Data-as-a-Product: the keystone of the data-mesh
Note: this is a translation of the article I published last year in French on the Blog OCTO “Data-as-a-product: pierre angulaire du Data-Mesh”
Exploiting Data on a Large Scale: A Strategic Issue?
In his book Empowered, Marty Cagan cites four essential elements of a product-oriented approach:
- The first is being ready to make tough choices about what is truly important.
- The second involves generating, identifying, and exploiting information to guide these choices.
- The third is about turning ideas into action.
- And the fourth implies active management of people/teams without resorting to micromanagement.
Making choices means accepting that not everything is equally important. The fundamental role of data exploitation is to enlighten and guide these choices.
It’s the purpose of Business Intelligence (BI), which is part of the analytical digital world. It involves creating dashboards, projections to make the most relevant decisions, and bringing forth ideas that will turn into actions.
These are visual projections of the knowledge that the company has accumulated and disseminated in the data collected over time.
Furthermore, in the digital world that enables business operations (like an e-commerce system), exploiting this data through programs promises that automations can partially self-pilot operational activities, for example, assisting the consumer in their own decisions.
The company will then have a set of digital products at its core, linked to the data.
The challenge will be to organize the data to increase team efficiency.
This article proposes to define the two concepts of data-product and data-as-a-product as a semantic foundation for teams wishing to work on the urbanization of their data assets. Then, we will see how these two concepts can be concretely declined to support a business strategy.
Ubiquitous Language in This Article
Product
A product, in a broad sense, is an artificially originated structure designed to solve a specific problem.
A digital product is a variant of technological products. To achieve its purpose, it must:
- Be technically feasible.
- Last over time, at least as long as the need exists.
- Provide intrinsic value.
- Be usable by the people concerned with solving the problem. In a digital product, the user interface is the link between the user (human) and the functionalities offered by the product.
Operational System
A set of digital elements enabling business operations.
Analytical System
A set of digital elements enabling business decision-making.
Products and Data
In this part, we will explore two concepts:
-
The data product, which aims to solve a problem in a specific domain (it’s a digital solution to a problem, driven by data).
-
Data-as-a-product, which provides solutions for data management to enable data-products to fulfill their tasks (it’s a solution to the problem of making data available at the scale of the enterprise, designed to facilitate the development of data-products).
Data Product
Let’s use the work of DJ Patil as a fundation:
To start, for me, a good definition of a data product is a product that facilitates an end goal through the use of data.
Data Jujitsu - The art of turning data into product - DJ Patil - 2012
We define a data-product as a product that achieves its purpose through the use of data.
In an analytical system, a data product might take the form of a report for making informed decisions.
In an operational system, a data product could be, for example, a product recommendation system in an e-commerce setting.
Data-as-a-product
Data-as-a-product is a concept from the data-mesh world, formalized by Zhamak Dehghani. In the context of data-mesh, the term ‘data’ also represents a set of elements whose meanings are defined by a set of semantic rules (the definition is the same as in the context of a data-product, as it refers to the same data).
Transforming data into data-as-a-product involves applying the principles of product thinking directly to the data. The problem we aim to solve with data-as-a-product is the need for data-products to have reliable, quality, accessible, and trustworthy data.
Consequently, data-as-a-product is much more than just a simple “data-set”. The best way to describe a product is by what it does, rather than what it is, so we will list its unique characteristics and the functions it offers (this concept is known as affordance).
(These affordances are explained in detail in Zhamak Dehghani’s book “Data Mesh”.)
Affordance 1: Serving Data
It’s obvious: data-as-a-product exposes data. This data is exposed via clearly defined interfaces. The provided data is read-only to guarantee the idempotence of operations consuming the data (such as analysis systems or machine learning systems, for example).
Affordance 2: Consuming Data
To deliver its value, the data-as-a-product consumes data from various sources. The source data can come from different systems such as:
- Operational systems (databases)
- Other data-as-a-products
- External systems
Affordance 3: Transforming Data
The very essence of data-as-a-product is to propose new data. The data-as-a-product must offer developers the ability to transform the consumed data in multiple ways, such as through code, the application of machine learning models, or through complex queries.
Affordance 4: Discovering and Understanding the Meaning of Data
The data-as-a-product exposes all necessary information so that users can discover, understand, and use the data-as-a-product confidently.
Affordance 5: Offering Maintenance Functions and Product Lifecycle Management
Beyond just providing information (affordance 1), the data-as-a-product must offer maintenance functions that allow for easy product updates without interfering with affordance 1. For example, by offering a function for versioning the data transformation code, or a system of documentation.
Affordance 6: Product Observability
It is necessary to be able to observe what is happening inside a data-as-a-product. The objectives of this observability are varied, such as:
- Allowing operators to understand and analyze the results of transformation processes (affordance 3)
- Allowing analysts and developers to understand the journey of the data (lineage, or the transition from affordance 2 to affordance 1)
Affordance 7: A Controllable Product
As a reminder, data governance structures the rules for data management and compliance with regulations in place. Governance ensures the implementation of these rules; however, its role is not to control and sanction non-compliance with the rules. The product must offer cross-management capabilities to allow an external system to the domain to act on the data. This affordance is intended for governance and security teams, but also for development teams to facilitate the implementation of governance rules. Thus, it can offer the ability to annihilate personal data by allowing the deletion of an encryption key, for example, or the possibility of managing data access policies according to individual profiles.
Implementation of Data-(as-a-)Products
The successful implementation of (digital) products relies on these elements:
- The implementation must focus on solving problems, not on adding features.
- The product should be designed collaboratively (between business and tech) and not sequentially (such as requirement expression followed by implementation).
For digital products aiding in decision-making (analytical and/or machine learning products), a systemic representation could be depicted by the following scaffold:
- Definition of a business strategy that relies on data to achieve a goal (what is my data-driven business).
- Business initiatives to support the business strategy (what is the action plan to achieve the objectives).
- Applications (data-products) in response to the needs expressed by these initiatives (providing the tools to advance in achieving the objectives).
- Data (data-as-a-product) that meets the needs of data-products (making available the data that enables generating, identifying, and exploiting information to propel the tools).
- A platform as the foundation for the development and execution of these data-as-a-products (having the technological elements to materialize and exploit these solutions).
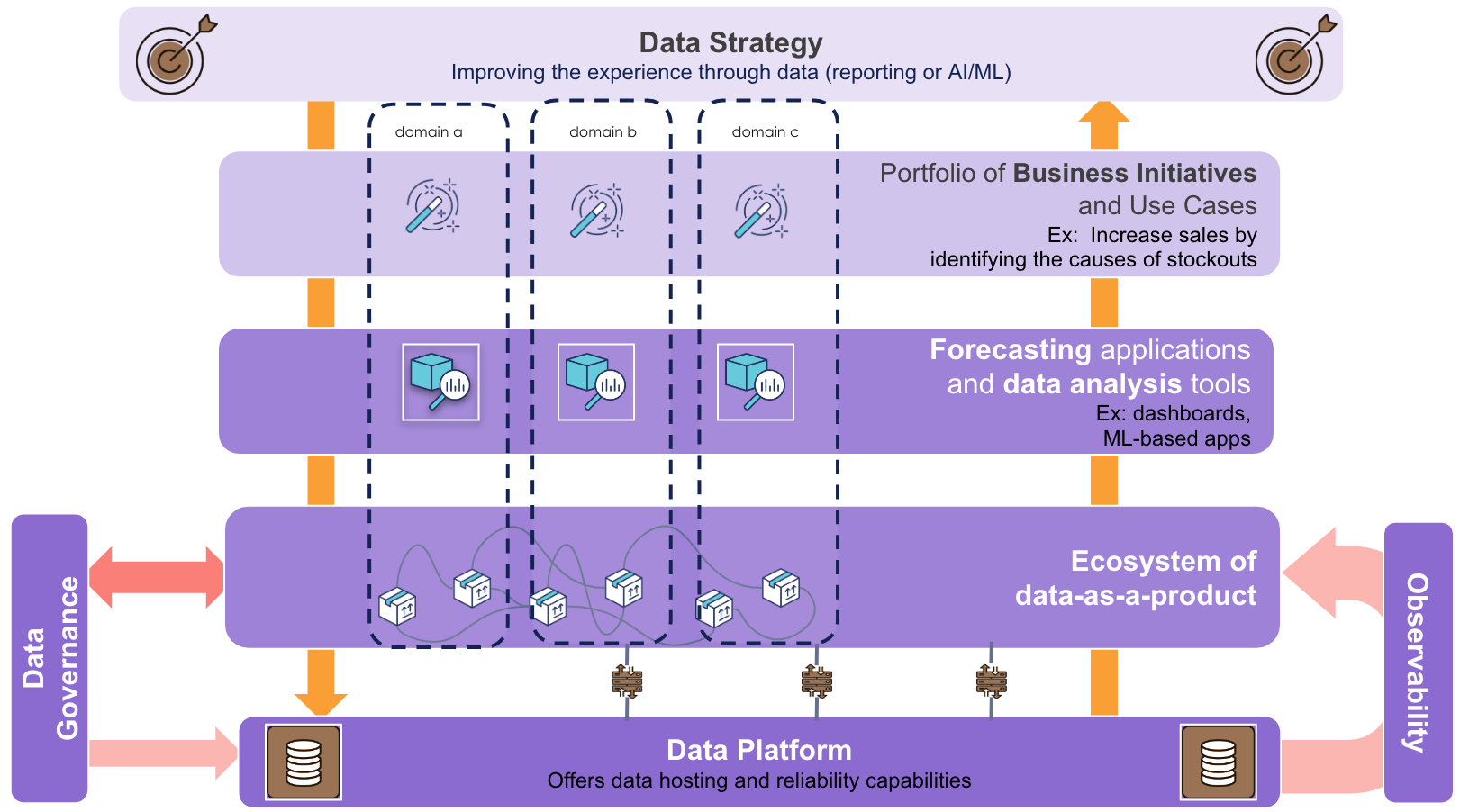
Note: The ecosystem layer of data-as-a-product that shows the mesh is beyond the scope of this article, which focuses on the practical implementation of one of the elements and not on the global implementation of data-mesh.
Determining Use Cases
Digital realization projects generally rely on use cases to ensure that the final purpose aligns with a business need. Let’s consider the following definition from Wikipedia:
A use case, in software engineering and systems engineering, defines a way of using a system that has value or utility for the involved actors. The use case corresponds to a set of actions performed by the system in interaction with the actors towards a goal. The set of use cases thus describes the functional requirements of a system from the perspective and language of the end user.
Use cases are generally the responsibility of business domains (a domain here defines a specific activity with its own concepts and vocabulary; for example, logistics in the retail world).
Before anything else, it’s essential to ensure that the use cases present real interest for the business strategy and that the solution provided by the implementation adds significant value. For example, in logistics, a use case aimed at detecting supply chain disruptions while the business strategy is to liquidate stocks does not add value (levels 1 and 2 of the scaffold).
As we’ve seen before, a product must provide intrinsic value; a good architectural pattern is that the data-as-a-product serves multiple use cases and thus multiple data-products to avoid its value being expressed only through the defined use case.
Positioning Use Cases on a Map to Identify Data-as-a-Products
Note: A Wardley map is a tool used for making business orientation decisions by mapping and studying the evolution of assets specific to a company. The assets (components), which can be tangible like software or data, or abstract like activities, are placed vertically on a value chain. This placement represents the importance of the components relative to a specific reference point (the further away we are, the less visible it is, so the value of the asset from the viewpoint of the reference should be less). The assets are then placed on a horizontal axis that represents the stages of evolution of these elements (whose definition changes depending on the type of asset).
For illustration, a workshop based on Simon Wardley’s maps could yield the following result (this is a fictitious example):
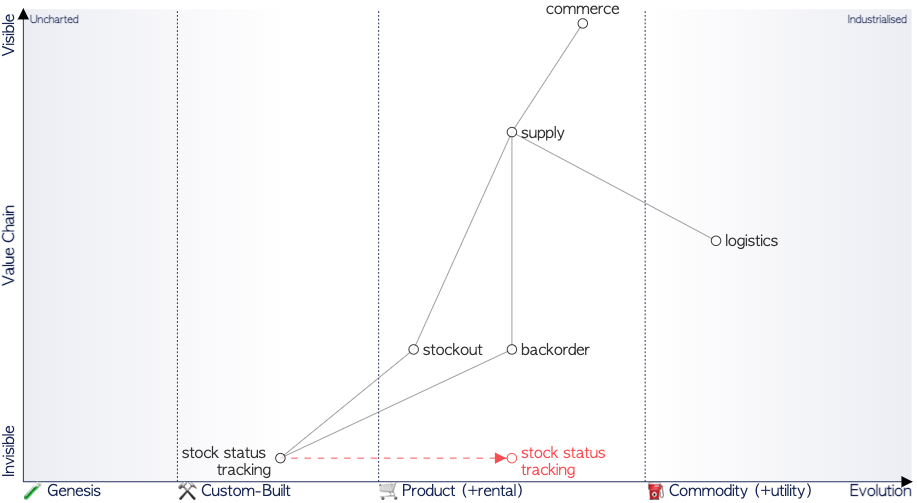
While a Wardley map allows situating a company in its market, here we zoom in to represent an activity in the context of the company. Thus, on the map shown here, a need for data-as-a-product emerges, exposing the tracking of stock status.
Explanation: Commerce needs to track supplies, and the fact that it is very visible from commerce (between commerce and supply on the vertical axis) shows that it’s a strategy of the company (where it’s less visible from the supply chain). To track supply, there need to be products that manage stock shortages (stock-outs) as well as backorders. These components will use data from the stock status, which will be in phase II of evolution and will evolve into a product (phase III) over iterations. In phase II, the data are unmodeled, and each of the stock shortage and backorder components uses its version of stock tracking data. Rationalizing usage will allow for managing the data as a product that brings value.
| Evolution | I | II | III | IV |
|---|---|---|---|---|
| Data | Unmodeled | Divergent | Convergent | Modeled |
| Activity | Genesis | Custom-Built | Product | Commodity |
Determining the Semantic Boundaries of Data
Once the need for the data-as-a-product is established, it’s important to determine its semantic usage. In the data-mesh paradigm, a data-as-a-product belongs to a business domain and is responsible for it. Drawing inspiration from Domain-Driven Design (DDD) methods, we can determine the semantic boundaries of the data-as-a-product by assimilating it to a bounded context.
Thus, an event-storming workshop should allow us to determine the ubiquitous vocabulary in the data-as-a-product and to define:
- What data is produced
- How it is made available
- The lifecycle of the data
- What data is consumed by this product
- The rules for calculation, transformation, aggregation, and internal triggering of the product
Entering the Product Development Cycle
Once the functional framework is established, the development cycle begins. As we saw in the first part, the data-as-a-product, characterized by its affordances, is much more than just a simple data-set. Therefore, to make the product useful, usable, and used, thereby adding value to the business, it is necessary to develop and standardize some of these affordances.
Publication of the Product Metadata
The publication of the first four affordances (serving data, consuming data, transforming data, and discovering and understanding the meaning of the data) involves writing a manifesto (described in chapter 14 of Zhamak Dehghani’s book).
Among the essential information in this manifesto are:
- The URI where the data produced by the data-as-a-product can be consumed.
- A description of the product’s output ports, which serve two purposes: describing how to access the data and enabling the provisioning of necessary resources (we will return to this shortly with the concept of the platform).
- Service Level Objective (SLO) documents to expose the level of service aimed for each output port.
- Input ports that describe the origin and mode of recovery of the source data.
- The internal data management policy (retention, confidentiality, etc.).
- Any additional assets necessary for the product’s operation (for example, the trained data of an ML algorithm). Standardizing the format of the manifesto will facilitate the consumption of data-as-a-product at the enterprise scale. Furthermore, using a serialization system like JSON or YAML will ease the use of the data by external systems.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://mycompany.com/data-as-a-product.schema.json",
"title": "Data-as-a-product Manifest",
"description": "Define the specification and the configurations required to do its job ",
"type": "object",
"properties": {
"dataProductURI": {
"description": "The unique identifier for a product",
"type": "string"
},
"productName": {
"description": "Name of the product",
"type": "string"
}
},
"outputPorts": {
"description": "Output ports for the product",
"type": "array",
"items": {
"type": "object"
},
"minItems": 1,
"uniqueItems": true
} ,
//...
"required": [ "dataProductURI", "outputPorts" ]
}Example of a manifest
The Generation Code
Another fundamental part of the data-as-a-product is the code that generates the data. It will be appropriate to adopt good practices in code versioning and generation, and to use deployment techniques derived from the experience gained in the operational world. Thus, the implementation of software deployment factories, CI chains, and test automation will ensure an optimum quality level of the data-as-a-product. Tools such as DBT or Dataform will facilitate the application of these practices (and in the future, languages like PRQL will allow for increasingly better management of data generation code).
The Platform
A crucial element of the digital landscape, the data platform facilitates the development, deployment, and use of data-as-a-products. We adopt the principles described by Evan Bottcher and define the platform as a set of self-service APIs, services, knowledge, and support that enable their use; these components are organized as an internal product intended for autonomous delivery teams.
In the context of developing data-as-a-products, the platform will provide data hosting services compatible with the definition of output-ports, as well as computing systems that will execute the core of the data-as-a-product, such as a SQL engine like BigQuery on GCP, Redshift on AWS, or Snowflake. However, care should be taken not to confuse the services provided by the cloud provider with the platform itself. Indeed, the platform is an internal product that meets specific needs. The capabilities offered by cloud providers are somewhat facilitators that ease the product’s implementation.
The platform is built progressively based on the needs expressed by the data-as-a-products. The Thinnest Viable Platform (TVP) capable of supporting the product’s affordances could very well be a well-organized documentary system to host the previously described manifesto (the concept of TVP is described in the book “Team Topologies”).
Conclusion
Implementing a data-as-a-product must bring intrinsic value;
The method described in this article is one example of a path to achieve this value. This method is not meant to be exhaustive or exclusive; it combines a set of elements that have proven effective in the implementation of operational software products over recent years.
If the business value of the data-as-a-product is immediately realized through the implementation of use cases, it is the interconnection of these cases that will bring a competitive advantage at the enterprise level. This advantage will be seen:
- in the reduced time to implement new use cases (with the possibility to test machine learning-based solutions more easily, for example)
- in better organization of knowledge at the enterprise level
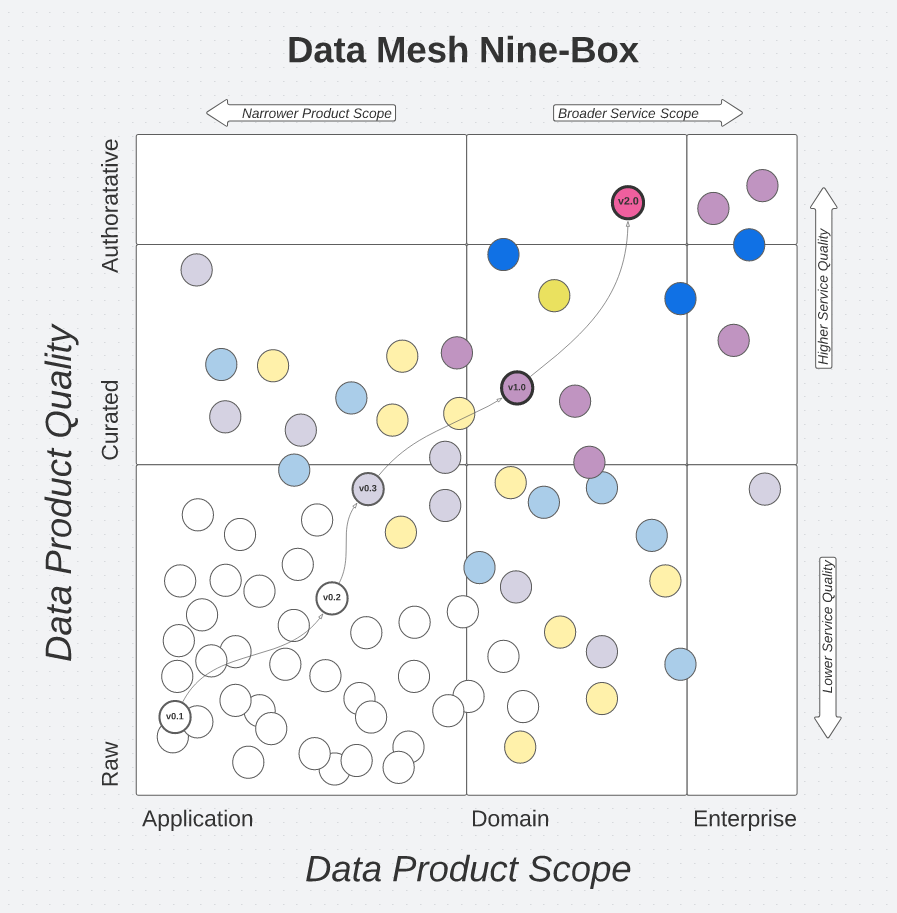
For example, the above illustration shows the growing value contribution at the enterprise level as iterations are made on a data-as-a-product. Finally, regarding the platform, it can be built in parallel by laying the first bricks that will allow data exchange between products.
The emergence of new languages for interacting with data (SQLX, PRQL) brings a change that will better meet specific needs by building custom solutions while continuing to exploit the power offered by cloud providers.