en-tant-que-produit sont bien plus qu’un simple “ensemble de données”. La meilleure façon de décrire un produit est par ce qu’il fait, plutôt que par ce qu’il est, nous allons donc énumérer ses caractéristiques uniques et les fonctions qu’il offre (ce concept est connu sous le nom d’affordance).
(Ces affordances sont expliquées en détail dans le livre de Zhamak Dehghani “Data Mesh”.)
Affordance 1 : Servir les données
C’est évident : les données-en-tant-que-produit exposent des données. Ces données sont exposées via des interfaces clairement définies. Les données fournies sont en lecture seule pour garantir l’idempotence des opérations consommant les données (comme les systèmes d’analyse ou les systèmes d’apprentissage automatique, par exemple).
Affordance 2 : Consommer les données
Pour offrir sa valeur, les données-en-tant-que-produit consomment des données de diverses sources. Les données sources peuvent provenir de différents systèmes tels que :
- Systèmes opérationnels (bases de données)
- Autres données-en-tant-que-produits
- Systèmes externes
Affordance 3 : Transformer les données
L’essence même des données-en-tant-que-produit est de proposer de nouvelles données. Les données-en-tant-que-produit doivent offrir aux développeurs la capacité de transformer les données consommées de multiples façons, comme à travers du code, l’application de modèles d’apprentissage automatique, ou par des requêtes complexes.
Affordance 4 : Découvrir et comprendre le sens des données
Les données-en-tant-que-produit exposent toutes les informations nécessaires pour que les utilisateurs puissent découvrir, comprendre et utiliser les données-en-tant-que-produit en toute confiance.
Affordance 5 : Offrir des fonctions de maintenance et de gestion du cycle de vie du produit
Au-delà de simplement fournir des informations (affordance 1), les données-en-tant-que-produit doivent offrir des fonctions de maintenance qui permettent des mises à jour faciles du produit sans interférer avec l’affordance 1. Par exemple, en offrant une fonction de versionnage du code de transformation des données, ou un système de documentation.
Affordance 6 : Observabilité du produit
Il est nécessaire de pouvoir observer ce qui se passe à l’intérieur des données-en-tant-que-produit. Les objectifs de cette observabilité sont variés, tels que :
- Permettre aux opérateurs de comprendre et d’analyser les résultats des processus de transformation (affordance 3)
- Permettre aux analystes et aux développeurs de comprendre le parcours des données (lignage, ou la transition de l’affordance 2 à l’affordance 1)
Affordance 7 : Un produit contrôlable
Pour rappel, la gouvernance des données structure les règles de gestion des données et de conformité avec les réglementations en place. La gouvernance assure la mise en œuvre de ces règles ; cependant, son rôle n’est pas de contrôler et de sanctionner le non-respect des règles. Le produit doit offrir des capacités de gestion transversale pour permettre à un système externe au domaine d’agir sur les données. Cette affordance est destinée aux équipes de gouvernance et de sécurité, mais aussi aux équipes de développement pour faciliter la mise en œuvre des règles de gouvernance. Ainsi, il peut offrir la capacité d’annihiler des données personnelles en permettant la suppression d’une clé de chiffrement, par exemple, ou la possibilité de gérer des politiques d’accès aux données selon les profils individuels.
Mise en œuvre des données-(en-tant-que-)produits
La mise en œuvre réussie de produits (numériques) repose sur ces éléments :
- La mise en œuvre doit se concentrer sur la résolution de problèmes, et non sur l’ajout de fonctionnalités.
- Le produit doit être conçu de manière collaborative (entre business et tech) et non séquentielle (comme l’expression des besoins suivie de la mise en œuvre).
Pour les produits numériques aidant à la prise de décision (produits analytiques et/ou d’apprentissage automatique), une représentation systémique pourrait être illustrée par l’échafaudage suivant :
- Définition d’une stratégie d’entreprise qui s’appuie sur les données pour atteindre un objectif (quel est mon business data-driven).
- Initiatives commerciales pour soutenir la stratégie d’entreprise (quel est le plan d’action pour atteindre les objectifs).
- Applications (produits de données) en réponse aux besoins exprimés par ces initiatives (fournir les outils pour avancer dans la réalisation des objectifs).
- Données (données-en-tant-que-produit) qui répondent aux besoins des produits de données (mettre à disposition les données qui permettent de générer, identifier et exploiter l’information pour propulser les outils).
- Une plateforme comme fondement pour le développement et l’exécution de ces données-en-tant-que-produits (disposer des éléments technologiques pour matérialiser et exploiter ces solutions).
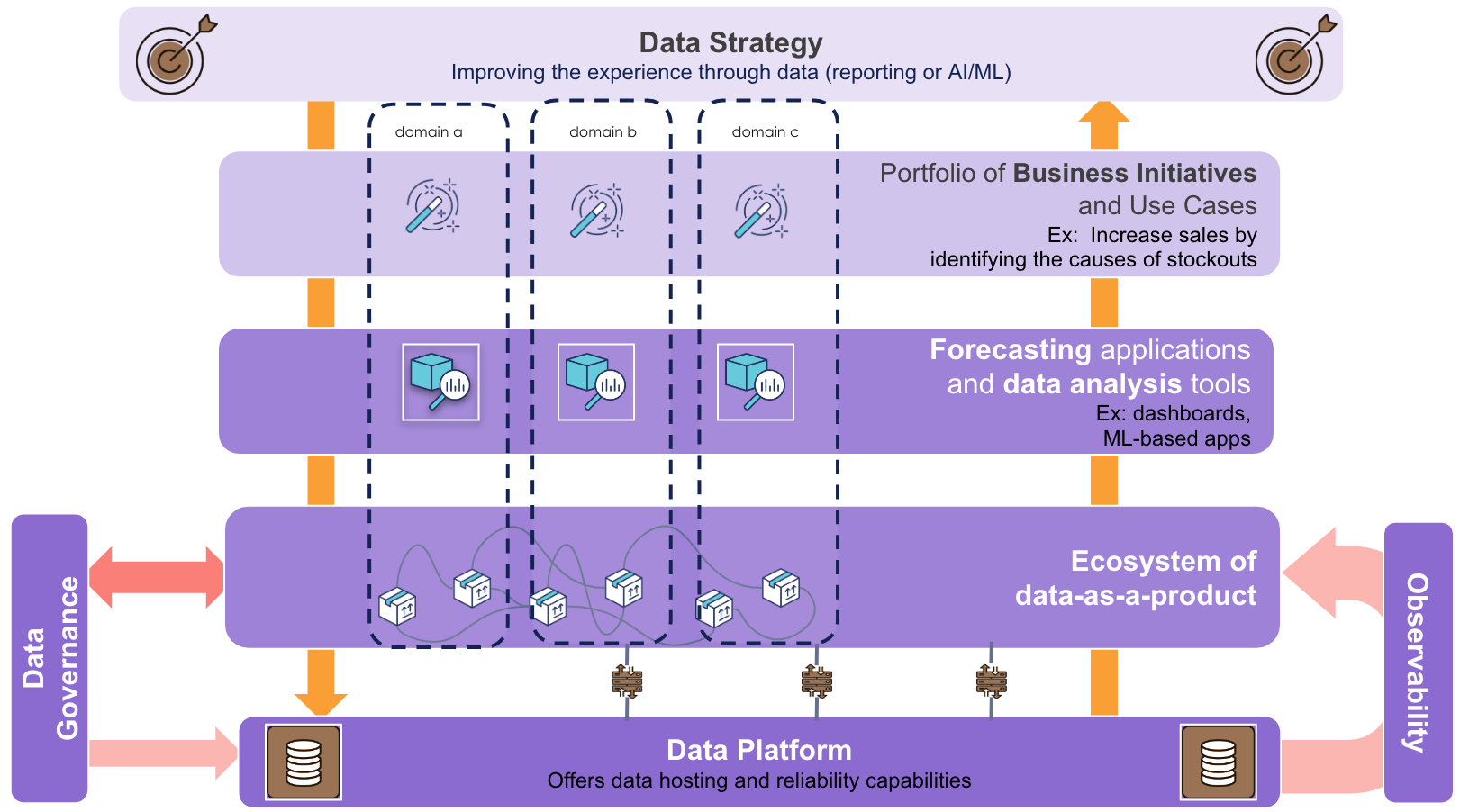
Note : La couche écosystème des données-en-tant-que-produit qui montre le maillage dépasse le cadre de cet article, qui se concentre sur la mise en œuvre pratique de l’un des éléments et non sur la mise en œuvre globale du data-mesh.
Déterminer les cas d’utilisation
Les projets de réalisation numérique s’appuient généralement sur des cas d’utilisation pour s’assurer que la finalité s’aligne sur un besoin métier. Considérons la définition suivante de Wikipedia :
Un cas d’utilisation, en ingénierie logicielle et en ingénierie des systèmes, définit une façon d’utiliser un système qui a une valeur ou une utilité pour les acteurs impliqués. Le cas d’utilisation correspond à un ensemble d’actions réalisées par le système en interaction avec les acteurs vers un objectif. L’ensemble des cas d’utilisation décrit ainsi les exigences fonctionnelles d’un système du point de vue et du langage de l’utilisateur final.
Les cas d’utilisation relèvent généralement de la responsabilité des domaines métier (un domaine ici définit une activité spécifique avec ses propres concepts et vocabulaire ; par exemple, la logistique dans le monde de la distribution).
Avant tout, il est essentiel de s’assurer que les cas d’utilisation présentent un réel intérêt pour la stratégie d’entreprise et que la solution fournie par la mise en œuvre apporte une valeur significative. Par exemple, en logistique, un cas d’utilisation visant à détecter les perturbations de la chaîne d’approvisionnement alors que la stratégie commerciale consiste à liquider les stocks n’ajoute pas de valeur (niveaux 1 et 2 de l’échafaudage).
Comme nous l’avons vu précédemment, un produit doit fournir une valeur intrinsèque ; un bon modèle architectural est que les données-en-tant-que-produit servent plusieurs cas d’utilisation et donc plusieurs produits de données pour éviter que sa valeur ne s’exprime qu’à travers le cas d’utilisation défini.
Positionner les cas d’utilisation sur une carte pour identifier les données-en-tant-que-produits
Note : Une carte Wardley est un outil utilisé pour prendre des décisions d’orientation commerciale en cartographiant et en étudiant l’évolution des actifs spécifiques à une entreprise. Les actifs (composants), qui peuvent être tangibles comme des logiciels ou des données, ou abstraits comme des activités, sont placés verticalement sur une chaîne de valeur. Ce placement représente l’importance des composants par rapport à un point de référence spécifique (plus on est éloigné, moins c’est visible, donc la valeur de l’actif du point de vue de la référence devrait être moindre). Les actifs sont ensuite placés sur un axe horizontal qui représente les étapes d’évolution de ces éléments (dont la définition change selon le type d’actif).
À titre d’illustration, un atelier basé sur les cartes de Simon Wardley pourrait donner le résultat suivant (c’est un exemple fictif) :
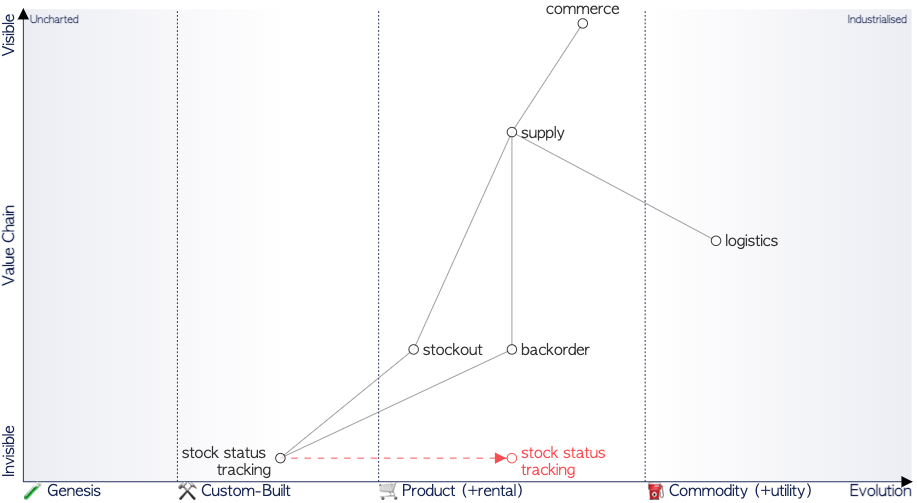
Alors qu’une carte Wardley permet de situer une entreprise dans son marché, ici nous zoomons pour représenter une activité dans le contexte de l’entreprise. Ainsi, sur la carte présentée ici, un besoin de données-en-tant-que-produit émerge, exposant le suivi de l’état des stocks.
Explication : Le commerce a besoin de suivre les approvisionnements, et le fait qu’il soit très visible depuis le commerce (entre le commerce et l’approvisionnement sur l’axe vertical) montre que c’est une stratégie de l’entreprise (où c’est moins visible depuis la chaîne d’approvisionnement). Pour suivre l’approvisionnement, il faut des produits qui gèrent les ruptures de stock ainsi que les commandes en attente. Ces composants utiliseront des données de l’état des stocks, qui sera en phase II d’évolution et évoluera vers un produit (phase III) au fil des itérations. En phase II, les données sont non modélisées, et chacun des composants de rupture de stock et de commande en attente utilise sa version des données de suivi des stocks. Rationaliser l’usage permettra de gérer les données comme un produit qui apporte de la valeur.
| Évolution | I | II | III | IV |
|---|---|---|---|---|
| Données | Non modélisées | Divergentes | Convergentes | Modélisées |
| Activité | Genèse | Sur mesure | Produit | Commodité |
Déterminer les frontières sémantiques des données
Une fois le besoin pour les données-en-tant-que-produit établi, il est important de déterminer leur usage sémantique. Dans le paradigme du data-mesh, les données-en-tant-que-produit appartiennent à un domaine métier et en sont responsables. S’inspirant des méthodes de Domain-Driven Design (DDD), nous pouvons déterminer les frontières sémantiques des données-en-tant-que-produit en les assimilant à un contexte délimité.
Ainsi, un atelier d’event-storming devrait nous permettre de déterminer le vocabulaire ubiquitaire dans les données-en-tant-que-produit et de définir :
- Quelles données sont produites
- Comment elles sont mises à disposition
- Le cycle de vie des données
- Quelles données sont consommées par ce produit
- Les règles de calcul, de transformation, d’agrégation et de déclenchement interne du produit
Entrer dans le cycle de développement du produit
Une fois le cadre fonctionnel établi, le cycle de développement commence. Comme nous l’avons vu dans la première partie, les données-en-tant-que-produit, caractérisées par leurs affordances, sont bien plus qu’un simple ensemble de données. Par conséquent, pour rendre le produit utile, utilisable et utilisé, ajoutant ainsi de la valeur au business, il est nécessaire de développer et de standardiser certaines de ces affordances.
Publication des métadonnées du produit
La publication des quatre premières affordances (servir les données, consommer les données, transformer les données et découvrir et comprendre le sens des données) implique la rédaction d’un manifeste (décrit dans le chapitre 14 du livre de Zhamak Dehghani).
Parmi les informations essentielles dans ce manifeste figurent :
- L’URI où les données produites par les données-en-tant-que-produit peuvent être consommées.
- Une description des ports de sortie du produit, qui servent deux objectifs : décrire comment accéder aux données et permettre la mise à disposition des ressources nécessaires (nous reviendrons sur ce point avec le concept de plateforme).
- Documents d’objectifs de niveau de service (SLO) pour exposer le niveau de service visé pour chaque port de sortie.
- Ports d’entrée qui décrivent l’origine et le mode de récupération des données sources.
- La politique interne de gestion des données (rétention, confidentialité, etc.).
- Tout actif supplémentaire nécessaire au fonctionnement du produit (par exemple, les données entraînées d’un algorithme de ML). Standardiser le format du manifeste facilitera la consommation des données-en-tant-que-produit à l’échelle de l’entreprise. De plus, l’utilisation d’un système de sérialisation comme JSON ou YAML facilitera l’utilisation des données par des systèmes externes.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://mycompany.com/data-as-a-product.schema.json",
"title": "Data-as-a-product Manifest",
"description": "Define the specification and the configurations required to do its job ",
"type": "object",
"properties": {
"dataProductURI": {
"description": "The unique identifier for a product",
"type": "string"
},
"productName": {
"description": "Name of the product",
"type": "string"
}
},
"outputPorts": {
"description": "Output ports for the product",
"type": "array",
"items": {
"type": "object"
},
"minItems": 1,
"uniqueItems": true
} ,
//...
"required": [ "dataProductURI", "outputPorts" ]
}Exemple de manifeste
Le code de génération
Une autre partie fondamentale des données-en-tant-que-produit est le code qui génère les données. Il conviendra d’adopter de bonnes pratiques en matière de versionnage et de génération de code, et d’utiliser des techniques de déploiement issues de l’expérience acquise dans le monde opérationnel. Ainsi, la mise en place de fabriques de déploiement logiciel, de chaînes CI et d’automatisation des tests garantira un niveau de qualité optimal des données-en-tant-que-produit. Des outils tels que DBT ou Dataform faciliteront l’application de ces pratiques (et à l’avenir, des langages comme PRQL permettront une gestion de plus en plus meilleure du code de génération de données).
La plateforme
Élément crucial du paysage numérique, la plateforme de données facilite le développement, le déploiement et l’utilisation des données-en-tant-que-produits. Nous adoptons les principes décrits par Evan Bottcher et définissons la plateforme comme un ensemble d’APIs en libre-service, de services, de connaissances et de support qui permettent leur utilisation ; ces composants sont organisés comme un produit interne destiné aux équipes de livraison autonomes.
Dans le contexte du développement de données-en-tant-que-produits, la plateforme fournira des services d’hébergement de données compatibles avec la définition des ports de sortie, ainsi que des systèmes de calcul qui exécuteront le cœur des données-en-tant-que-produit, comme un moteur SQL tel que BigQuery sur GCP, Redshift sur AWS, ou Snowflake. Cependant, il faut veiller à ne pas confondre les services fournis par le fournisseur de cloud avec la plateforme elle-même. En effet, la plateforme est un produit interne qui répond à des besoins spécifiques. Les capacités offertes par les fournisseurs de cloud sont en quelque sorte des facilitateurs qui facilitent la mise en œuvre du produit.
La plateforme se construit progressivement en fonction des besoins exprimés par les données-en-tant-que-produits. La plateforme viable la plus mince (TVP) capable de soutenir les affordances du produit pourrait très bien être un système documentaire bien organisé pour héberger le manifeste précédemment décrit (le concept de TVP est décrit dans le livre “Team Topologies”).
Conclusion
La mise en œuvre de données-en-tant-que-produit doit apporter une valeur intrinsèque ;
La méthode décrite dans cet article est un exemple de chemin pour atteindre cette valeur. Cette méthode n’est pas destinée à être exhaustive ou exclusive ; elle combine un ensemble d’éléments qui se sont avérés efficaces dans la mise en œuvre de produits logiciels opérationnels au cours des dernières années.
Si la valeur commerciale des données-en-tant-que-produit est immédiatement réalisée par la mise en œuvre de cas d’utilisation, c’est l’interconnexion de ces cas qui apportera un avantage concurrentiel au niveau de l’entreprise. Cet avantage se verra :
- dans le temps réduit pour mettre en œuvre de nouveaux cas d’utilisation (avec la possibilité de tester plus facilement des solutions basées sur l’apprentissage automatique, par exemple)
- dans une meilleure organisation des connaissances au niveau de l’entreprise
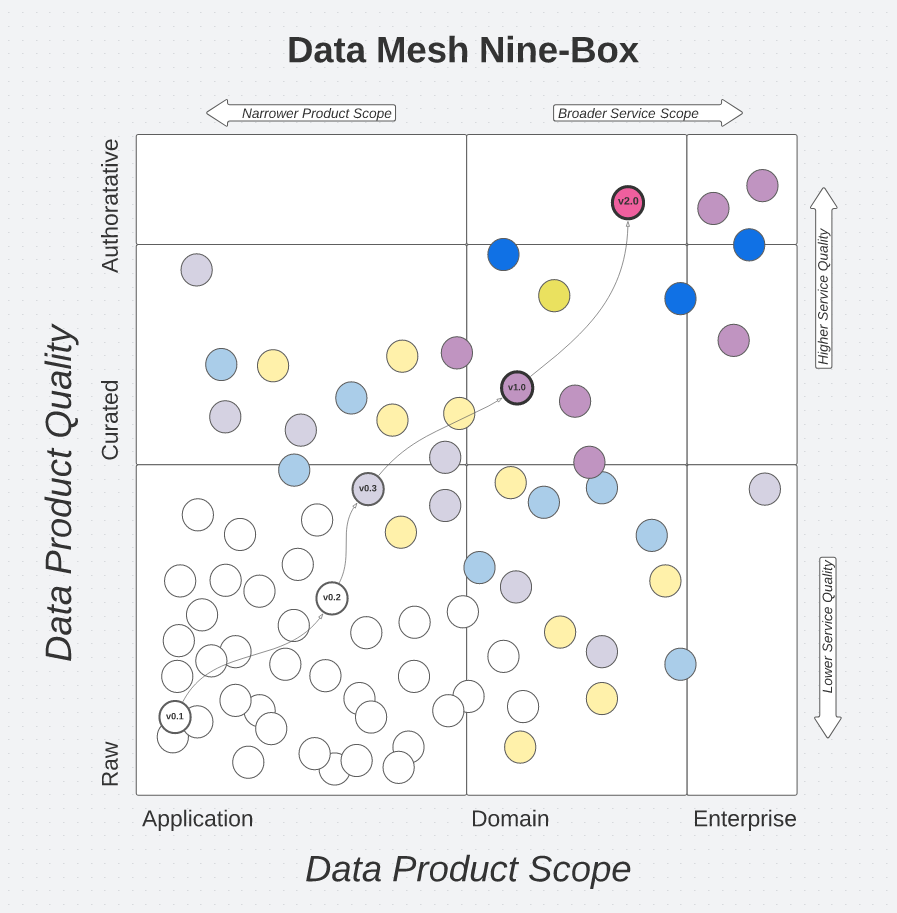
Par exemple, l’illustration ci-dessus montre la contribution croissante de valeur au niveau de l’entreprise à mesure que des itérations sont faites sur des données-en-tant-que-produit. Enfin, concernant la plateforme, elle peut être construite en parallèle en posant les premières briques qui permettront l’échange de données entre produits.
L’émergence de nouveaux langages pour interagir avec les données (SQLX, PRQL) apporte un changement qui répondra mieux aux besoins spécifiques en construisant des solutions personnalisées tout en continuant à exploiter la puissance offerte par les fournisseurs de cloud.