Configuration management, choreography and self-aware applications
Thanks to the company I’m working for (Techsys) I’ve had the opportunity to attend the configuration management camp in Gent (be) for its 2016 edition.
I really enjoyed those two days of talks, watching people present different ideas of a possible future for the infrastructure and deployment engineering. Beyond the technical demonstrations and the experience sharing, I’ve spotted a bunch of ideas
Among all, those that comes to me spontaneously are:
You don’t need configuration management, what you need is a description of the topology of your application - Mark Shuttleworth in its keynote The magic of modeling
You don’t need orchestration, what you need is choreography - Exposed by Julian Dunn (you can find a transcription here on youtube)
What we need is a new way to do configuration management - James Shubin, see his blog post which ispired my project khoreia
I came back home very excited about this. This post tries to expose my reflection and how I’ve implemented an idea (see it as a POC) I’ve passed some time to learn about TOSCA, and the to code an orchestrator.
In a first part I will expose why, according to me, the topological description of the application may be what company needs.
Therefore, I will notice the need for orchestration tools.
Even if the concepts remains actuals, the future may be an evolution of this mechanism of central command and control. In the last part of this post, I will expose what I’ve understood of the concept of choreography so far.
Finally I will demonstrate the idea with a POC based on a development on the etcd product from CoreOS.
(and a youtube demo for those who don’t want to git clone...)
Configuration management and orchestration
Configuration management has been for a long time, a goal for IT automation. Years ago, it allowed system engineers to control a huge park of machines while maintaining a TCO at a relatively decent level.
Over the last decade, 4 major tools have emerged and are now part of most CTO common vocabulary.
Let’s take a look at the trends from 4 major tools categorized as “configuration management tools”:
| Tool | Founded in |
|---|---|
| Ansible | 2012 |
| Puppet | 2005 |
| Chef | 2009 |
| Salt | 2011 |
Note: I do not represent CFEngine because it is doesn’t seem not so widely used in dotcom companies (even if it seems to be a great tool and on a certain extent the father of the others)
The “interest” for those tools as seen by Google is be represented like this:
As we can see, Ansible seems to be the emerging technology. Indeed its acquisition by redhat in late 2015 may have boosted a bit the trends, but anyway, the companies that do not implement infrastructure as code may seem to prefer this tool. Cause or consequence, Gartner has nominated Ansible as a cool vendor for 2015 (according to Gartner, a Cool Vendor is an emerging and innovative vendor that has original, interesting, and unique technology with real market impact)
Why did a newcomer such as Ansible did present such interest?
Beside its simplicity, Ansible is not exactly a configuration management tool, it is an orchestrator (see the Ansible webpage)
According to Rogger’s theory about the diffusion of innovation, and regarding the trends, I think that it is accurate to say that the position of Ansible is near the “late majority”
What does this mean ?
To me,it means that people do feel the need for orchestration, or if they don’t feel it, they will thanks to Ansible. Via orchestration, they may feel the need for representing their product.
We are now talking about infrastructure as data; soon we will talk about architecture as data
From system configuration management…
I did system administration and engineering for years. Configuration management was the answer to the growing of the infrastructure. Config management allowed us to
- Get the systems reliable
- Get the best efficiency possible from the infrastructure
- Maintain a low TCO …
It was all “system centric”, so the application could be deposed and run in best conditions.
… to application’s full description
A couple of years ago, maybe because of the DevOps movement, my missions were getting more and more application centric (which is good). Actually infrastructure has not been considered as a needed cost anymore.
Thanks to Agility, DevOps, and the emergent notion of product (as opposed to project), Application and infrastructure are now seen as a whole.
(I’m talking of the application “born in the data center”, it is different for those “born in the cloud”)
Therefore, the setup of the application must not rely only on programmed configuration management tools anymore, but on its complete representation
The self-sufficient application
Some times ago, I wrote article published on pulse because I wanted to lay down on paper what I thought about the future of application deployment. I’ve described some layers of the application. I kept on studying, and with a some help from my colleagues and friends, I’ve finally been able to put a word on those ideas I had in mind.
This word is Topology
and then came TOSCA
To describe a whole application, I needed a domain specific language (DSL). All of the languages I was trying to document were by far too system centric. Then I discovered TOSCA. TOSCA is THE DSL for representing the topology of an application.
Pros…
What’s good about Tosca is its goal:
It describes a standard for representing a cloud application. It is written by the Oasis consortium and therefore most of the big brand in IT may be aware of its existence. The promise is that if you describe any application with Tosca, it could be deployed on any platform, with a decent orchestrator.
…and cons
But… Tosca is complex. It’s not that simple to write a Tosca representation. The standard wants to cover all the possible cases, and according Pareto’s law, I can say that 80% of the customers will only need 20% of the standard.
On top of that, Tosca is young (by now, the YAML version is still in pre-release), and I could not find any decent tool to orchestrate and deploy an application. Big companies claim their compliance with the standard, but actually very few of them (if any) does really implement it.
Let’s come back to orchestration (and real world)
As seen before, a Tosca file would need a tool to transform it to a real application. This tool is an orchestrator.
The tool should be called conductor, because what is does actually is to conduct the symphony, and yet in our context the symphony is not represented by the topology, but by its ‘score’: its execution plan, and the purpose of the ‘orchestrator’ is to make every node to play its part so the application symphony could be rendered in best condition of reliability and efficiency…
Wait, that was the promise of the configuration management tools, isn’t it?
The execution plan
So what is the execution plan. An execution plan is a program. It describes exactly what needs to be done by systems. The execution plan is deterministic.
With the description of the application, the execution plan, and the orchestration, the ultimate goal of automation seems fulfilled, indeed! We have a complete suite of tools that allows to describe the application and architecture base on its functions and it is possible to generate and executes all the commands a computer must do to get things done.
Why do we need more? Because now systems are so complex that we could not rely anymore on IT infrastructure to do exactly what we told it to. Mark Burgess, considered by a lot of people as a visionary, wrote a book entitled: In Search of Certainty: The science of our information infrastructure
Julian Dunn told about it in its speech, and I’ve started reading IT.
The conclusion is roughly:
We may not rely on command and control anymore, we should make the system work on its own to reach a level of stability
Dancing, Choreography, Jazz ?
A solution to the orchestration SPOF and a workaround for dealing with the uncertainty of the infrastructure may be to implement a choreography. Or to replace the symphony with a piece of jazz. You give every attendee (dancer, jazzman or TOSCA node) the structure of the piece to play. And given the chords and the structure, they all react and do what they have committed to do.
This should produce similar to the same mechanism controlled by an orchestrator, but more fault tolerant. Actually, the brain will not have to take care of unpredicted event; each node will do so. The application has become self-aware.
Implementation: a distributed system
This concept, described in so many sci-fi books, may become applicable because science formalized consensus algorithm such as paxo or raft. And even better, it is easy to find very good implementation of those concepts (for free)
etcd from CoreOS is one of those tools.
It is a service oriented key/value store, distributed on a cluster of machine.
It can be used as a communication based for a cluster of nodes composing a choreography.
Even more, etcd clients have the ability to monitor an event allowing us to implement the self awareness of the application.
Proof of concept: khoreia
khoreia is a little program I made in go that relies on the etcd distributed system.
Etcd itself is an implementation of the raft consensus algorithm. I do heavily advice that you take a look at this page
for a complete and clear explanation.
The khoreia single binary takes a topology description in yaml (by now very simple, but sooner or later I may implement the TOSCA DSL, as I already have a Tosca library).
Then it triggers the nodes and every node reacts on events. Regarding the events, it implements the expected life cycle for the node.
Without actually coding it, the complement life cycle of the application is then applied. Even better, the application is fault tolerant (if a check fails, the do method is called again) and the execution is completely stateless because of the event based mechanism.
Screencast: a little demo on distributed systems based on event on filesystems
Here is a little screencast I made as a POC. Two machines are used (linked by a VPN):
- my chromebook, linux-based at home in France;
- a FreeBSD server located in Canada.
Both machines are part of an etcd cluster.
The topology is composed of 8 nodes with dependencies which can be represented like this (same example as the one I used in a previous post):
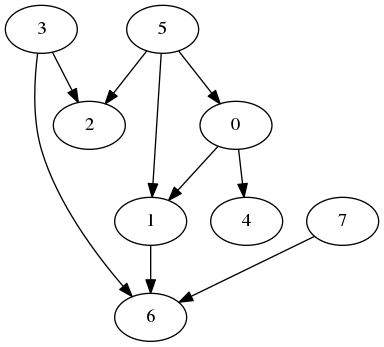
Nodes 0-3 are targeted on the chromebook while nodes 5-7 are targeted on the BSD machine.
The topology is described as a simple yaml file in the khoreia repository
Each node is fulfilling two methods:
- Create
- Configure
And each method is implementing an interface composed of:
Check()which check whether the action has been release and the “role” is okDo()which actually implements the action
Note: The signature of the method is actually a bit different, and the go implementation involve channels, but I does not change the principle, so I’ve decided to omit that for clarity.
Example
Each node will:
- Wait for an event and call Create.Check() and Configure.Check().
- watch for events from their dependencies
- if an event is detected, call the appropriate Do() method
Engine
The interfaces Check() and Do() may be implemented on different engines.
For my demo, as suggested by James I’m using a “file engine” base on iNotify (linux) and kQueue (freebsd).
The Check() method is watching the presence of a file. It sends the event “true” if the file is created of “false” if its deleted.
The Do() method actually create an empty file.
Khoreia on github:
Conclusion
Self-awareness, self-healing, elasticity, modularity, … with a choreography based configuration and deployment tools, standard application may get new capabilities without totally rethinking their infrastructure.
Some of the stuff that still need to be implemented are, for example, the notion of interface and commitment of the node, and the notion of machine learning for every node to teach them how to react to different events in an efficient way.