CCCCUE: Génération de diagrammes C4 avec CUE
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
À propos des diagrammes d’architecture
Gribouiller et dessiner des diagrammes font partie de mon travail.
Les architectes IT tendent à trouver un bon niveau d’abstraction pour représenter les plans de n’importe quel actif (à l’échelle de l’entreprise, jusqu’au composant logiciel).
Un niveau d’abstraction standardisé est appelé un modèle.
En architecture IT, j’apprécie les idées simples du modèle c4 inventé par Simon Brown.
Grâce au langage CUE, cet article exposera une façon de dessiner des diagrammes sous forme de données.
C4 en un coup d’œil
Le modèle C4 s’inspire d’un modèle célèbre appelé UML. L’un des objectifs du modèle C4 est de faciliter la description et la compréhension du fonctionnement d’un système logiciel pour les développeurs. L’idée est de représenter l’architecture logicielle sur différentes couches. Chaque couche est un “C” (C1, C2, C3 et C4)
Les quatre C signifient :
- Contexte (C1)
- Conteneurs (C2)
- Composants (C3)
- Code (C4)
Pensez-y comme différents niveaux de zoom d’une architecture globale… plus vous avez de C, moins il y a d’abstraction.
Pour plus d’informations, veuillez vous référer à la documentation officielle du modèle.
C4 dans mon travail
Dans mon travail, j’aime dessiner des diagrammes. Le niveau d’abstraction nécessaire pour les diagrammes dépend de l’audience. Le compromis est la plupart du temps de concevoir un C1 et de le remplir avec des éléments du C2.
Alors pourquoi dis-je C1/C2 ? Parce que je pense sincèrement que partir d’un Système en C1 et le compléter avec les conteneurs de C2 avec un aperçu en direct est un excellent moyen d’aligner les personnes et de partager une compréhension du contexte. La partie C1 empêche les solutions axées sur la technologie de prendre le dessus sur l’atelier, tandis que le C2 valide que les choix technologiques sont en phase avec le contexte.
En bref, un C1/C2 est utile pour aligner les participants d’un atelier et s’accorder sur la portée du logiciel.
Avant la pandémie, nous avions l’habitude de faire cela sur un tableau blanc. Néanmoins, le travail à domicile a fait du partage d’écran un élément de première classe de tout atelier. Par conséquent, je pense que c’est une excellente occasion d’utiliser des outils numériques pour faire une meilleure modélisation c4.
Diagramme-comme-code : Plantuml pour les grands et les bons
Il y a beaucoup d’avantages aux diagrammes-comme-code. L’un des plus couramment exposés est qu’ils sont faciles à versionner ; par conséquent, vous pouvez les héberger avec votre code.
J’ai un autre avantage : vous laissez un algorithme s’occuper du placement. Si vous êtes familier avec un outil tel que Graphviz (ou mermaidjs), vous comprenez probablement à quel point il est cool de se concentrer sur le contenu tout en laissant une machine s’occuper de la présentation.
Plantuml est un outil qui vous donne le pouvoir de coder vos diagrammes. Vous exprimez vos graphiques en code en appelant des fonctions essentielles avec des paramètres, et Plantuml est responsable de les transformer en une représentation visible. L’outil est extensible, et une bibliothèque a été développée pour dessiner des diagrammes C4.
Par exemple, si vous voulez créer un diagramme simple avec un système, vous incluez la bibliothèque et appelez la fonction System avec les arguments corrects :
@startuml C4_Elements
!include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Container.puml
System(systemAlias, "Label", "Optional Description")
@enduml
Avec l’extension VSCode, je l’utilise pour dessiner des diagrammes en direct lors de sessions d’ateliers à distance (cela peut même fonctionner avec LiveShare).
Le problème est que le code peut devenir désordonné et introduire une charge cognitive supplémentaire au fil du temps. Si une machine augmente n’importe quel niveau de complexité supplémentaire, elle cesse d’être utile.
Par exemple, ajouter des éléments visuels à vos diagrammes tels que des “tags” ou des “icônes” est en quelque sorte délicat car vous devez savoir comment appeler correctement les fonctions :
- Avez-vous remarqué le “Optional Description” dans l’exemple ?
- Que se passe-t-il si la description n’est pas présente ?
- La documentation de la fonction System est :
System(alias, label, ?descr, ?sprite, ?tags, $link); - pour un conteneur, la fonction est :
Container(alias, label, *techn, ?descr, ?sprite, ?tags, $link): ajouter un sprite et une technologie est manuel et les tags sont une chaîne d’éléments séparés par+.
Croyez-moi, c’est faisable, mais cela peut devenir un cauchemar à maintenir.
En plus de cela, modulariser le code et créer des bibliothèques personnalisées de tags et de sprites est pénible.
Ne tirez pas : je sais que c’est légèrement contre le modèle C4 d’ajouter de tels éléments, mais la plupart du temps, cela rend le diagramme plus puissant et facile à maintenir.
Diagramme-comme-données
Une façon de surmonter le problème de savoir comment appeler les fonctions serait de se débarrasser du code et de décrire complètement nos diagrammes avec des données.
Par exemple, je pourrais décrire un système via un schema et un conteneur dans un espace de noms c4 et instancier des objets de types c4.system et c4.container. Écrivons un exemple :
Considérez cette définition
-
un c4.system est composé de :
- un id
- un label
- une description optionnelle
- un sprite optionnel
- une liste optionnelle de tags
- une ligne optionnelle
- une liste optionnelle de conteneurs associés au système
-
un c4.container est composé de :
- un id
- un label
- une technologie optionnelle
- une liste optionnelle de tags
et ensuite ces déclarations :
-
referenceSystemest un système dont lenameestcompanyWebAppet leLabelest"WebApp". Il est concret car tous les champs obligatoires sont remplis. -
Ensuite, pour un projet particulier, nous pouvons déclarer
myprojectsystemcomme unreferenceSystemavec unedescription(par exemple, Ceci est la webapp de mon projet génial).- Maintenant nous avons
myprojectsystemqui est de typec4.systemetreferenceSystem. - Sur le même principe, nous pouvons déclarer un conteneur
mycontainerdans le projet et :- ajouter ce conteneur à
myprojectsystemle transformant en un diagramme C2, ou, encore mieux. - définir un système
myprojectsystemC2de typemyprojectsystemet ajouter le conteneur àmyprojectsystemC2.
- ajouter ce conteneur à
- Maintenant nous avons
Si nous changeons la description de myprojectsystem, cela changera également myprojectsystemC2, le même mécanisme s’applique si nous ajoutons un tag à myprojectsystem ou un nouveau champ à c4.system.
Cela semble fascinant mais encore abstrait ou complexe à réaliser… creusons dans une implémentation concrète. Espérons que cela clarifiera les choses.
CUE à la resCUE
CUE est un langage de configuration. Au sens pur du terme, c’est un langage de programmation : il transforme des chaînes de caractères et des éléments graphiques en sortie machine (voir la page Wikipedia pour le langage de programmation).
Par conséquent, nous utiliserons le langage pour exprimer les composants des domaines C4 et créer la configuration de nos diagrammes comme exposé précédemment.
Les définitions de schéma
Prenons cette définition du site web cuelang :
Un langage de définition de données décrit la structure des données. La structure définie par un tel langage peut, à son tour, être utilisée pour vérifier les implémentations, valider les entrées ou générer du code.
De nombreux standards existent pour définir le schéma, mais nous utiliserons CUE en raison de sa capacité à unifier le schéma et les valeurs (rappelez-vous, referenceSystem, une valeur qui est devenue le type d’un autre élément).
Cette raison en elle-même est suffisante pour préconiser l’utilisation de CUE, mais, éventuellement, nous pouvons également bénéficier de sa puissance pour valider la compatibilité ascendante, ou combiner des contraintes de différentes sources (par exemple, myprojectsystem2 peut être un projectsystem et un anotherProjectSystem).
Plus à ce sujet dans le chapitre Schema Definition du site web CUE.
Exemple pratique
Pour illustrer et jouer, définissons un fichier test.cue et ajoutons quelques définitions pour les éléments de base des systèmes et des conteneurs :
#System: {
id: string
label: *id | string
description?: string
containers?: [...#Container]
// some fields described before are omitted for clarity
}
#Container: {
id: string
label: *id | string
description?: string
// some fields described before are omitted for clarity
}Un peu d’explication sur la syntaxe - kit de survie CUE :
- le
#: cela indique que le champ/id est une définition - l’opérateur de rencontre
a & b: indique que la valeur est le résultat de la rencontre des opérandesaetb. Par conséquent, une valeurval: 3 & 2est une erreur, maisval: 3 & <4est possible et la valeur devalest concrète et est3.val: >2 & <4est possible mais n’est pas concret ; par conséquent, cela soulèvera une erreur au moment de l’évaluation (nous verrons cela plus tard). - l’opérateur de jointure
a | b: indique qu’une valeur estaoub. Par exemple,val: 3| 2est mais au moment de l’évaluation, cela soulèvera une erreur, car il ne peut pas déterminer la valeur finale deval. Nous utilisons le*pour spécifier la valeur préférée. Par conséquent,val: 3 | *4sera évalué comme la valeur devalest 4.
Maintenant, ajoutons les définitions de l’exemple du paragraphe précédent dans le fichier test.cue :
-
referenceSystemest un système dont lenameestcompanyWebAppet leLabelest"WebApp":referenceSystem: #System & { id: "companyWebApp" label: "WebApp" } -
myprojectsystemest unreferenceSystemavec unedescriptionmyProjectSystem: referenceSystem & { description: "This is the webapp of my awesome project" } -
nous pouvons déclarer un conteneur
mycontainermyContainer: #Container & { id: "mycontainer" } -
nous définissons un système
myprojectsystemC2de typemyprojectsystemet ajoutons le conteneurmyProjectSystemC2: myProjectSystem & { containers: [myContainer] }
Évaluation
Examinons maintenant notre configuration. La logique de CUE est de lire le fichier (rappelez-vous cette idée de langage…), d’unifier la configuration et de rechercher des valeurs concrètes. Toutes les valeurs doivent éventuellement converger vers un élément concret, ce qui signifie que rien n’est laissé vide.
L’exécution de cue vet test.cue garantira que le fichier que nous avons créé est complet.
Ensuite, en interne, CUE peut résoudre les références et substituer ou subsumer les valeurs des espaces réservés.
Voyons cela en action en exécutant cue eval pour évaluer le fichier et afficher le résultat de l’évaluation :
// cue eval test.cue -c
referenceSystem: {
id: "companyWebApp"
label: "WebApp"
}
myProjectSystem: {
id: "companyWebApp"
label: "WebApp"
description: "This is the webapp of my awesome project"
}
myContainer: {
id: "mycontainer"
label: "mycontainer"
}
myProjectSystemC2: {
id: "companyWebApp"
label: "WebApp"
description: "This is the webapp of my awesome project"
containers: [{
id: "mycontainer"
label: "mycontainer"
}]
}Nous pouvons également exécuter une requête pour afficher l’objet myProjectSystemC2 :
// this is the result of the command: cue eval -e myProjectSystemC2 test.cue
id: "companyWebApp"
label: "WebApp"
description: "This is the webapp of my awesome project"
containers: [{
id: "mycontainer"
label: "mycontainer"
}]Jusqu’à présent, tout va bien, tout est résolu, et myProjectSystemC2 est rempli de toutes les informations. Le système est autonome.
Le DSL complet
Il dépasse le cadre de cet article de décrire la logique complète ou l’outillage autour de CUE. J’ai collecté toutes les définitions requises pour exprimer mes diagrammes et les ai encapsulées dans un module.
Ce module est hébergé sur GitHub dans le dépôt owulveryck/cue4puml4c4.
Vous trouverez les définitions pour configurer les diagrammes :
#System: l’élément fondamental d’un C1#Person: représentant une personne#Container: le composant supplémentaire pour un C2#Relation: un élément pour relier deux autres composants
Les définitions pour ajouter des tags :
#ElementTag: un tag qui peut être ajouté à une personne, un système ou un conteneur#RelationTag: un tag qui peut être ajouté à une relation
En plus de cela, j’ai décrit une notion de #Technology qui peut éventuellement contenir un sprite :
#Technology#Sprite
Technologie et sprites : J’ai ajouté une notion de Technologie qui peut être ajoutée à divers éléments tels qu’un conteneur ou un tag. Une technologie a un nom et un type (trois types sont possibles : “”, “Db”, “Queue”). Elle peut également contenir un sprite optionnel. Un sprite a une URL. Cela sera utile pour le rendu via plantuml. Par exemple, la technologie “Go” est déclarée comme suit.
Go: c4.#Technology & {
name: "Go"
sprite: {
url: "https://raw.githubusercontent.com/tupadr3/plantuml-icon-font-sprites/master/devicons/go.puml"
id: "go"
}
}J’ai également inclus trois packages qui importent des technologies/bibliothèques courantes :
github.com/owulveryck/cue4puml4c4/technology/devinclut tous les sprites d’icônes du dépôt plantuml-icon-font-sprites de tupadr3github.com/owulveryck/cue4puml4c4/technology/stdlibinclut tous les sprites d’icônes de la stdlib de plantumlgithub.com/owulveryck/cue4puml4c4/technology/gcpinclut tous les sprites d’icônes de la plateforme Google Cloud
Rendu du diagramme : plantuml comme moteur de rendu
Maintenant que nous avons des objets CUE représentant nos diagrammes, rendons-les. Comme promis, nous allons transformer le fichier CUE en code plantuml et donc utiliser plantuml comme moteur de rendu.
Le principe est d’appliquer notre configuration à un fichier modèle. CUE a un moteur de rendu de modèles intégré importé du monde Go.
La syntaxe est donc la même.
J’ai ajouté un objet plantumlTemplate à l’intérieur du package c4. Cet objet est un modèle qui doit être appliqué à une structure c4.#C1.
(https://github.com/owulveryck/cue4puml4c4/blob/main/template.cue)
Scripting
CUE est utilisable comme langage de script. Nous allons étendre l’utilitaire cue avec une commande genpuml pour générer le fichier plantuml à partir des objets.
Pour ajouter une commande, nous devons créer un fichier avec le suffixe _tool.cue. Et ensuite ajouter une commande à une structure globale command. Une commande est donc traitée comme n’importe quelle autre valeur CUE.
Nous utiliserons le package interne text/template pour traiter le modèle :
import "text/template"
//...
text: template.Execute(c4.plantumlTemplate, C1)Veuillez noter l’objet C1, qui est celui que nous avons défini précédemment.
Ensuite, par simplicité, nous voulons afficher le résultat sur stdout. Pour y parvenir, nous utilisons le package interne tool/cli, qui a une fonction Print :
import "tool/cli"
// ...
cli.Print & {
text: template.Execute(c4.plantumlTemplate, C1)
}
Ensuite, nous devons créer notre commande :
package main
import (
"tool/cli"
"text/template"
"github.com/owulveryck/cue4puml4c4:c4"
)
command: genpuml: {
c1: cli.Print & {
text: template.Execute(c4.plantumlTemplate, C1)
}
}Maintenant, nous pouvons appeler cue cmd genpuml depuis l’invite de commande ; cela lira et unifiera la configuration, appliquera le résultat au modèle et affichera le résultat sur stdout.
Le résultat peut être traité par plantuml :
- en ligne de commande :
cue cmd genpuml | java -jar ~/plantuml.jar -tsvg -pipe`- sur un serveur plantuml :
cue cmd genpuml | curl --silent --show-error --fail -H "Content-Type: text/plain" --data-binary @- http://localhost:8080/plantuml/svg/ --output -`Un exemple complet est hébergé sur GitHub. Il génère cette image (qui n’a pas de sens :) :
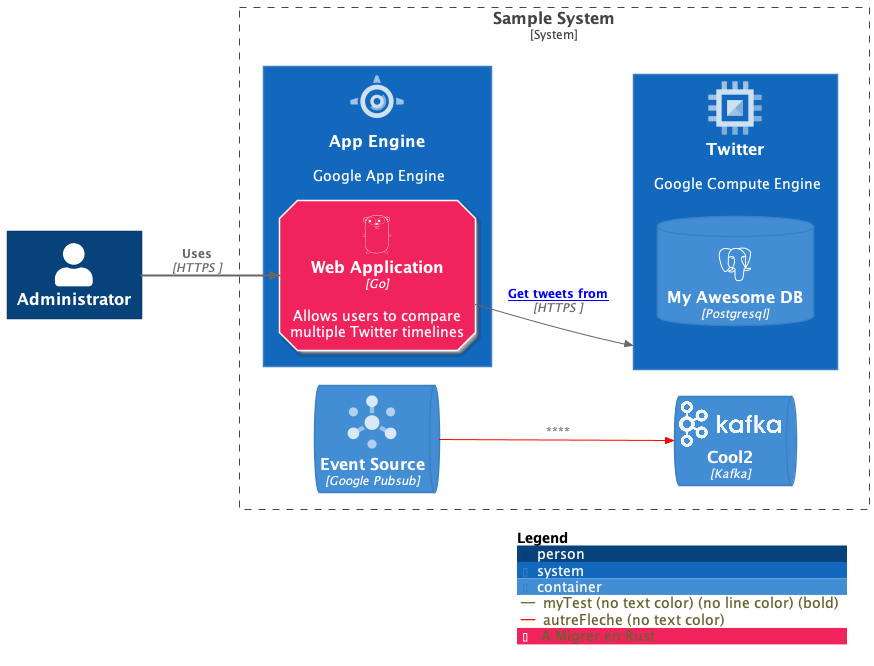
Bonus : Prévisualisation en direct
Au début de cet article, j’ai mentionné que j’aime esquisser mes diagrammes en direct lors d’un atelier. J’ai ajouté un petit utilitaire qui :
- surveille un changement de fichier dans un répertoire
- appelle
genumpletplantumllors de l’enregistrement - envoie le résultat sur une page web via un WebSocket.
Cela permet une vue en direct du diagramme que nous générons.
le code source est sur GitHub
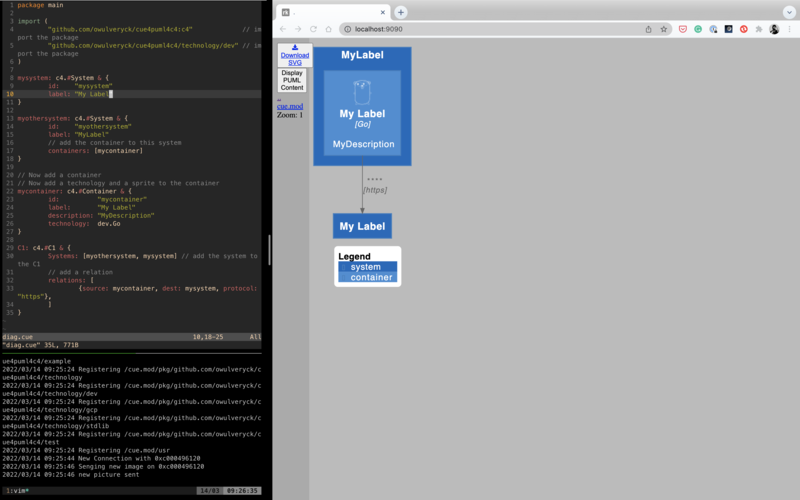
Conclusion
J’ai maintenant un nouvel outil dans ma boîte à outils. La prochaine étape est de préparer une bibliothèque de tags que j’utilise couramment. Par exemple, je fais beaucoup de migrations, et donc un tag “toBeDeleted”, avec une couleur spécifique peut être utile.
J’ai également utilisé l’outil pour créer un diagramme par service et créer une vue globale éparse dans un logiciel distribué. En plus de cela, j’ai utilisé les liens pour pointer vers les consoles administratives ou la surveillance directement à partir de l’image.
Le ciel est la limite quand on code…