POV: Une plateforme de streaming/communication pour le data mesh
Note: Cet article est une traduction automatique. L’article original a été écrit en anglais.
Note : Cet article est également publié sur le blog d’OCTO Technology
En 2021, un ensemble riche de données est le terreau qui alimente l’activité de tous les géants d’Internet (GAFAM, NATU, …).
Pendant ce temps, les entreprises traditionnelles s’efforcent de rester compétitives. Par conséquent, l’accélération obligatoire de leur activité passe par une numérisation massive de leurs opérations et de leurs actifs.
Parmi les actifs numériques les plus précieux figurent les données. Les promesses du Big Data sont attrayantes. Cependant, l’unité organisationnelle “data” est généralement séparée du cœur de métier dans la nature. Même si beaucoup de ces départements fournissent beaucoup d’efforts pour apporter de la valeur à l’organisation, le plan d’affaires global ressemble généralement à ceci :
- étape 1 : collecter
- étape 2 : ?
- étape 3 : profit
Dans cet article, je présenterai une façon d’aborder l’étape 2 du plan. J’emprunterai des concepts au paradigme du data-mesh comme modèle.
À la fin de l’article, vous aurez une idée que les liens entre la gouvernance computationnelle fédérée, le rôle de la plateforme et le produit de données sont cruciaux pour tirer profit du paradigme du data-mesh.
J’illustrerai éventuellement ces concepts avec une implémentation technologique triviale (avec du code) - apprendre en faisant !
Avertissement : l’implémentation décrite ici est un squelette servant de preuve de valeur. Comme d’habitude, adapter est mieux qu’adopter, et le lecteur devrait ajuster la plupart des concepts ici en fonction du contexte métier et des contraintes de construction. Néanmoins, le code présent dans cet article fonctionne, et les extraits de code que vous trouverez au fil de l’explication utilisent des tests qui pourraient être compréhensibles pour la plupart des développeurs.
Précédemment dans le monde des Données
Comme expliqué dans l’introduction, beaucoup d’efforts ont été mis dans des solutions technologiques pour traiter les problèmes de big data et en extraire leur valeur.
Si nous appliquons l’adage “pendant une ruée vers l’or, vendez des pelles” à notre contexte, les vendeurs de pelles conduisent à diverses implémentations technologiques telles que les data-warehouse, les data-lake, et dernièrement les data-factories. Mais, même si cela peut sembler être la bonne chose à faire, ces solutions partagent un problème commun : elles peuvent difficilement évoluer.
Pour gérer cette ruée en s’attaquant aux problèmes de l’écosystème des pelles tout en se concentrant sur l’or (les données), Zhamak Dehghani a introduit un changement de paradigme appelé data mesh. Le data-mesh est un moyen d’exploiter les données de manière distribuée. En essence, le changement de paradigme est :
- se concentrer sur la distribution de la propriété et de l’architecture technologique ;
- placer les données au centre de chaque composant distribué.
Tout le reste du data mesh consiste à résoudre les problèmes qui en découlent.
Les piliers du data mesh en un coup d’œil
Quatre piliers soutiennent un data mesh :
- Une gouvernance computationnelle fédérée.
- Une architecture de propriété des données orientée domaine.
- La pensée des données comme produit.
- Une plateforme d’infrastructure en libre-service.
Passons maintenant à un extrait des concepts que nous voulons illustrer avec notre preuve de valeur.
Les données comme produit
Le premier pilier que nous devons définir est de traiter les données comme un produit. Pour donner du pouvoir à l’entreprise, les propriétaires doivent considérer les données comme un produit. Pour apporter la valeur maximale à l’entreprise, les données-en-tant-que-produit doivent être :
- Découvrables : Déclarées sur un catalogue et un moteur de recherche
- Compréhensibles : fournir une description sémantique (signification), syntaxique (topologie) et d’utilisation (comportement)
- Adressables : doivent participer à un écosystème global avec une adresse unique qui aide ses utilisateurs à les trouver et à y accéder par programmation
- Sécurisées : Être accessibles en toute sécurité avec des politiques globales (contrôle d’accès basé sur les rôles, contrôle d’accès basé sur l’objectif, RGPD, sécurité des informations, souveraineté des données…)
- Interopérables : Être capables de réutiliser, corréler et les assembler à travers les espaces de noms pour de nouveaux cas d’utilisation
- Fiables – Véridiques : Fourniture de la provenance et de la lignée des données et de la qualité des données par le propriétaire
- Nativement accessibles : Fourniture d’un accès multimodal comme les services Web, les événements des interfaces de fichiers
- Précieuses en soi : Conçues pour fournir des insights plus élevés lorsqu’elles sont combinées et corrélées
- Engagées sur des SLO : Doivent respecter les niveaux de service attendus en termes de disponibilité et de qualité des données.
Gouvernance computationnelle fédérée
L’article original décrivant les principes du data mesh définit la gouvernance computationnelle fédérée comme
un modèle qui embrasse la décentralisation et l’auto-souveraineté du domaine, l’interopérabilité par la standardisation globale, une topologie dynamique et, surtout, l’exécution automatisée des décisions par la plateforme.
Dans cet article, nous insisterons sur l’exécution automatisée des décisions par la plateforme. En substance, nous décrirons et implémenterons un ensemble de fonctionnalités de la plateforme, et nous soulignerons pourquoi elles sont obligatoires dans une telle organisation.
Infrastructure de données en libre-service en tant que plateforme
Dans le présent contexte, la plateforme agira comme un levier pour le développement et l’exécution des produits de données. En plus de cela, comme expliqué dans le dernier paragraphe, elle assumera également le rôle de validateur par rapport aux décisions prises par la gouvernance fédérée.
La plateforme est composée de différents services et offre des fonctionnalités qui participent à la robustesse du maillage. Notre implémentation se concentrera sur l’une des fonctionnalités : la communication entre les nœuds et la capacité d’événements comme levier pour l’exploitation des données.
Représentation du data mesh
Pour simplifier l’idée du maillage pour le reste de l’article, nous représenterons le réseau comme ceci :
Un ensemble de produits autonomes qui apportent de la valeur par eux-mêmes (Profit) en collectant des données et qui exposent leurs données à d’autres pour donner une valeur plus significative à l’entreprise :
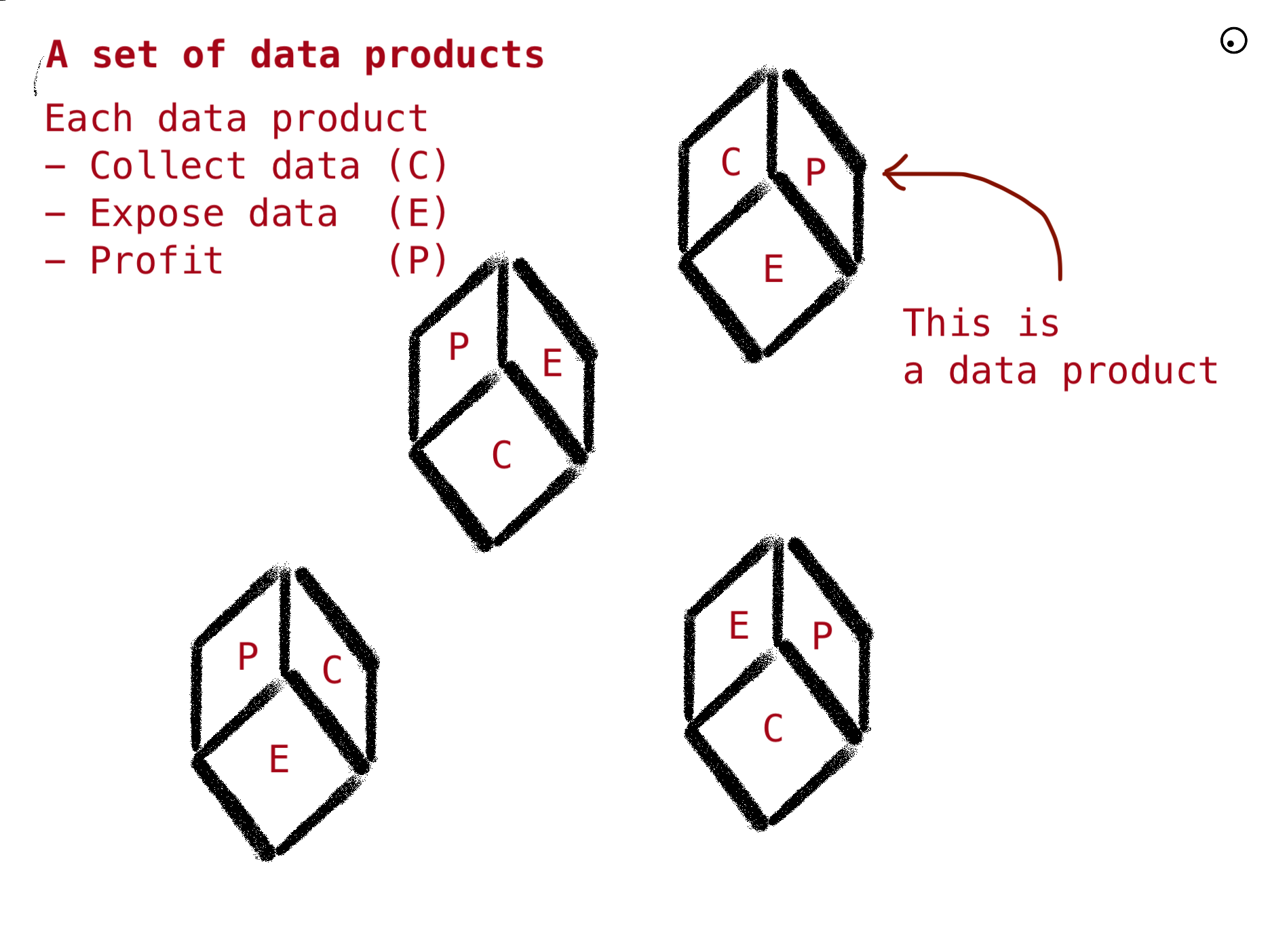
Le carburant de chaque produit est un ensemble de données fournies en saisissant des données à partir des services opérationnels et par d’autres produits via un ensemble de canaux de communication. La somme est le maillage. Le maillage apportera des profits à l’ensemble de l’entreprise.
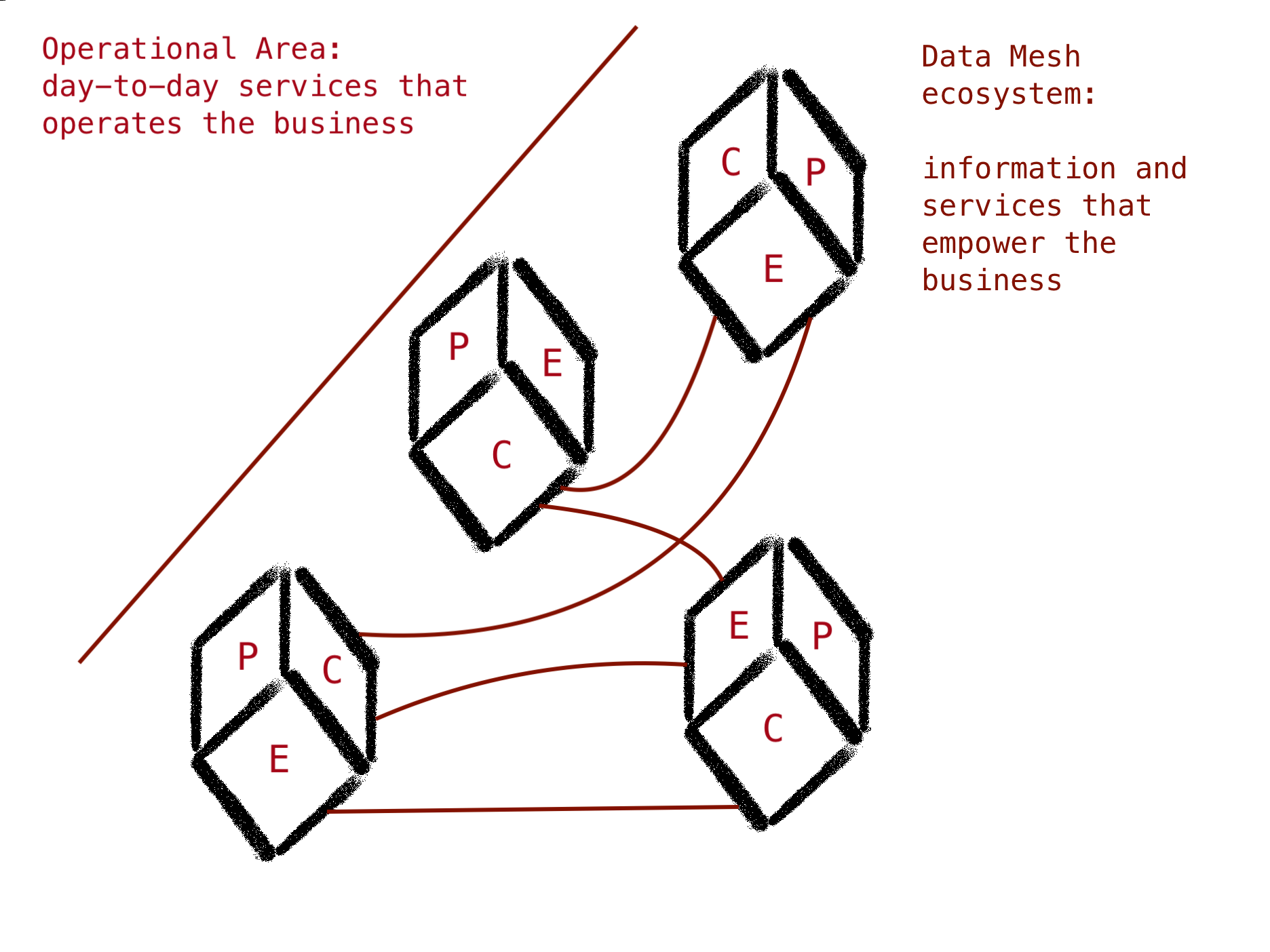
Mesh : une question de communication
Dans le modèle que nous avons exposé, la communication est obligatoire pour que le maillage existe. Sans communication, nous nous retrouvons avec un ensemble de nœuds indépendants.
La gestion de la communication est donc essentielle pour construire des produits qui sont compréhensibles, interopérables et accessibles. En plus de cela, un bon réseau de communication doit permettre la découvrabilité des produits.
Voyons maintenant comment implémenter l’un des nombreux systèmes de communication basés sur les événements qui répond aux prérequis du data mesh.
Modélisation de la communication
Cette section introduira des concepts fondamentaux qui aideront à comprendre l’implémentation technique qui suivra.
Le modèle de base représentant un système de communication a été défini en 1948 par Claude Shannon. Empruntons cette représentation et l’explication de l’essai A mathematical theory of communication :

Laissons de côté la source de bruit et concentrons-nous sur les autres éléments :
Note : ignorer la source de bruit équivaut à considérer un canal sans bruit, comme décrit dans la partie I de l’article original. Dans notre contexte, le modèle est appliqué à un ensemble de composants qui opèrent sur une couche qui est à peine sensible au bruit (niveau applicatif).
- Une source d’information qui produit un message ou une séquence de messages à communiquer au terminal récepteur. Dans notre cas, le message est une donnée à transmettre à d’autres nœuds du maillage.
- Un émetteur qui opère sur le message d’une certaine manière pour produire un signal adapté à la transmission sur le canal.
- Le canal est simplement le médium utilisé pour transmettre le signal de l’émetteur au récepteur.
- Le récepteur effectue habituellement l’opération inverse de celle effectuée par l’émetteur, reconstruisant le message à partir du signal.
- La destination est la chose à qui le message est destiné.
En gros, standardiser le réseau de communication dans le maillage conduira à cette représentation :
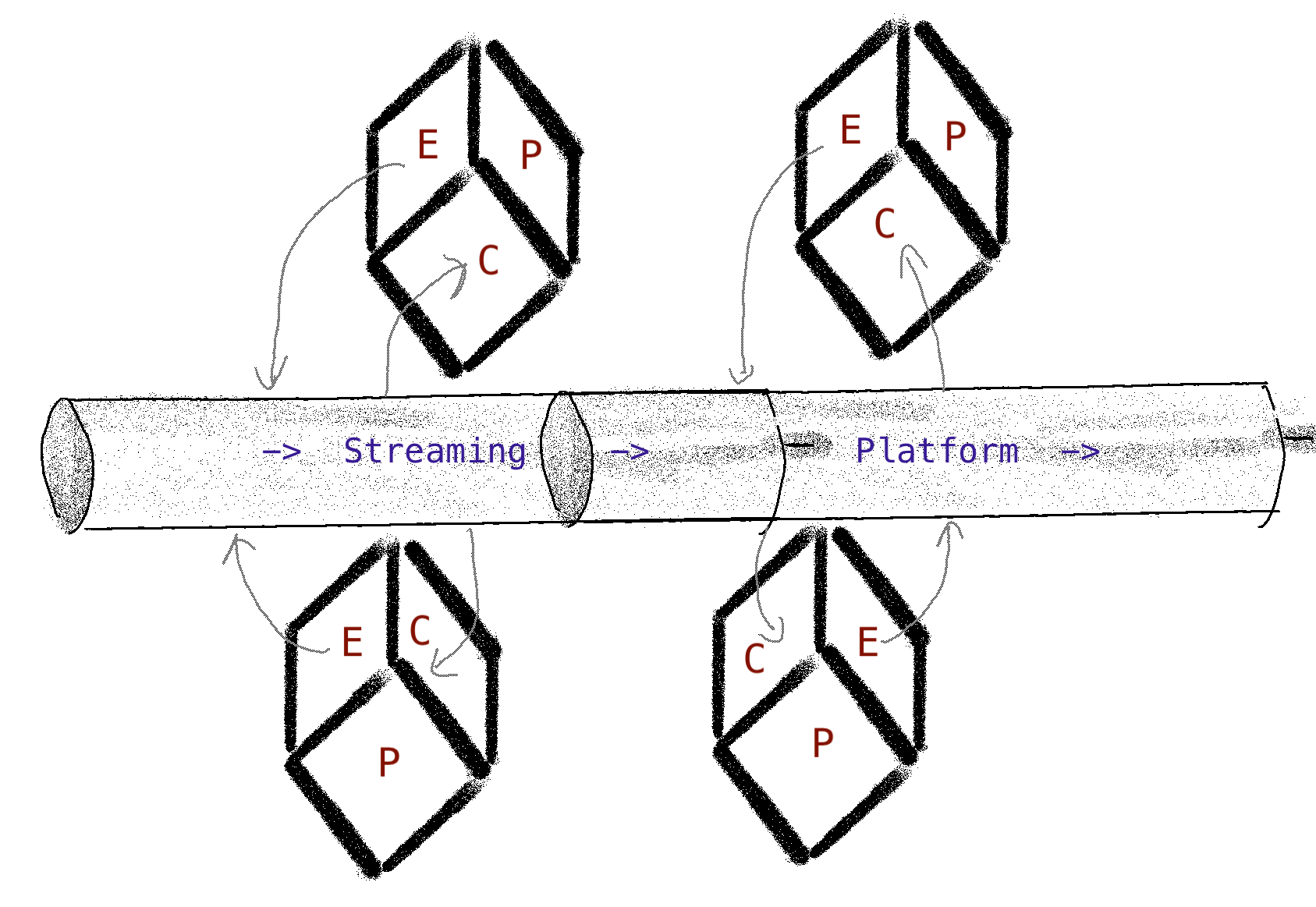
Application à notre maillage
Du modèle de communication au pipeline de traitement des données
Instancier ce modèle de communication dans le monde des données équivaut à peu près à décrire un pipeline peu profond de traitement des données (plus à ce sujet plus tard, dans l’implémentation). Expliquons-le étape par étape.
Rendre le message compréhensible : la sémantique
La source et la destination doivent s’accorder sur la sémantique du message. En informatique, cet objectif est atteint en partageant un schéma et des définitions de l’information. Par exemple, en français, nous pouvons exprimer un message comme ceci :
Le message contient l’identité d’une personne. L’identité d’une personne est composée de son prénom commençant par une majuscule, de son nom de famille commençant par une majuscule, et éventuellement de son âge, qui est un nombre inférieur à 130.
En plus de cela, le rôle de la “gouvernance fédérée” est d’imposer un langage commun pour exprimer les messages et imposer une syntaxe partagée pour les définitions de schéma. En fait, pour être adressable par programmation, le produit doit exposer ses définitions et schémas dans un langage informatique convivial, par exemple, JSON-Schema, Protobuf ou CUE. C’est pourquoi le data mesh l’appelle une “gouvernance computationnelle fédérée.”
Par exemple, voici la définition du schéma dans le langage CUE :
message: #Identity & {
first: "John"
Last: "Doe"
Age: 40
}
#Identity: {
// first name of the person
first: =~ "[A-Z].*"
// Last name of the person
Last: =~ "[A-Z].*"
// Age of the person
Age?: number & < 130
}Note : Plus d’informations sur le choix du langage CUE viendront plus tard dans cet article.
Les outils de CUE permettent à un ordinateur de comprendre facilement la syntaxe et facilitent la validation des données (par exemple, l’appel à cue vet identity validera les données par rapport à leur définition ; vous pouvez jouer avec l’exemple directement dans le Cue playground si vous n’avez pas les outils localement).
Changer le nom de famille de Doe à doe ou définir un âge supérieur à 130 entraînerait une erreur.
La validation empêche d’envoyer du bruit ou des déchets sur le canal :
La validation empêche d’envoyer du bruit ou des déchets sur le canal :

En résumé, le rôle de l’émetteur de message est d’exposer sa sémantique dans un langage défini par la “gouvernance fédérée” et d’émettre un message qui est syntaxiquement et fonctionnellement cohérent avec la définition (comme validé par la “gouvernance computationnelle fédérée”).
Créer un signal : l’émetteur
Une fois que nous avons transformé l’information en un message compréhensible (cette opération est généralement appelée un processus de marshaling), nous le passons à l’émetteur pour l’encoder en un signal et émettre les données.
Le rôle du signal est d’assurer que l’information se propage en toute sécurité sur le canal de communication. En plus de cela, le format du signal devrait permettre le multiplexage pour éviter de cuisiner des spaghettis de canaux dans notre maillage.
Encapsuler le message dans une enveloppe est une façon d’aborder le problème.
L’enveloppe permet de créer une structure partagée. Cette structure gère les métadonnées telles que l’émetteur du message, son type, sa source, et ainsi de suite.
Encore une fois, c’est le rôle de la “gouvernance computationnelle fédérée” de définir le format et les normes de l’enveloppe. Cloudevents en est un. Il standardise l’échange de messages entre les services cloud.
En résumé, le rôle de l’émetteur est de transmettre le message sur le canal en l’encapsulant dans un événement (aussi appelé marshaling de l’événement). L’enveloppe de l’événement est standardisée par la gouvernance. L’émetteur est une capacité offerte par une “infrastructure en libre-service” (les produits de données devraient être autonomes pour transmettre certains événements)
Diffuser le signal : le canal
Le rôle du canal est de stocker et d’exposer les événements aux récepteurs. De plus, le rôle du canal est de valider que le message, une fois accepté, est livré aux récepteurs autorisés et prévus. Cela garantira la sécurité et la confiance de toute l’infrastructure. Ce n’est pas le rôle du canal d’analyser le message de quelque manière que ce soit. Il est donc indépendant du type de messages (pensez au téléphone, vous pouvez parler anglais ou français au téléphone).
Implémentation triviale : une plateforme de streaming
Maintenant que nous avons tous les concepts, implémentons l’infrastructure de communication en libre-service qui facilitera le développement du produit tout en assurant les règles de la gouvernance computationnelle fédérée.
Tout d’abord, résumons le pipeline en utilisant le symbole de pipe Unix (|) :
// Envoi :
collect_data | marshal_message | emit_message | validate_message | marshal_event | send_to_channel
// Réception :
filter_events_from_channel | read_from_channel | unmarshal_event | unmarshal_data | profitPour faciliter le développement et la maintenance du maillage, l’infrastructure de communication en libre-service (appelons-la une plateforme de streaming) fournira ces capacités :
- validate_message : comme dit précédemment, c’est un must pour assurer la qualité des données
- gestion des canaux
- filtrage d’événements, et plus précisément, routage d’événements
En plus de cela, elle doit fournir un référentiel de schémas de données (catalogue de données) pour rendre l’information adressable.
Ce que nous construisons en un coup d’œil
Nous allons construire un produit, partie d’une plateforme globale ; son but est d’interconnecter les nœuds du maillage et de fournir un moyen standard d’exposer l’information. Nous ferons référence à ce que nous construisons comme la plateforme de streaming pour le reste du document.
Un langage de configuration pour la sémantique
Comme expliqué précédemment, le système devrait être suffisamment générique pour être faiblement couplé avec la sémantique des données.
Précisément, ce devrait être le rôle du propriétaire des produits de données d’exprimer le schéma et les règles de validation métier ; Nous pouvons donc considérer les capacités de validation et de catalogage des données comme la configuration d’une instance générique de la plateforme de streaming.
Note : Le livre Site Reliability Engineering définit une configuration comme une interface homme-machine pour modifier le comportement du système.
Dans notre implémentation triviale, nous utilisons le langage CUE car il est accessible et concis dans la définition.
Parmi ses atouts, CUE :
- Permet la validation des données par conception ;
- composition des données mais pas d’héritage ;
- contient un ensemble d’outils pour formater, linter et valider facilement les données et les schémas ;
- Fournit une API (en Go) pour construire un ensemble d’outils que nous utiliserons pour le reste de cet article.
Notre plateforme de streaming est donc une interface générique de validation et de publication de messages configurée avec CUE.
Exécution/Runtime
Une fois que nous avons configuré notre plateforme de streaming pour gérer et comprendre tous types de messages décrits en CUE, nous devons fournir une interface utilisateur finale qui facilite l’ingestion, la validation et la transmission des données.
CUE signifie Configure/Unify/Execute. C’est un parfait résumé de ce que nous essayons d’accomplir : nous configurons la plateforme pour comprendre une définition de l’information ; en interne, la plateforme unifie la définition et les données et exécute la validation.
C’est ce que fait la commande cue vet que nous avons émise précédemment sous le capot. Mais nous voulons peut-être la transformer en un service pour faciliter les tests et la robustesse. Cet extrait de code simple montre la puissance du SDK : moins de dix lignes sont nécessaires pour valider des données par rapport à un schéma (y compris les contraintes fonctionnelles).
type DataProduct struct {
definition cue.Value
// ...
}
func (d *DataProduct) ExtractData(b []byte) (cue.Value, error) {
data := d.definition.Context().CompileBytes(b)
unified := d.definition.Unify(data)
opts := []cue.Option{
cue.Attributes(true),
cue.Definitions(true),
cue.Hidden(true),
}
return data, unified.Validate(opts...)
}Note : Il dépasse le cadre de cet article de détailler l’implémentation des services, mais comme preuve de concept, vous pouvez vous référer à ce gist pour un exemple complet avec un gestionnaire HTTP ; Ce gist contient également un test fonctionnel qui montre différents scénarios de validation.
Événements/Routage
Jusqu’à présent, nous avons vu qu’il faut un effort minimal pour exprimer un schéma et valider les données à l’entrée de la plateforme de streaming.
Avant de le soumettre à un canal de communication (à définir plus tard), assurons-nous que nous écrivons une enveloppe compréhensible. Nous l’avons déjà exprimé : l’interopérabilité est la clé du succès du maillage. L’utilisation d’une enveloppe standard garantira que le message peut sortir de l’écosystème de la plateforme.
Cloudvents est un format standard de la Cloud-native Computing Foundation (CNCF) qui répond à ce besoin. La spécification de Cloudevents standardise la structure de l’enveloppe en introduisant des concepts tels que la source de l’événement, le type de l’événement, ou son identifiant unique (utile pour le traçage et la télémétrie).
Le rôle de la Gouvernance Fédérée assure que la déclaration des sources et des types d’événements est correctement enregistrée dans un catalogue et largement accessible à tout consommateur de données. Notre plateforme de données de streaming encapsulera les données dans un Cloudevent.
Exemple d’événement sérialisé en JSON :
{
"specversion": "1.0",
"id": "1234-4567-8910-1234-5678",
"source": "MySource",
"type": "MySource:newPerson",
"datacontenttype": "application/json",
"data_base64": "MyMessageInJSONEncodedInBase64=="
}Bien sûr, la plateforme peut gérer facilement l’encodage de l’événement.
Encore une fois, il dépasse le cadre de cet article de montrer comment le faire, mais ce gist contient toutes les informations requises dont un lecteur pourrait avoir besoin pour approfondir l’implémentation.
Le canal
Maintenant que nous avons un signal, il est temps de le propager sur un canal de communication.
Le canal est un moyen de communication. Par conséquent, dans le modèle de Shannon, il peut être n’importe quoi qui peut agir comme un tampon entre l’émetteur et le récepteur. Mais dans notre contexte, nous pouvons ajouter certaines fonctionnalités requises :
- Nous devrions permettre à plusieurs récepteurs de recevoir un message
- La communication peut être asynchrone
- Le canal doit être tolérant et robuste pour éviter toute perte de messages
Pour la robustesse et l’efficacité, une solution comme Kafka est probablement un choix sûr, mais pour aller vite, des solutions gérées comme Google PubSub pourraient faire l’affaire. Comme nous traitons la validation des données à l’entrée du canal pour éviter les déchets entrants/sortants, il n’y a pas besoin d’un mécanisme de validation intrinsèque. Kafka fait partie de l’infrastructure (dans la définition d’une architecture hexagonale) ; garder la validation en dehors de Kafka assure une forte ségrégation de l’infrastructure et son indépendance par rapport au produit de la plateforme de streaming.
Note : Nous ne creusons pas dans les problèmes de partitionnement dans cet article, ni n’utiliserons l’extension de partitionnement de la spécification Cloudevents.
Pour continuer le voyage de codage, vous pouvez vous référer à cette implémentation d’une connexion Kafka qui publie un “Cloudevent” dans un sujet.
Le catalogue/openAPI
Une partie essentielle de notre voyage est la capacité du consommateur à extraire et comprendre les données du signal.
Une solution est d’exposer la définition du schéma en CUE ; une alternative est de fournir une définition OpenAPI standard du schéma. Cette dernière option a l’avantage significatif d’être compatible avec la plupart des langages et frameworks de développement. Par conséquent, coder un consommateur de données deviendra simple, et le temps de mise sur le marché augmentera.
La boîte à outils et le SDK de CUE facilitent la conversion d’un ensemble de définitions en une spécification OpenAPI v3. L’utilitaire en ligne de commande de la boîte à outils standard CUE peut effectuer un tel travail :
❯ ( cat << EOF
#Identity: {
// first name of the person
first: =~ "[A-Z].*"
// Last name of the person
Last: =~ "[A-Z].*"
// Age of the person
Age?: number & < 130
}
EOF
) | cue export --out=openapi -
{
"openapi": "3.0.0",
"info": {
"title": "Generated by cue.",
"version": "no version"
},
"paths": {},
"components": {
"schemas": {
"Identity": {
"type": "object",
"required": [
"first",
"Last"
],
"properties": {
"first": {
"description": "first name of the person",
"type": "string",
"pattern": "[A-Z].*"
},
"Last": {
"description": "Last name of the person",
"type": "string",
"pattern": "[A-Z].*"
},
"Age": {
"description": "Age of the person",
"type": "number",
"maximum": 130,
"exclusiveMaximum": true
}
}
}
}
}
}Et pour notre POC, nous utiliserons encore une fois le SDK comme exposé dans ce gist.
Récapitulation / Assemblage
En assemblant tout le code que nous avons parcouru, on peut générer un serveur web élémentaire qui :
- Lit et comprend le schéma de données tel qu’exprimé par le propriétaire du produit ;
- Expose une version open API du Schéma
- Écoute un point de terminaison pour les données
- Valide les données
- Génère un format Cloudevent
- L’envoie sur le réseau
Tout cela en 100 lignes de code que vous pouvez trouver ici.
Vous pouvez alimenter le système avec cette définition :
#Identity: {
// first name of the person
first: =~ "[A-Z].*"
// Last name of the person
Last: =~ "[A-Z].*"
// Age of the person
Age?: number & < 130
}Ensuite, interrogez le serveur pour l’OpenAPI :
curl http://localhost:8181/openapi
{
"openapi": "3.0.0",
"info": {
"title": "Generated by cue.",
"version": "no version"
},
"paths": {},
"components": {
"schemas": {
...
}Ou envoyez de bonnes données …
❯ curl -XPOST -d'{"first": "John","Last": "Doe","Age": 40}' http://localhost:8181/
ok… ou de mauvaises données …
❯ curl -XPOST -d'{"first": "John","Last": "Doe","Age": 140}' http://localhost:8181/
#Identity.Age: invalid value 140 (out of bound <130)… et, si vous avez un broker Kafka fonctionnant sur localhost:9092, il enverra le message sur le réseau :
❯ curl -XPOST -d'{"first": "John","Last": "Doe","Age": 40}' http://localhost:8181/
sent to the channel okDernière note sur les performances
Le code que nous avons généré n’est, évidemment, pas prêt pour la production ; néanmoins, le cœur est basé sur CUE, et nous pouvons légitimement nous demander s’il évoluera. CUE est conçu pour être O(n), et ce simple benchmark montre que le code peut ingérer, valider, encoder et envoyer des milliers d’événements dans un sujet Kafka local en 2,5 secondes :
> go test -run=NONE -bench=. -benchmem
goos: darwin
goarch: amd64
pkg: owulveryck.github.io/test1
cpu: Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
BenchmarkRun-12 1024 2135823 ns/op 55261 B/op 537 allocs/op
PASS
ok owulveryck.github.io/test1 2.503sConclusion
À travers cet article, nous avons construit un mécanisme complet de communication et de streaming pour interconnecter les nœuds d’un maillage.
Ce mécanisme de streaming fait partie d’une plateforme globale et sera exploité par une équipe de plateforme (comme défini par le livre team topologies de Matthew Skelton et Manuel Pais).
Les utilisateurs de cette capacité sont différentes équipes alignées sur le flux (dans le contexte des topologies d’équipe, une équipe alignée sur le flux est organisée autour du flux de travail et peut fournir de la valeur directement au client ou à l’utilisateur final)
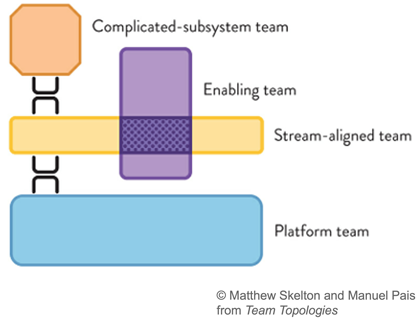
Au sein de l’équipe alignée sur le flux, le propriétaire du produit de données peut utiliser le langage CUE pour décrire sa sémantique et ses contraintes de données ; Les développeurs utiliseront le processus de validation pour alimenter le flux avec des données.
Les consommateurs de données exploiteront la capacité de catalogage des données et construiront d’autres produits grâce aux données qu’ils trouveront sur le réseau.
Pendant ce temps, le format Cloudevents garantit que le signal peut être propagé à travers l’infrastructure de manière agnostique. Il ouvre également la possibilité de construire des produits de données sur une architecture purement serverless, mais gardons cela au chaud pour un autre article.
Note finale : cet article présente une seule façon d’exposer des données via le streaming d’événements. Pour être complet, un mécanisme de “pull” devrait être défini comme standard pour récupérer l’information via, par exemple, un ensemble d’API REST.