350000 rows, 133 cols... From a huge CSV to DynamoDB (without breaking piggy-bank).
In this post I will explain how to:
- Parse a CSV file and extract only certain columns
- Create a table in DynamoDB
- Insert all the data with an adaptive algorithm in order to use the provisioned capacity
- Reduce the capacity once the insertion is done.
Exploring the problem: AWS Billing
In a previous post I explained how I was using dynamodb to store a lot of data about aws billing.
On top of the API that deals with products and offers, AWS can provide a “billing report”. Those reports are delivered to am Amazon S3 bucket in CSV format at least once a day.
The rows of the CSV are organized in topics as described in the AWS billing report documentation.
Each line of the CSV represents an item that is billed. But every resource is made of several billable items. For example on EC2, you pay the “compute”, the bandwidth, the volume etc…
I would like to use and understand this file to optimize the costs. A kind of BI.
AWS says that you can import your file in Excel (or alike)… That could be a solution but:

On top of that with a lot of resources the file is fat (more thant a 100000 lines several times a day for my client). I have decided to use dynamodb to store all the information so it will be easy to perform an extract and generate a dashboard. In this post, I will expose some go techniques I have used to achive that.
Step 1: Parsing the CSV
As I explained, the CSV file is made of more than a hundreds cols. The columns are identified in the first row of the CSV. I will store each row in a go struct.
To parse it easily, I an using custom fields csv in the struct. The field value corresponds to the header name for the seek value.
For example:
type test struct {
ID string `csv:"myid"`
Name string `csv:"prenom"`
Last string `csv:"nom"`
Test string `csv:"nonexitent"`
}Then, I am reading the first row of the CSV file and then ranging the field names of the struct to fill a map with the field key as key and the col number as value. I set ‘-1’ if the field is not found:
var headers = make(map[string]int, et.NumField())
for i := 0; i < et.NumField(); i++ {
headers[et.Field(i).Name] = func(element string, array []string) int {
for k, v := range array {
if v == element {
return k
}
}
return -1
}(et.Field(i).Tag.Get("csv"), header)
}Then I can parse the CSV file and fill a channel with one object by row… See the full example in this Gist
Step 2: Creating the table in DynamoDB
This step is “easy”. I will create a table with one index and a sort key.
For the example the index is a string named Key. The sort key is also a string named SortKey.
AttributeDefinitions: []*dynamodb.AttributeDefinition{
{
AttributeName: aws.String("Key"),
AttributeType: aws.String("S"),
},
{
AttributeName: aws.String("SortKey"),
AttributeType: aws.String("S"),
},
},
KeySchema: []*dynamodb.KeySchemaElement{
{
AttributeName: aws.String("Key"),
KeyType: aws.String("HASH"),
},
{
AttributeName: aws.String("SortKey"),
KeyType: aws.String("RANGE"),
},
},I will set an initial provisioning of 600. This would cost a lot of money but I will reduce it later to spare. The high provisioning rate is needed otherwise it would take me hours to integrate the CSV.
ProvisionedThroughput: &dynamodb.ProvisionedThroughput{
ReadCapacityUnits: aws.Int64(5),
WriteCapacityUnits: aws.Int64(300),
},The code for creating the table is in this DynamoDB Gist
Step 3: Inserting the data
The structure is read through the channel I have created previously.
The object is encoded to a dynamodb compatible one thanks the marshal function of this helper library github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute
To make the structure ID match the Key attribute of the table, I am using the dynamodbav fields.
type test struct {
ID string `csv:"myid" dynamodbav:"Key"`
Name string `csv:"prenom" dynamodbav:"SortKey"`
Last string `csv:"nom" dynamodbav:"Last,omitempty"`
Test string `csv:"nonexitent"`
}
...
for v := range c {
item, err := dynamodbattribute.MarshalMap(v)
params := &dynamodb.PutItemInput{
Item: item,
TableName: aws.String(tableName),
}
svc.PutItem(params)
}Going concurrent
I will add a touch of concurrency. I will use a maximum of 20 goroutines simultaneously to send items to the dynamodb. This is an empiric decision.
I am using a “guard” channel. This channel has a buffer of 20. The buffed is filled with am empty struct whenever an item is received in the main communication channel. I am then launching a gorouting that will insert the event into dynamodb and consume one event from the guard channel when done.
The guard channel is blocking when it is full. Therefore I am sure that 20 goroutines will run at maximum:
guard := make(chan struct{}, 20)
for v := range c {
guard <- struct{}{}
go func(v *test) {
item, err := dynamodbattribute.MarshalMap(v)
params := &dynamodb.PutItemInput{
Item: item,
TableName: aws.String(tableName),
}
svc.PutItem(params)
<-guard
}
}Using a backoff algorithm
The problem with this implementation is that it can overload the capacity.
Therefore the rejected event must be resent. Of course I can simply check for the error dynamodb.ErrCodeProvisionedThroughputExceededException an immediately resend the failed event.
But this may lead to dramatic performances. The AWS documentation point an Exponential Backoff algorithm as an advice to optimize the writing: Cf AWS documentation)
Wikipedia gives a good explanation of the exponential backoff but to make it simple the idea is to decrease the ration of insertion of the DB in order to get a good performance.
I am using a go implenenation found on github made by Cenkalti.
I return the error only in case of dynamodb.ErrCodeProvisionedThroughputExceededException by now:
backoff.Retry(func() error {
// Now put the item, discarding the result
_ , err = svcDB.PutItem(params)
if err != nil {
if err.(awserr.Error).Code() == dynamodb.ErrCodeProvisionedThroughputExceededException {
return err
}
// TODO: Special case...
log.Printf("Error inserting %v (%v)", v, err)
}
// Do the insert here
return nil
}, backoff.NewExponentialBackOff())Step 4: Updating the table and reducing the write capacity
Once the insert is done, to avoid a huge bill, I am reducing the Provisioned capacity of the table.
This is done with an update request:
params := &dynamodb.UpdateTableInput{
TableName: aws.String(tableName), // Required
ProvisionedThroughput: &dynamodb.ProvisionedThroughput{
ReadCapacityUnits: aws.Int64(10), // Required
WriteCapacityUnits: aws.Int64(1), // Required
},
}
resp, err := svc.UpdateTable(params)Conclusion: it works
It took me half an hour to process and insert 350000 lines (with 133 cols each) into the dynamodb from my laptop.
I can see that the adaptative algorithm works on the graphs:
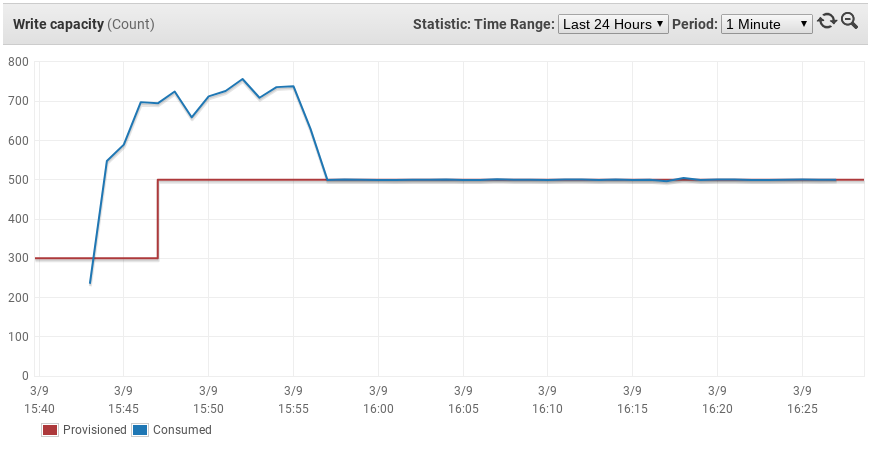
Now I can analyse the data to find a proper way to optimize the aws bill for my client.
The full example is on gist