A foot in NoSQL and a toe in big data
The more I work with AWS, the more I understand their models. This goes far beyond the technical principles of micro service. As an example I recently had an opportunity to dig a bit into the billing process. I had an explanation given by a colleague whose understanding was more advanced than mine. In his explanation, he mentioned this blog post: New price list API.
Understanding the model
By reading this post and this explanation, I understand that the offers are categorized in families (eg AmazonS3) and that an offer is composed of a set of products. Each product is characterized by its SKU’s reference (stock-keeping unit)
Inventory management
So finally, it is just about inventory management. In the retail, when you say “inventory management”, the IT usually replies with millions dollars ERP. And the more items we have, the more processing power we need and then more dollar are involved… and richer the IT specialists are (just kidding).
Moreover enhancing an item by adding some attributes can be painful and risky

The NoSQL approach
Due to the rise of the online shopping, inventory management must be real time. The stock inventory is a business service. and placing it in a micro service architecture bring constraints: the request should be satisfied in micro seconds.
More over, the key/value concept allows to store “anything” in a value. Therefore, you can store a list of attributes regardless of what the attributes are.
When it comes to NoSQL, there are usually two approaches to store the data:
- simple Key/Value;
- document-oriented.
At first I did and experiment with a simple key/value store called BoltDB (which is more or less like Redis). In this approach the value stored was a json representation… A kind of document. Then I though that it could be a good idea to use a more document oriented service: DynamoDB
Geek time
In this part I will explain how to get the data from AWS and to store them in the dynamoDB service. The code is written in GO and is just a proof of concept.
The product informations
A product’s technical representation is described in the AWS documentation. We have:
"Product Details": {
"sku": {
"sku":"The SKU of the product",
"productFamily":"The product family of the product",
"attributes": {
"attributeName":"attributeValue",
}
}
}There are three important entries but only two are mandatories:
- SKU: A unique code for a product.
- Product Family: The category for the type of product. For example, compute for Amazon EC2 or storage for Amazon S3.
- Attributes: A list of all of the product attributes.
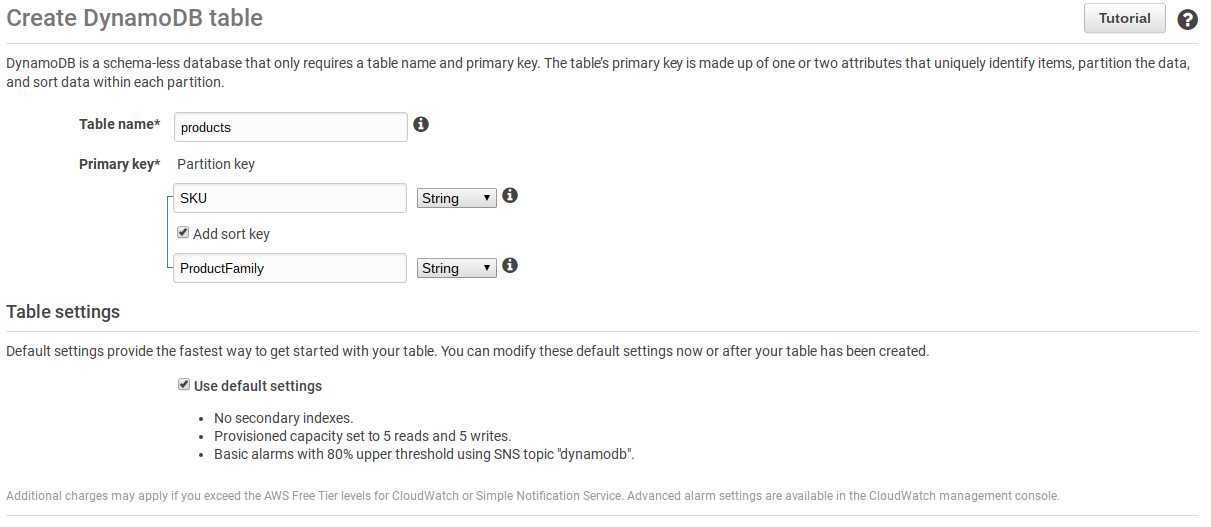
Creating the “table”
As my goal is for now to create a proof of concept and play with the data, I am creating the table manually. DynamoDB allows the creation of two indexes per table. So I create a table Products with two indexes:
- SKU
- ProductFamily
Principle
The data is retrieved by a simple http.Get method. Then a json.Decoder takes the body (an io.Reader) as argument and decode it in a predefined structure.
Once the structure is filled, I will store it in the DynamoDB.
The structures
I need three go structures. Two will be used to decode and range through the offer index. The other one will hold all the product details for a specific offer.
Offer Index
The offer index is composed of offers referenced in by an offer name (map[string]offer)
type offerIndex struct {
FormatVersion string `json:"formatVersion"`
Disclaimer string `json:"disclaimer"`
PublicationDate time.Time `json:"publicationDate"`
Offers map[string]offer `json:"offers"`
}An offer in the index is characterized by three elements. I am catching all of them, but only CurrrentVersionURL is useful in my case.
type offer struct {
OfferCode string `json:"offerCode:"`
VersionIndexURL string `json:"versionIndexUrl"`
CurrentVersionURL string `json:"currentVersionUrl"`
}Products
I hold all the product details in a structure. The product details holds all the products in a map whose key is the SKU. Therefore a SKU field is useless. The Attribute value is an interface{} because it can be of any type (more on this later in the post).
Note : In case of massive data flow, it would probably be better to decode the stream pieces by pieces (as written in the the go documentation)
type productDetails struct {
Products map[string]struct { // the key is SKU
ProductFamily string `json:"productFamily"`
Attributes map[string]interface{} `json:"attributes"`
} `json:"products"`
}Getting the data
Offers
The first action is to grab the json of the offer index and put it in a object of type offerIndex
resp, err := http.Get("https://pricing.us-east-1.amazonaws.com/offers/v1.0/aws/index.json")
var oi offerIndex
err = json.NewDecoder(resp.Body).Decode(&oi)
// oi contains all the offers
Then loop for each offer and do a GET of every CurrentVersionURL
for _ , o := range oi.Offers {
resp, err := http.Get("https://pricing.us-east-1.amazonaws.com" + o.CurrentVersionURL)And products
The same principles applies for the products, we decode the stream in an object:
var pd productDetails
err = json.NewDecoder(resp.Body).Decode(&pd)Now that we have all the informations we are ready to store them in the database.
Storing the informations
As usual with any AWS access, you need to create a session and a service object:
sess, err := session.NewSession()
svc := dynamodb.New(sess)The session will take care of the credentials by reading the appropriate files or environment variables.
the svc object is used to interact with the DynamoDB service. To store an object we will use the method PutItem which takes as argument a reference to PutItemInput.
Note All of the AWS service have the same logic and work the same way: Action takes as a parameter a reference to a type ActionInput and returns a type ActionOutput.
Let’s see how to create a PutItemInput element from a Product type.
the Dynamodb Item
The two mandatory fields I will use for the PutItemInput are:
TableName(which is Product in my case)Item(which obviously hold what to store)
Other fields exists, but to be honest, I don’t know whether I need them by now.
The Item expects a map whose key is the field name (In our case it can be “SKU”, “ProductFamily” or anything) and whose value is a reference to the special type AttributeValue.
From the documentation the definition is:
AttributeValue Represents the data for an attribute. You can set one, and only one, of the elements.
The AttributeValue is typed (The types are described in the DynamoDB API reference)
Therefore our informations (remember the map[string]inteface{}) must be “convrted” to a dynamodb format.
This task has been made easy by using the package dynamodbattribute which does it for us:
To fill the item I need to loop for every product in the object pd and create an item:
for k, v := range pd.Products {
item["SKU"], err = dynamodbattribute.Marshal(k)
item["ProductFamily"], err = dynamodbattribute.Marshal(v.ProductFamily)
item["Attributes"], err = dynamodbattribute.Marshal(v.Attributes)Once I have an Item, I can create the parameters and send the request to the DB:
Item: item,
TableName: aws.String(config.TableName),
}
// Now put the item, discarding the result
_ , err = svc.PutItem(params)Execution and conclusion
Once compiled I can run the program that will take a couple of minute to execute (it can easily be optimized simply by processing each offer in a separate goroutine).
Then I can find the informations in my DB:
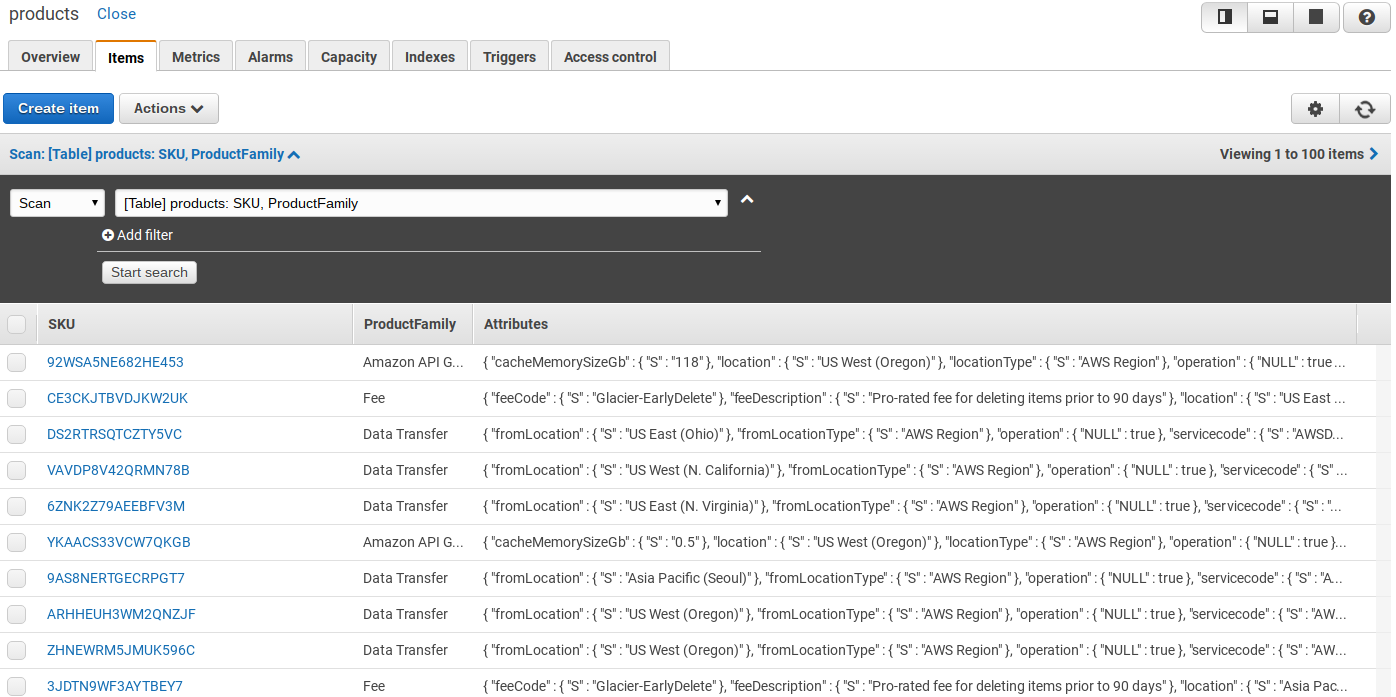
Now that I have the informations, on the same principle I can grab the prices and put a little web service in front of it. And I could even code a little fronted for the service.
I am aware that if you are not an average go programmer the code may seem tricky, but I can assure you that it is not (the whole example is less than 100 lines long including the comments). The AWS API seems strange and not idiomatic, but it has the huge advantage to be efficient and coherent.
Regarding the inventory model. it can be used for any product or even any stock and prices. It is a cheap (and yet efficient) way to manage an inventory.
Full code
The full code of the example can be found on my gist